- Home
- :
- All Communities
- :
- Products
- :
- ModelBuilder
- :
- ModelBuilder Questions
- :
- Re: Using GET VALUE in an iterative model
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello. I have a data processing model in ModelBuilder that makes heavy use of the "Get field value" tool. I need to iterate the model over many tables in a geodatabase. When I do this, I do not get the correct values on the output based on the Get field - for each input table, the output is the same each time. I think what is happening is the Get values are being held over from the first run of the model and not being picked up again with values from the next table as the model re-runs. I have also had the same issue trying to use batch on the model. Is there some command I can add to the end of the model that will clear the Get values from the system memory? This is in Desktop 10.4.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Find below a sample script that I created to create a score field with the scores to a copy of the input tables in the file geodatabase.
On line 16 you would change the path to the file geodatabase with your path:
"P:\\Trans\\Technical\\Data Development\\Internal\\EnvironmentalStudies\\EJ2017\\gdb\\VPI_Intervals_Around_Mean_results.gdb"
It does not write all the intermediate statistics to output fields, but below the script I have printed a list with the statistics.
#-------------------------------------------------------------------------------
# Name: table_stats.py
# Purpose:
#
# Author: xbakker
#
# Created: 04/08/2017
#-------------------------------------------------------------------------------
def main():
# import modules
import arcpy
import os
# settings
ws = r'C:\GeoNet\VPI\VPI_Intervals_Around_Mean_results.gdb'
fld_pct = 'PCT'
fld_reg = 'REG'
fld_score = 'Score'
tbl_out_template = "{0}_Statistics"
# get list of table names
arcpy.env.overwriteOutput = True
arcpy.env.workspace = ws
tbl_names = arcpy.ListTables()
# loop through table names
for tbl_name in tbl_names:
print "\nProcessing:", tbl_name
tbl_in = os.path.join(ws, tbl_name)
out_name = tbl_out_template.format(tbl_name)
tbl_out = os.path.join(ws, out_name)
# get first REG value
print "Get first REG value..."
reg = arcpy.da.SearchCursor(tbl_in, (fld_reg)).next()[0]
# get list with all the PCT values
print "create list with PCT values..."
lst_pct = [r[0] for r in arcpy.da.SearchCursor(tbl_in, (fld_pct))]
# statistics
pct_min = min(lst_pct)
pct_max = max(lst_pct)
pct_mean = sum(lst_pct) / float(len(lst_pct))
print " - PCT min :", pct_min
print " - PCT mean:", pct_mean
print " - PCT max :", pct_max
rbm = pct_mean - pct_min
ram = pct_max - pct_mean
rbm_qua = rbm / 4.0
ram_qua = ram / 4.0
print " - RBM:", rbm
print " - RAM:", ram
print " - RBM Quantile:", rbm_qua
print " - RAM Quantile:", ram_qua
# make list of score
scores = [pct_min + a * rbm_qua for a in range(4)]
scores.extend([pct_mean + a * ram_qua for a in range(5)])
print " - list of scores:", scores
# make copy of input table
print "make copy of table..."
arcpy.TableToTable_conversion(tbl_in, ws, out_name)
# add score field
print "add score..."
arcpy.AddField_management(tbl_out, fld_score, "SHORT")
# update cursor for scores
print "update output table with score..."
with arcpy.da.UpdateCursor(tbl_out, (fld_pct, fld_score)) as curs:
for row in curs:
pct = row[0]
score = GetScore(pct, scores)
curs.updateRow((pct, score, ))
def GetScore(val, scores):
for i in range(1, len(scores)):
if val <= scores[i]:
return i
break
if __name__ == '__main__':
main()
Output messages with statistics:
Processing: Disability
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 12.0926549809
- PCT max : 36.5693430657
- RBM: 12.0926549809
- RAM: 24.4766880848
- RBM Quantile: 3.02316374523
- RAM Quantile: 6.1191720212
- list of scores: [0.0, 3.0231637452271105, 6.046327490454221, 9.069491235681332, 12.092654980908442, 18.21182700210469, 24.330999023300937, 30.450171044497182, 36.56934306569343]
make copy of table...
add score...
update output table with score...
