- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- A generic tool or model to write and combine the v...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
A generic tool or model to write and combine the values of multiple fields on one other field
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi All,
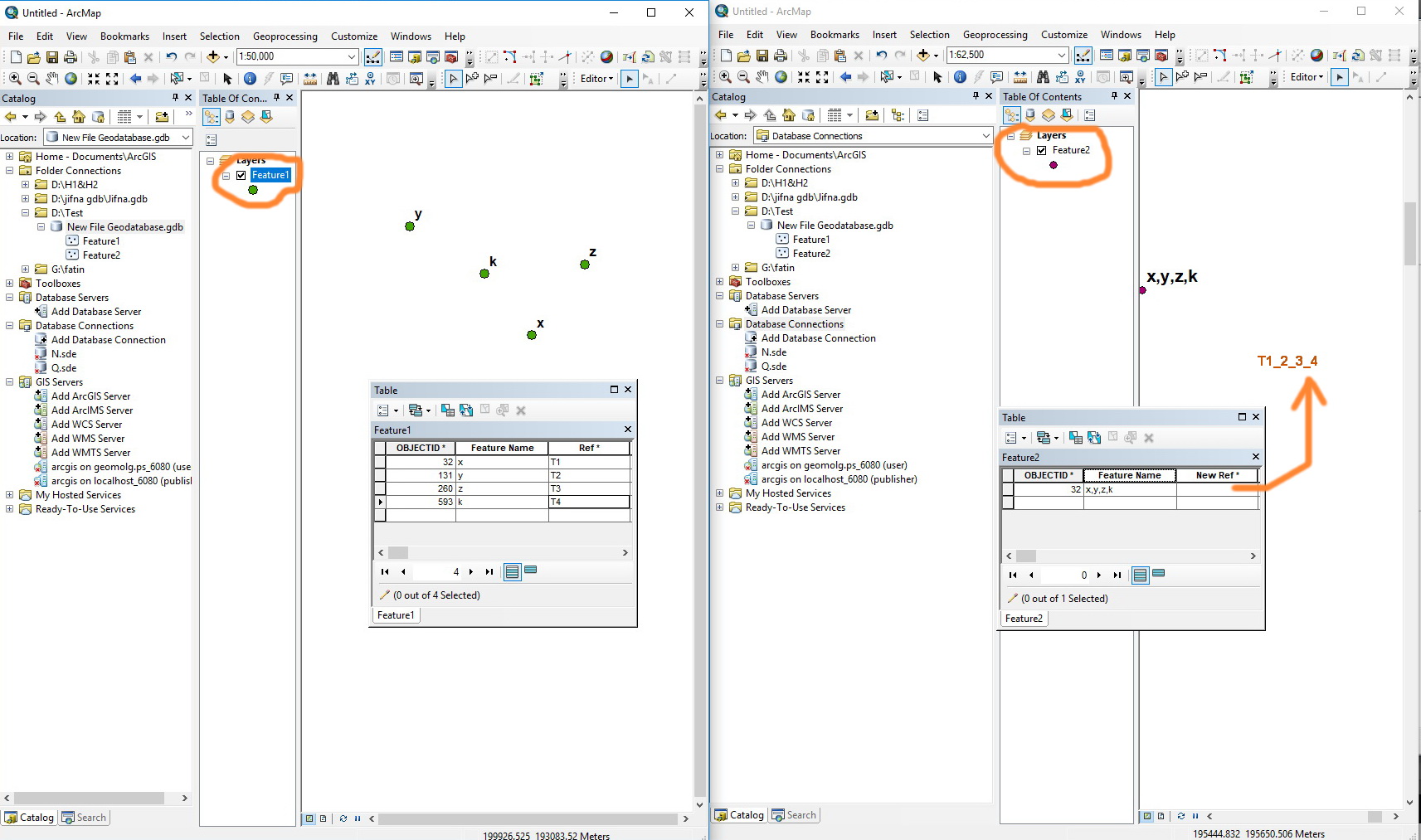
I have 2 feature classes which have attribute tables as following:
Feature 1:
X | T1 |
Y | T2 |
Z | T3 |
K | T4 |
Feature 2:
X, Y, Z, K | ??? |
I am wondering if there is a methodology or tool that can help me in combining many fields and the result can be written in a new field as following:
X, Y, Z, K | T1,2,3,4 |
Kindly notice the following screenshot too.
Thank you in Advance
Fatin Rimawi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
My previous code was to see if I understood your project. Table1 would be replaced by using a search cursor, and to save your data, instead of using table2 you would use an insert cursor. From your examples, it looks like you may want to use an update cursor. This would assume that at least one city (or one city code) is in each row of your second feature.
