- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- A generic tool or model to write and combine the v...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
A generic tool or model to write and combine the values of multiple fields on one other field
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi All,
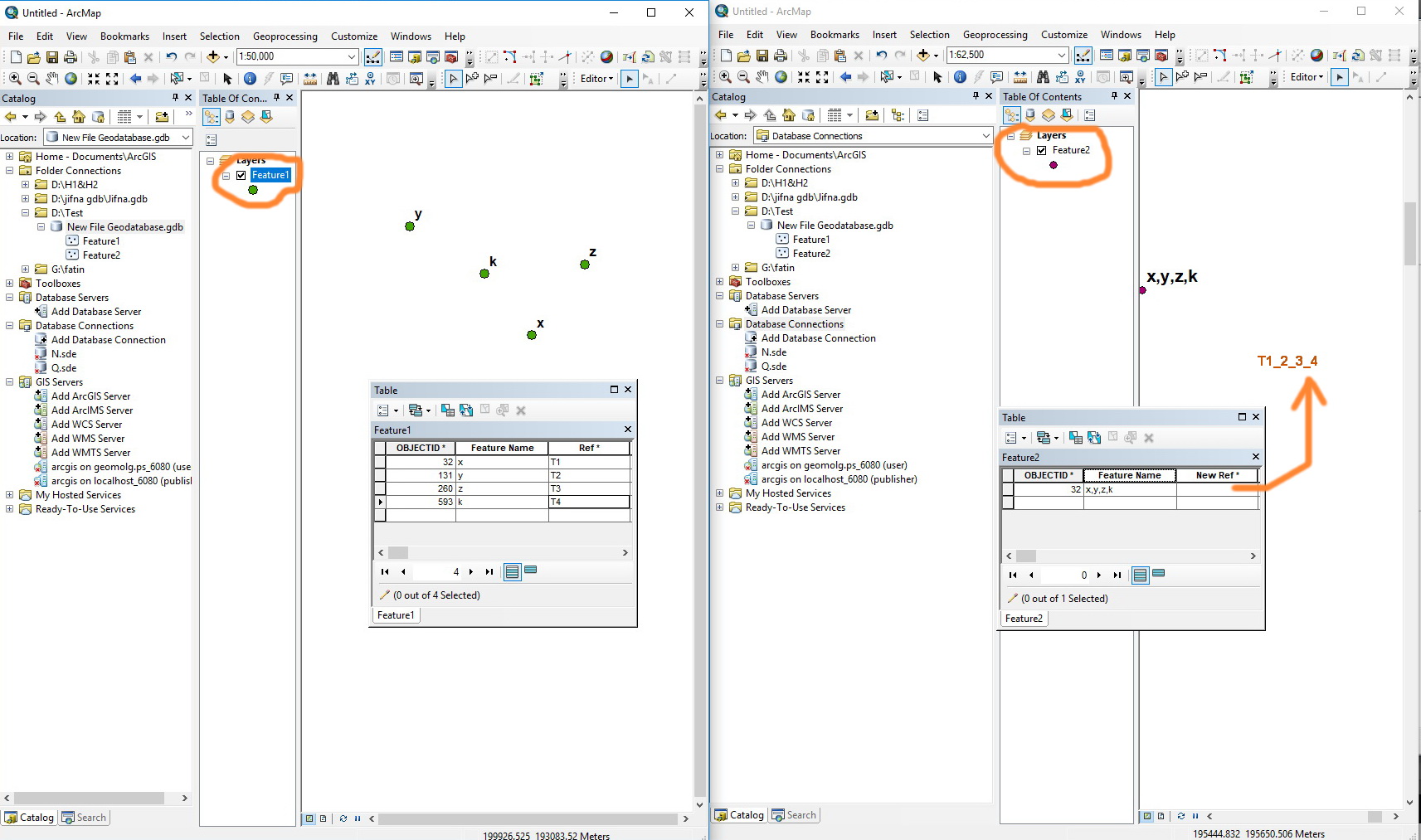
I have 2 feature classes which have attribute tables as following:
Feature 1:
X | T1 |
Y | T2 |
Z | T3 |
K | T4 |
Feature 2:
X, Y, Z, K | ??? |
I am wondering if there is a methodology or tool that can help me in combining many fields and the result can be written in a new field as following:
X, Y, Z, K | T1,2,3,4 |
Kindly notice the following screenshot too.