Processing: Elderly
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 6.19322841776
- PCT max : 47.5251959686
- RBM: 6.19322841776
- RAM: 41.3319675509
- RBM Quantile: 1.54830710444
- RAM Quantile: 10.3329918877
- list of scores: [0.0, 1.5483071044406356, 3.096614208881271, 4.644921313321907, 6.193228417762542, 16.52622030548316, 26.85921219320378, 37.1922040809244, 47.525195968645015]
make copy of table...
add score...
update output table with score...
Processing: Hispanic
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 4.85961907506
- PCT max : 47.3402796819
- RBM: 4.85961907506
- RAM: 42.4806606069
- RBM Quantile: 1.21490476876
- RAM Quantile: 10.6201651517
- list of scores: [0.0, 1.214904768764334, 2.429809537528668, 3.644714306293002, 4.859619075057336, 15.479784226775589, 26.099949378493843, 36.7201145302121, 47.340279681930355]
make copy of table...
add score...
update output table with score...
Processing: LEP
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 1.75262227971
- PCT max : 22.6290097629
- RBM: 1.75262227971
- RAM: 20.8763874832
- RBM Quantile: 0.438155569927
- RAM Quantile: 5.2190968708
- list of scores: [0.0, 0.4381555699265956, 0.8763111398531912, 1.3144667097797869, 1.7526222797063824, 6.97171915050503, 12.190816021303679, 17.409912892102327, 22.629009762900974]
make copy of table...
add score...
update output table with score...
Processing: Minority
Get first REG value...
create list with PCT values...
- PCT min : 0.454545454545
- PCT mean: 43.1132722883
- PCT max : 100.0
- RBM: 42.6587268337
- RAM: 56.8867277117
- RBM Quantile: 10.6646817084
- RAM Quantile: 14.2216819279
- list of scores: [0.45454545454545453, 11.11922716297691, 21.783908871408364, 32.44859057983982, 43.113272288271276, 57.33495421620346, 71.55663614413564, 85.77831807206782, 100.0]
make copy of table...
add score...
update output table with score...
Processing: NoCar
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 13.4770798991
- PCT max : 80.9723386421
- RBM: 13.4770798991
- RAM: 67.495258743
- RBM Quantile: 3.36926997476
- RAM Quantile: 16.8738146858
- list of scores: [0.0, 3.3692699747642747, 6.738539949528549, 10.107809924292823, 13.477079899057099, 30.350894584812522, 47.22470927056794, 64.09852395632338, 80.9723386420788]
make copy of table...
add score...
update output table with score...
Processing: Poverty
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 12.8652327732
- PCT max : 76.9938650307
- RBM: 12.8652327732
- RAM: 64.1286322575
- RBM Quantile: 3.2163081933
- RAM Quantile: 16.0321580644
- list of scores: [0.0, 3.216308193301268, 6.432616386602536, 9.648924579903804, 12.865232773205072, 28.897390837572516, 44.92954890193996, 60.9617069663074, 76.99386503067484]
make copy of table...
add score...
update output table with score...
Processing: Disability_Statistics
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 12.0926549809
- PCT max : 36.5693430657
- RBM: 12.0926549809
- RAM: 24.4766880848
- RBM Quantile: 3.02316374523
- RAM Quantile: 6.1191720212
- list of scores: [0.0, 3.0231637452271105, 6.046327490454221, 9.069491235681332, 12.092654980908442, 18.21182700210469, 24.330999023300937, 30.450171044497182, 36.56934306569343]
make copy of table...
add score...
update output table with score...The script can easily be converted to a tool in a toolbox.
Kind regards, Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
When a model starts getting more complex I would probably switch to using Python, which gives better control over the functionality and memory usage. Can you share a screenshot of your model to see how complex it is?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The model is not particularly complicated, but it uses GET 15 times. I am not great with Python so if I can find an MB solution I'd like to.