The following code might serve as a starting point. It may need some tweaking or error checking code added depending upon the rules you are actually using. Richard Fairhurst has made a number of good suggestions for you to consider.
import arcpy
import itertools
# empty dictionaries
myCodes = {}
myCities = {}
fields = ['fName', 'Ref'] # assumes same field names in both features
fc1 = r'C:\Path\To\Test.gdb\Feature1'
fc2 = r'C:\Path\To\Test.gdb\Feature2'
for row in arcpy.da.SearchCursor(fc1,fields):
# codes dictionary { governorate: [ city: numberCode ... ] }
item = ["".join(x) for _, x in itertools.groupby(str(row[1]), key=str.isdigit)]
if item[0] in myCodes:
myCodes[item[0]].append({row[0] : item[1]})
else:
myCodes[item[0]] = [{row[0] : item[1]}]
# cities dictionary { city: governorate }
if row[0] not in myCities:
myCities[row[0]] = item[0]
# print myCodes
# print myCities
with arcpy.da.UpdateCursor(fc2, fields) as rows:
for row in rows:
# find a city match in row[0]
cities = row[0].split(',')
found = [i for i in cities if i in myCities.keys()]
city = []
cityCode = []
for lst in myCodes[myCities[found[0]]]:
for k2, v2 in lst.iteritems():
city.append(k2)
cityCode.append(v2)
row[0] = ",".join(city)
row[1] = myCities[found[0]]+"_".join(cityCode)
rows.updateRow(row)
print "Done."
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Randy,
Could you please notice the bellow 2 screenshots?

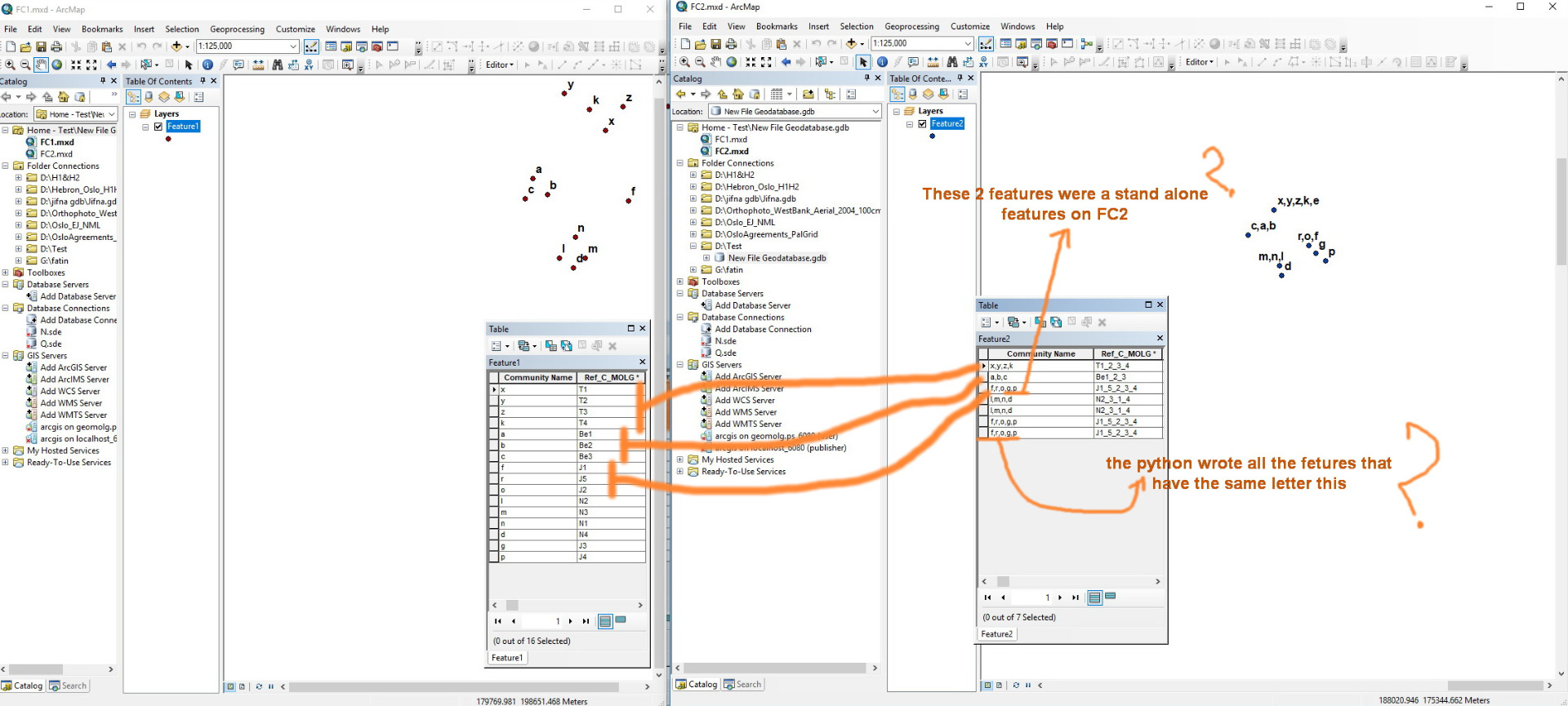
It seems that the python concatenate all the values that have the same ref. However, some values should be considered as a stand alone point,even though it is have the same letter in the Ref.