Thank you in Advance
Fatin Rimawi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There is nothing generic about what you want to do, as this request has no obvious basis in standard relational database manipulations. It requires a completely custom solution that will only apply to your data and thought process. It can be done, but you would have to elaborate on the rules and the full nature of your data to get a solution that works for more than this one example, since a manual solution would be my recommendation if this example was your actual complete data set.
There are several problems that have to be solved or rules that have to be understood.
1. There is no reason to assume that the features in FC1 are ordered in the sequence required to directly match FC2 as they are read, so the solution must overcome disorder in FC1.
2. Are the features in FC1 uniquely related to just one feature in FC2, or can the value in column one for any single feature in FC1 be found in the list of columns for more than one feature of FC2?
3. Are there two or more features in FC1 that have identical values in column 1? If so, how do you want them matched to FC2?
4, Is the list of columns in FC2 always alphabetically ordered according to alphabetic sorting rules?
5. Do you really need the letter stripped off after the first position in the list in column 2 of the output of FC2, or is "T1,T2,T3,T4" an acceptable output for FC2 column 2?
6. Is there always only one letter that is always "T" at the beginning of each value in column two of FC1 that has to be stripped off if it falls after the first position in the list of column 2 in FC2? Or are there other letters at the beginning of the values in FC1 column 2 that need to be retained if they differ from the item that precedes it in the FC2 column 2 list?
7. Is there a spatial join component to the problem where the features that are matched have to be in some proximity of each other in FC1 and FC2 before the column one values are related?
Other issues may become apparent as you explain your data and the rules governing a solution more fully.
In general, the solution will be through a python script that uses cursors and dictionaries or lists to read and manipulate the data from FC1 prior to being outputted to FC2. But the order of operations depends a lot on how you answer the questions above and any others that come up as you give more details on your problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
Thank you for the previous reply.