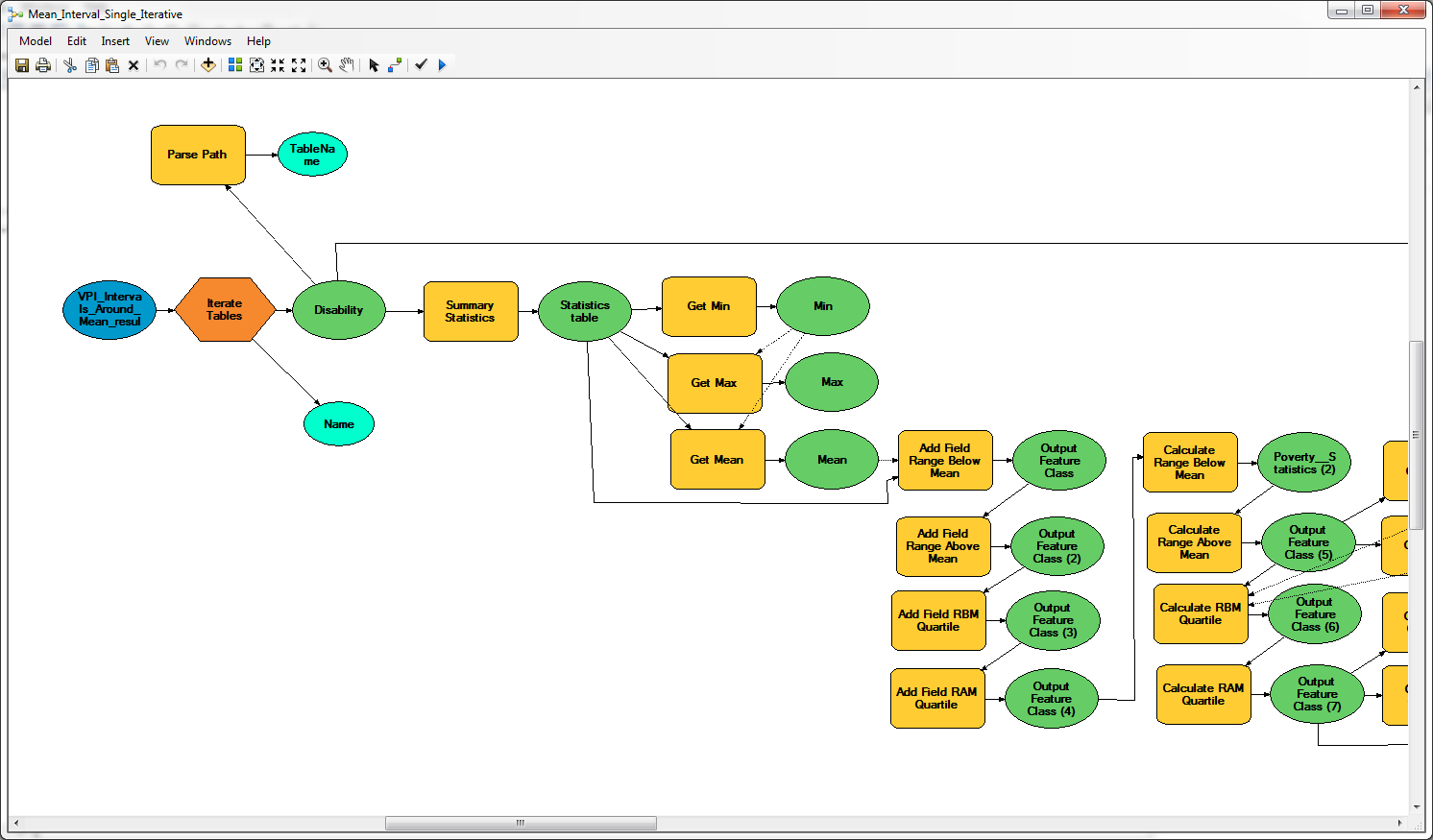