The Ref= Governarate abbreviation_number of community in this geovernarate.
The point here is concatenate the values in FC2 with FC1, but with a condition:
The communities that don't have any concatenate with other community, it's Ref should stay as it. no need to merge it with other values.
What do you think?
Best,
Fatin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here is another version. It does not change the community names in feature2. It does update the reference code using the community names found in feature1. It will probably error out if there is a community name in feature2 that is not found in feature1.
import arcpy
import itertools
# empty dictionary
citydict = {}
fields = ['fName', 'Ref']
fc1 = r'C:\Path\To\Test.gdb\Feature1'
fc2 = r'C:\Path\To\Test.gdb\Feature2'
# read fc1 fields into a dictionary { city: governorateCode }
citydict = {f[0]:f[1] for f in arcpy.da.SearchCursor(fc1,fields)}
# update governorate code in fc2 - no new cities are added to fc2
with arcpy.da.UpdateCursor(fc2, fields) as rows:
for row in rows:
cities = row[0].split(',') # split cities into a list
# search citydict to find matching governorate code
# note that cities not found in citydict will not have an associated code
# may error out if there is no city that links to citydict
found = [i for i in cities if i in citydict.keys()]
cityCode = []
for idx, val in enumerate(found):
city = ["".join(x) for _, x in itertools.groupby(str(citydict[val]), key=str.isdigit)]
if idx == 0:
codePrefix = city[0]
cityCode.append(city[1])
# note that the data in row[0] (city list) is not changed
row[1] = codePrefix+"_".join(cityCode)
rows.updateRow(row)
print "Done."If you are adding new communities to feature1, you will probably want a way to insert them into feature2. This script will not add new communities.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is exactly what we need.
Many thanks for you Randy 
Best,
Fatin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
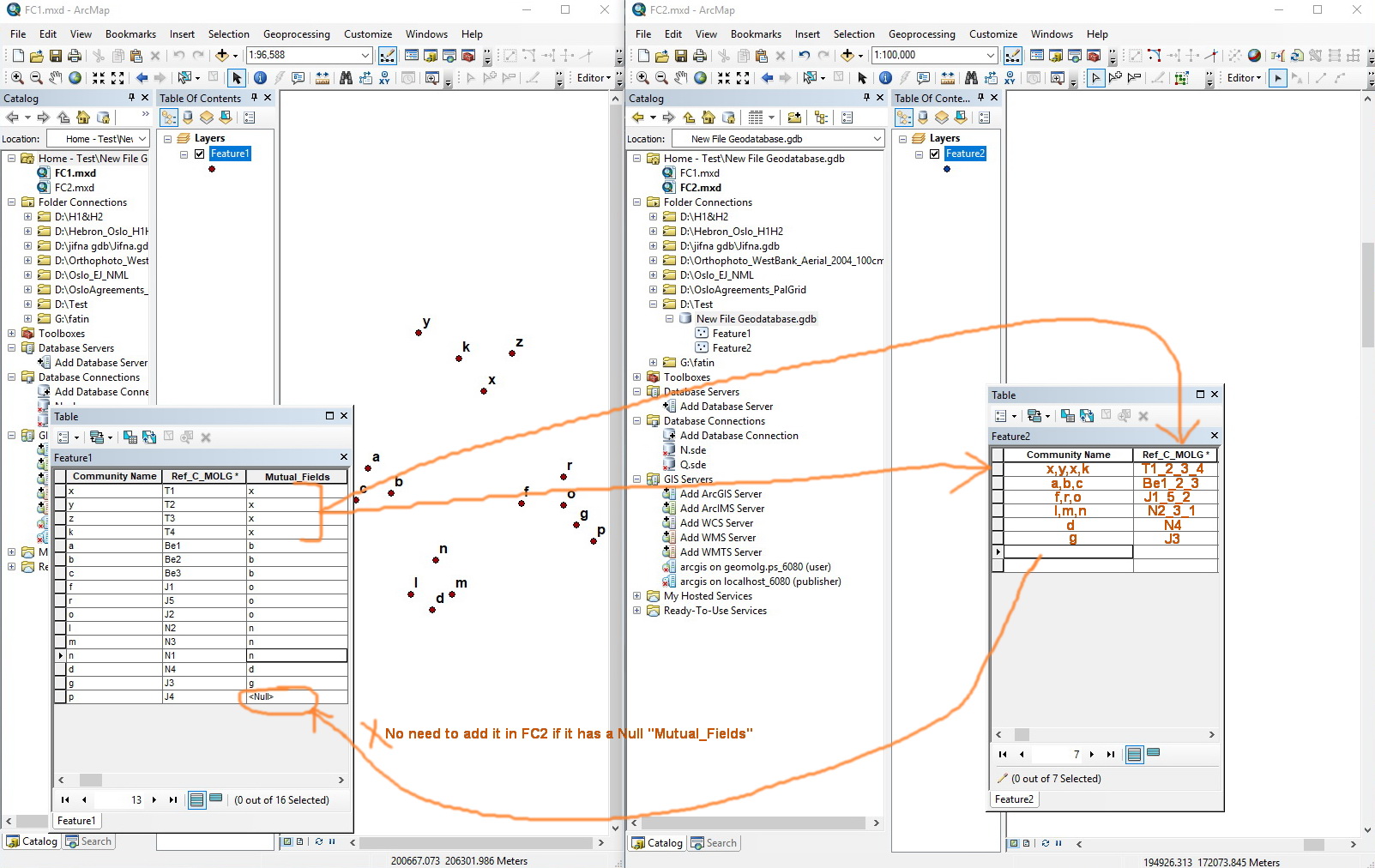
In addition to the previous conditions, Is it possible to reduce the work of data entry person by using new field that can connect and concatenate all features?
This can reduce the percentage of error. Am I right?
Kindly notice the following the screenshot to clarify my point.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Fatin:
You are failing to exploit any relational database capabilities with your set up. Why not write the Community Name of FC2 into the Mutual field of FC1 instead of a random portion of it? If the Mutual Field of FC1 has the same value as the Community Name field of FC2 you can use joins and relates, which would make your data much more useful than anything you have done so far. Also the code has found the connection between the Community Name of FC1 and the Community Name of FC2 already and writing the Community Name of FC2 to the Mutual Field of FC1 is easily done and far more useful than the non-relational data you keep wanting to create. If a data relationship exists between two tables it is far better to create a value in the tables that explicitly establishes a primary key and foreign key link than to hide it through an implicit relationship that is only visible through python code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