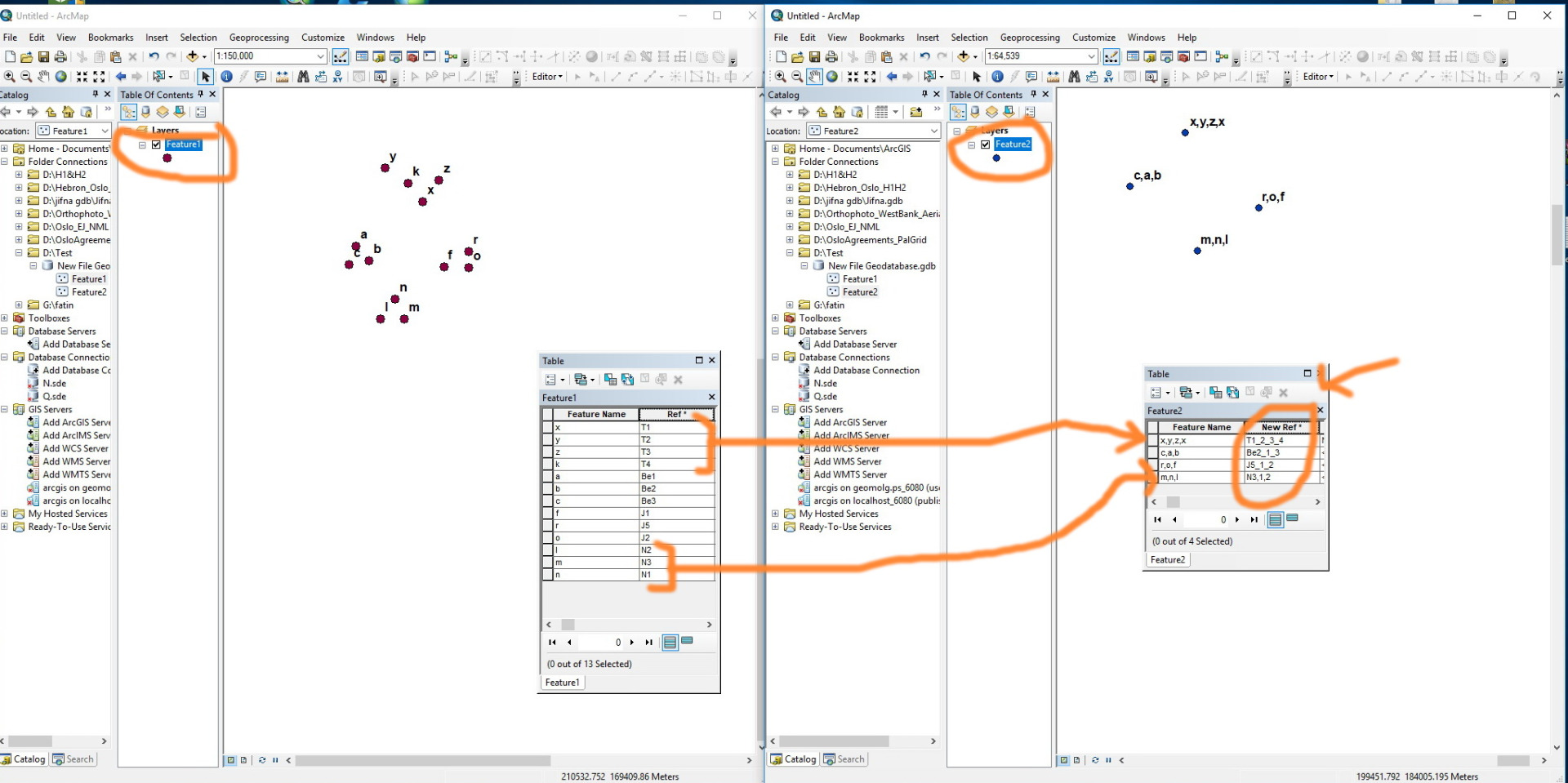
To answer your questions please notice the following:
- The previous example was a set of imaginary data that was used for simplification purposes.
- In FC1 values (x,y,z…etc) presents the communities names, and each community has its unique name which must not to be repeated in FC1.
- The Ref values are unique for each community (only x has a ref=T1).
- The value in the REF field, T1 for example, presents the abbreviation of name of governorate, and the number 1 is referred to the community in this governorate.
- Each governorate has its unique abbreviation (Tulkarm: T, Bethlehem: Be…etc))
- For example, features in FC2 (x,y,z) must be related uniquely, so z is only related to (x,y) and it can not related to other values.
- (x,y,z) must have the same Ref letter.
- The aphanitic order for (x,y,z,k) is not obligated, it is just as the data entry entered it on the attribute table.
Please let me if this description is sufficient.
Kindly notice the following screenshot. I added more values to clarify my point.
Thank you in Advance
Fatin Rimawi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You explanation of what is going on is helpful, but the details you are now giving raises some other questions.
1. Are the real value in the Feature Name field going to be multi-letter actual community names? For example would the actual values expressed as a,b for example in reality be real community names like Tulkarm,Bethlehem? If so, will the community names sometimes consist of multiple words, like Los Angeles? Knowing the true nature of the real data the program will be working with is crucial to writing the most efficient and error free code for parsing and concatenating your real data values. There can be a vast difference in the coding approach I might use when the data only consists in single character values verses when the data consists in multi-character values.
2 Is there a significant potential for a lot of misspellings in the values in the Feature Name field in FC1 or in FC2 or both? If the answer to question 1 is that the values are multi-character values that have specific spellings, there is a greater likelihood that a programmatic solution may not work for a large portion of your data. Minor spelling variations or inconsistent use of abbreviations between the two FCs can render programs like this useless, just like they can render a standard Join or Relate useless. Also, does the program have to account for possible variations in how community names are capitalized?