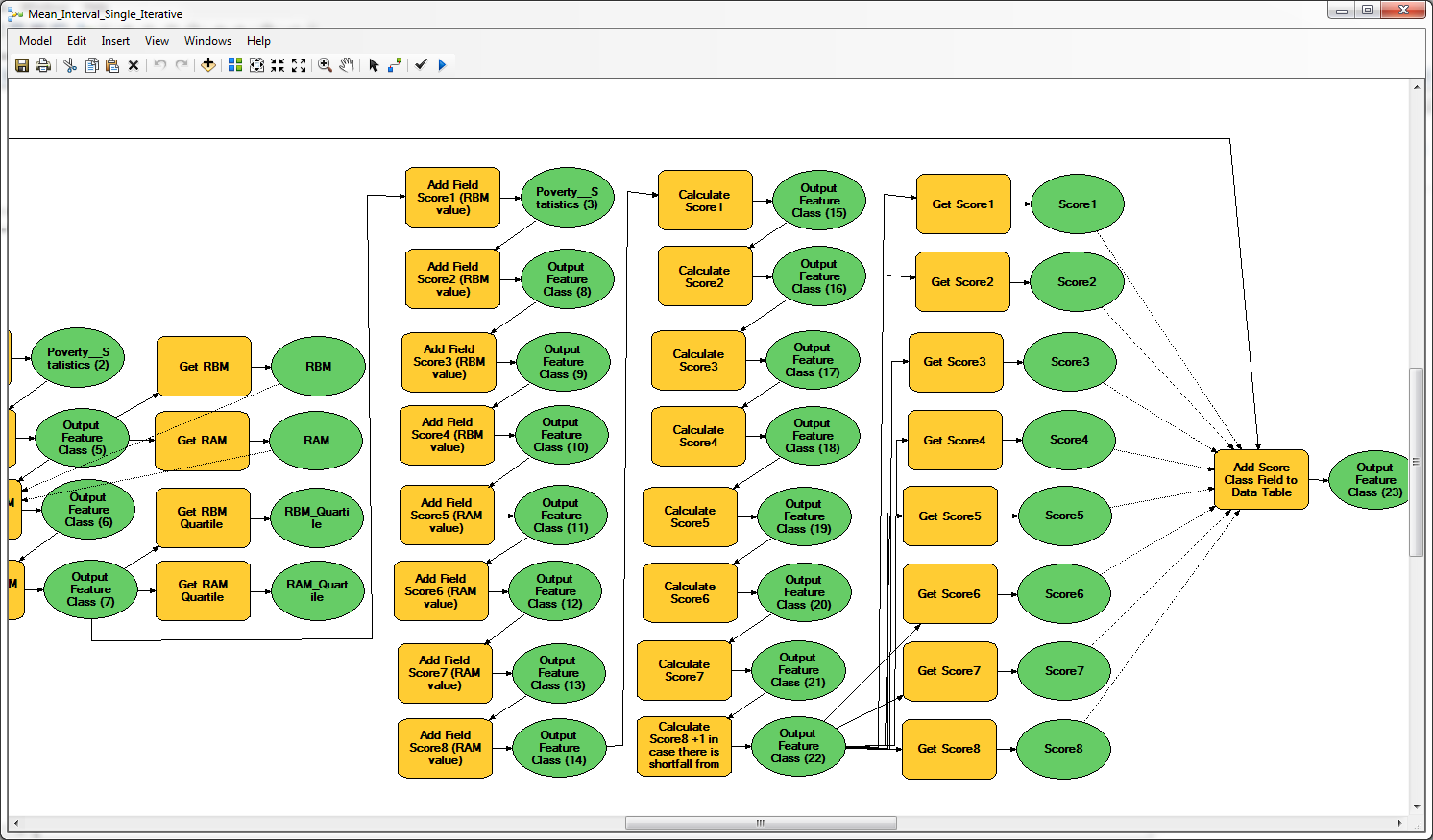