The mutual field “community name” is the place that the other communities come to do elections, so this field could be filled with portion value.
For example, (x,y,z,k) has a mutual community which is “x”, so one should conclude that x is the community that y, z, and k doing their election there.
At the beginning, my idea was as same as yours, but after showing the results to my team, they suggested to concatenate the values from one FC to another. This can reduce the data entry works and the errors.
It is much easier to audit one FC than auditing many FCs.
Best,
Fatin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You need to create a real data relationship, otherwise you won't ever understand how to solve your own problems. Randy Burton and I can create scripts that can handle your request because we understand how data relationships work. It is at the foundation of everything our scripts are doing. So before you ask for a script that populates a Mutual field (and then continue to ask for more fields as your problem continues to evolve) create a new field for the key and foreign key relationship between your tables and find out how joins and relates apply to your problem.
If you set up a standard data relationship you can manually do what the script is doing and validate your work even better than any script will. A script will not catch data entry errors as Blake has said, but joins and relates combined with your domain knowledge will expose them.
I deal with million+ records to million+ record matching and updates daily through a script, but I would never think of completely abandoning a real data relationship that supports joins and relates for a purely script based solution. I am currently validating 600,000 records covering 20 years of data entry using standard joins and relates. In half an hour I was able to identify a class of outdated and/or erroneous references affecting 50,000 records and correct them with a simple field calculation using joins and relates. Other errors require more research, but the joins and relates make it easy to identify and isolate the small number of affected records that require that research from the million+ records, because I understand the joins and relates I have established.
There are too many complexities, human errors, and tracking issues with dynamic land data to rely only on a script, especially when human made boundaries are involved that are subject to continuous change due to subdivisions, property ownership transfers and political reasons. I simply cannot stress the importance enough of learning the fundamentals of Joins and Relates as they apply to your problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here is another version that may give you some additional ideas. It populates an empty feature2, but you could add code to create an empty feature. I think it is simpler and probably more accurate to populate an empty feature.