3. How many data points exist in FC1 and how many points exist in FC2 in your real data? Automated solutions may not be worth the effort if the data set is relatively small.
4. Will this be a one time thing or will this process need to be regularly repeated because of changes in the number of points or value changes in the Ref field? Automated solutions may not be worth it you only need to do this one time or extremely rarely.
5. Are the abbreviations of the governorates in the REF field ever more than 2 characters? What is the largest number of characters used as a governorate abbreviation? Are the numbers at the end of every Ref value always just a single digit or can the numeric part of the REF ever be made up of 2 or more digits? Knowing these things affects the parsing and concatenation processes I would use.
6. Are the New REF values always limited to a single governorate and always limited to a single abbreviation prefix in the list? If this is the rule, is there any chance that an invalid value exists that violates that rule by mistake?
Bottom line is that understanding the true nature of the data and its quality, consistency and level of validation prior to running any code can be critical to the structure and design of a program and the level of error handling that has to be incorporated when you write a program that is going to have to do this much parsing and concatenating of data to match the data up correctly. The violation of even one rule that is assumed can end up requiring the program to undergo substantial restructuring and can force the development of a variety of new subroutines, which can add a lot of debug time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
I really appreciate your reply.
Here are the answers for your qualified questions:
- The communities name could consist multiple letters like “East Jerusalem”., and one work like “Bethlehem”.
- Well, we are working on unifying the values in our database, and we are auditing the data if anything is wrong. However, the chance in getting misspelling word can present.
- The amount of data is relatively huge. We are having around 1050 values on the first layer, and around 470 on the second one.
- We need to automated this process every week or every 2 weeks, depending on the progress in unifying the data.
- The maximum number for each abbreviation is two like “East Jerusalem: EJ, Tubas: Tu, and Jenin: J”
- The number of digits in the abbreviation itself could be more than 2 digits.
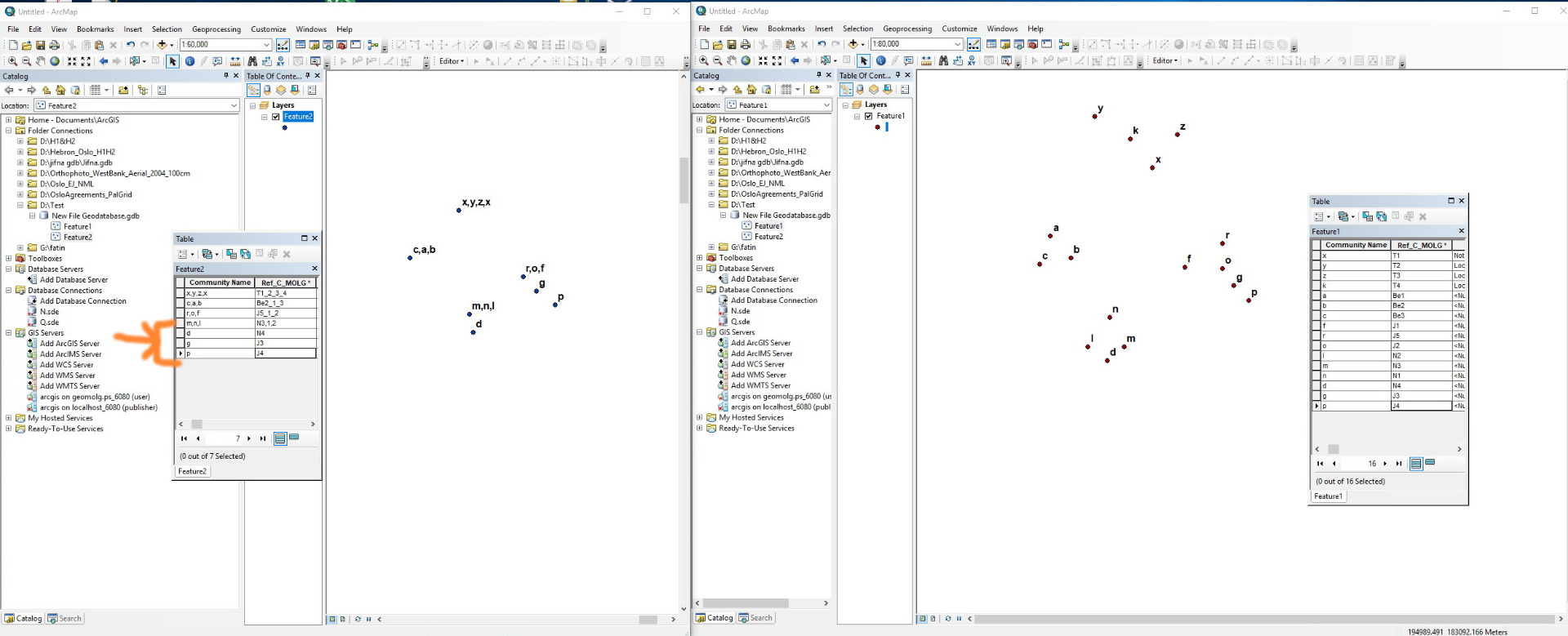
- The new REF value is limited to single governorate and the new REF value should contain the numeric values of old Ref, so it becomes a unique value.
- Kindly notice the order of numeric values on the REF values is not important.
- I would add that some values on FC2 could be single, or not combined as following screenshot.
Best,
Fatin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
One thing I noticed in your latest illustration is that the first example point in FC2 has an incorrect value that violates the rules you have outlined. It shows "x,y,z,x" in the picture and table, but was matched to FC1 as though it was actually "x,y,z,k". These kinds of errors in the value you wrote vs the value you should have written could be detected and reported, but only if the first value always violates your rules.
Second, for item 6 I want to be clear that I was not asking if the total number of characters could be greater than 2. I was asking if the number of numeric digits at the end could be more than 0-9, For example, is EJ10 a possible value in field 2 of FC1, or would they always fall between EJ0-EJ9. Are you saying that the numeric digits at the end can exceed 0-9?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
You are right. This type of incorrect data can be produced by person who entered the data "data entry".
However, these kinds of data should be edited to the correct value"(x,y,z,k)" for this case.
To clarify the values that should be written on our REF fields, kindly notice the following examples:
Tu001,Tu920,Tu020...etc.
Best,
Fatin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If I understand your second illustration, the following is an idea. Table1 would become a search cursor, and Table2 an insert cursor.
import itertools
table1 = [ ['x', 'T1'], ['y', 'T2'], ['z', 'T3'], ['k', 'T4'],
['a', 'Be1'], ['b', 'Be2'], ['c', 'Be3'],
['f', 'J1'], ['r', 'J5'], ['o', 'J2'],
['l', 'N2'], ['m', 'N3'], ['n', 'N1'] ]
table2 = [] # new table
myData = {} # empty dictionary
for row in table1:
item = ["".join(x) for _, x in itertools.groupby(row[1], key=str.isdigit)]
if item[0] in myData:
myData[item[0]].append({row[0] : item[1]})
else:
myData[item[0]] = [{row[0] : item[1]}]
# print myData
for k1, v1 in myData.iteritems():
city = []
cityCode = []
for l in v1:
for k2, v2 in l.iteritems():
city.append(k2)
cityCode.append(v2)
table2.append([",".join(city), k1+",".join(cityCode)])
print table2
# [['a,b,c', 'Be1,2,3'], ['f,r,o', 'J1,5,2'], ['x,y,z,k', 'T1,2,3,4'], ['l,m,n', 'N2,3,1']]- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you Randy. I will try this and let you know if it works with me.
Best,
Fatin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Randy,
I tried your suggestion but i noticed the following:
1.You entered the values on "table 1" manually.We want the python to read the values direct without any need to write them manually.
2.We want the new REF field to be filled depending on the values of other fields, not on a new table. its like copy and paste.
What do you think?
Best,
Fatin