It groups on your "Mutual" field and ignores rows where the value is null. The "Mutual" field is also carried over to feature2, so it could be used for a label. Or the concatenated community names can be the label.
An ordered dictionary is used so you can have the communities listed in order, or you can have the codes in order (see photo). By uncommenting/commenting some lines in the code you have the option to use a regular dictionary and omit the order by sql.
The x,y point of the community in the "Mutual" field is used, although if desired, it can average the x,y coordinates and produce a point somewhere near the center of the group of points of the joined communities.
Richard Fairhurst has given some good ideas regarding data rules, etc. For my part I have not provided any error checking should the data have issues.
import arcpy
import itertools
from collections import OrderedDict as OD
mapData = OD([]) # empty ordered dictionary for cities and codes
# you can also use a regular dictionary if sort order is not an issue
# mapData = {} # empty dictionary
fields = ['Community', 'Ref_C_MOLG', 'Mutual', 'SHAPE@XY' ]
fc1 = r'C:\Path\To\Test.gdb\Feature1'
fc2 = r'C:\Path\To\Test.gdb\Feature2'
# read fc1 : an ordered dictionary and sql order by may be of interest
# for row in arcpy.da.SearchCursor(fc1,fields): # if using a regular dictionary and not using order by
# for row in arcpy.da.SearchCursor(fc1,fields,sql_clause=(None,"ORDER BY Ref_C_MOLG")): # to order by Code
for row in arcpy.da.SearchCursor(fc1,fields,sql_clause=(None,"ORDER BY Community")): # to order by Community
if row[2] is not None: # Mutual (for grouping) : ignore rows where this field is null
# mapData { governorate_mutual: [ 'city': 'cityname', 'code': 'numberCode', 'xy': (0.0, 0.0) ] }
item = ["".join(x) for _, x in itertools.groupby(str(row[1]), key=str.isdigit)]
dKey = "{}_{}".format(item[0],row[2])
if dKey in mapData:
mapData[dKey].append({'city': row[0], 'code': item[1], 'xy' : row[3] })
else:
mapData[dKey] = [{'city': row[0], 'code': item[1], 'xy' : row[3] }]
# insert cursor for "empty" fc2
cursor = arcpy.da.InsertCursor(fc2, fields)
for k1, v1 in mapData.iteritems():
city = []
cityCode = []
cityXY =[] # for averaging x,y option
for lst in v1:
city.append(lst['city'])
cityCode.append(lst['code'])
# if averaging x,y for new point
# cityXY.append(lst['xy'])
# if using city in Mutual field
if k1.split('_')[1] == lst['city']:
newXY = lst['xy']
# if averaging x,y for new point
# newXY = [sum(x) / len(x) for x in zip(*cityXY)]
# cursor.insertRow(( ", ".join(city), k1.split('_')[0]+"_".join(cityCode), k1.split('_')[1], tuple(newXY) ))
# if using city in Mutual field
cursor.insertRow(( ", ".join(city), k1.split('_')[0]+"_".join(cityCode), k1.split('_')[1], newXY ))
del cursor
print "Done."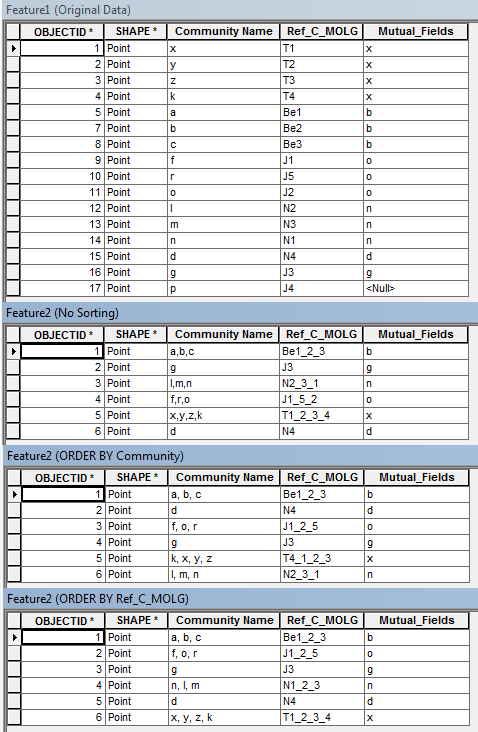
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you Randy. Why not to locate the produced Feature class where the mutual field is located?
For example, if we have "x" as a mutual value for the set: (x,y,z,k), the new feature should be produced as same as the location of "x" in FC1.
Best,
Fatin