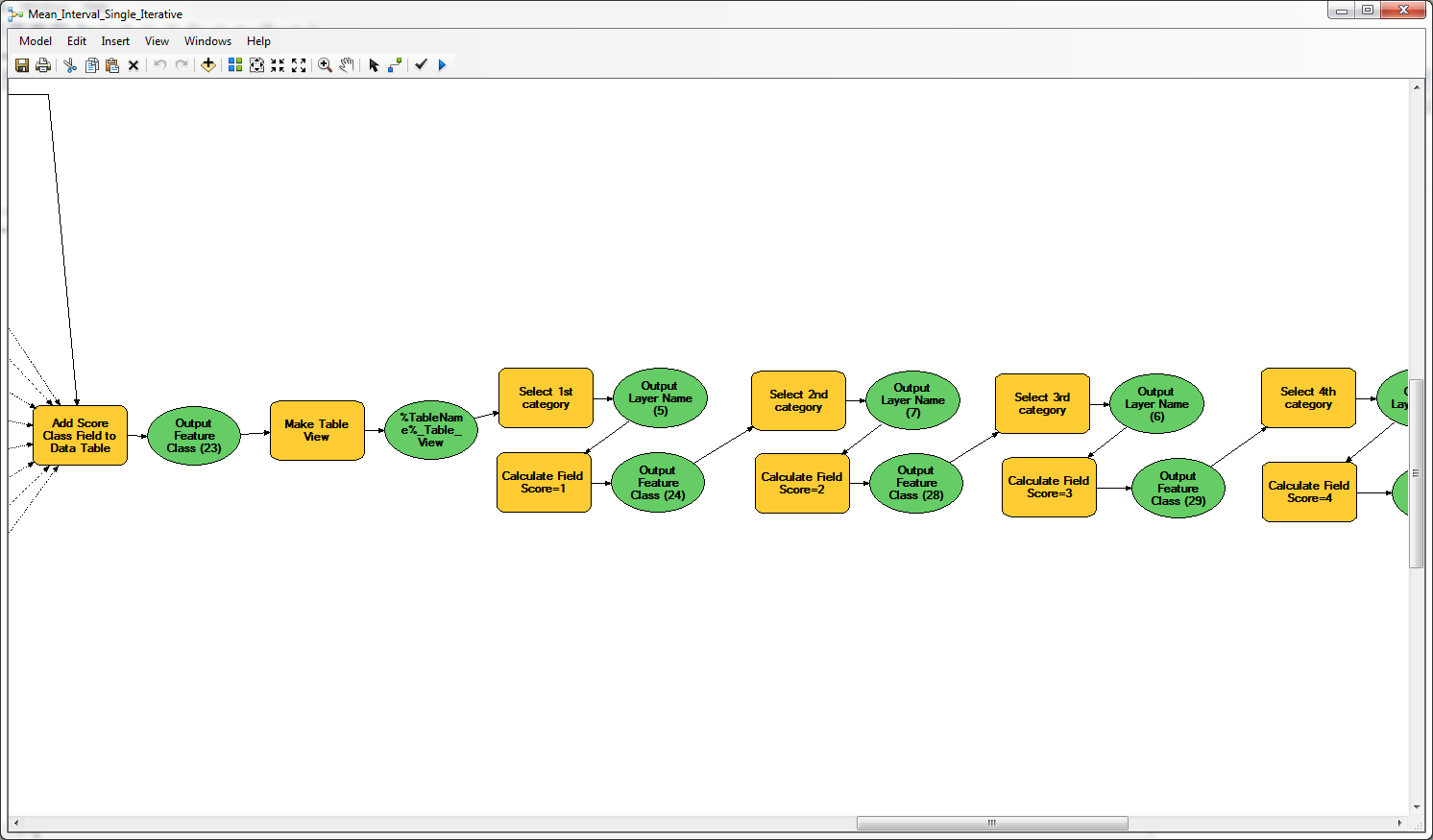
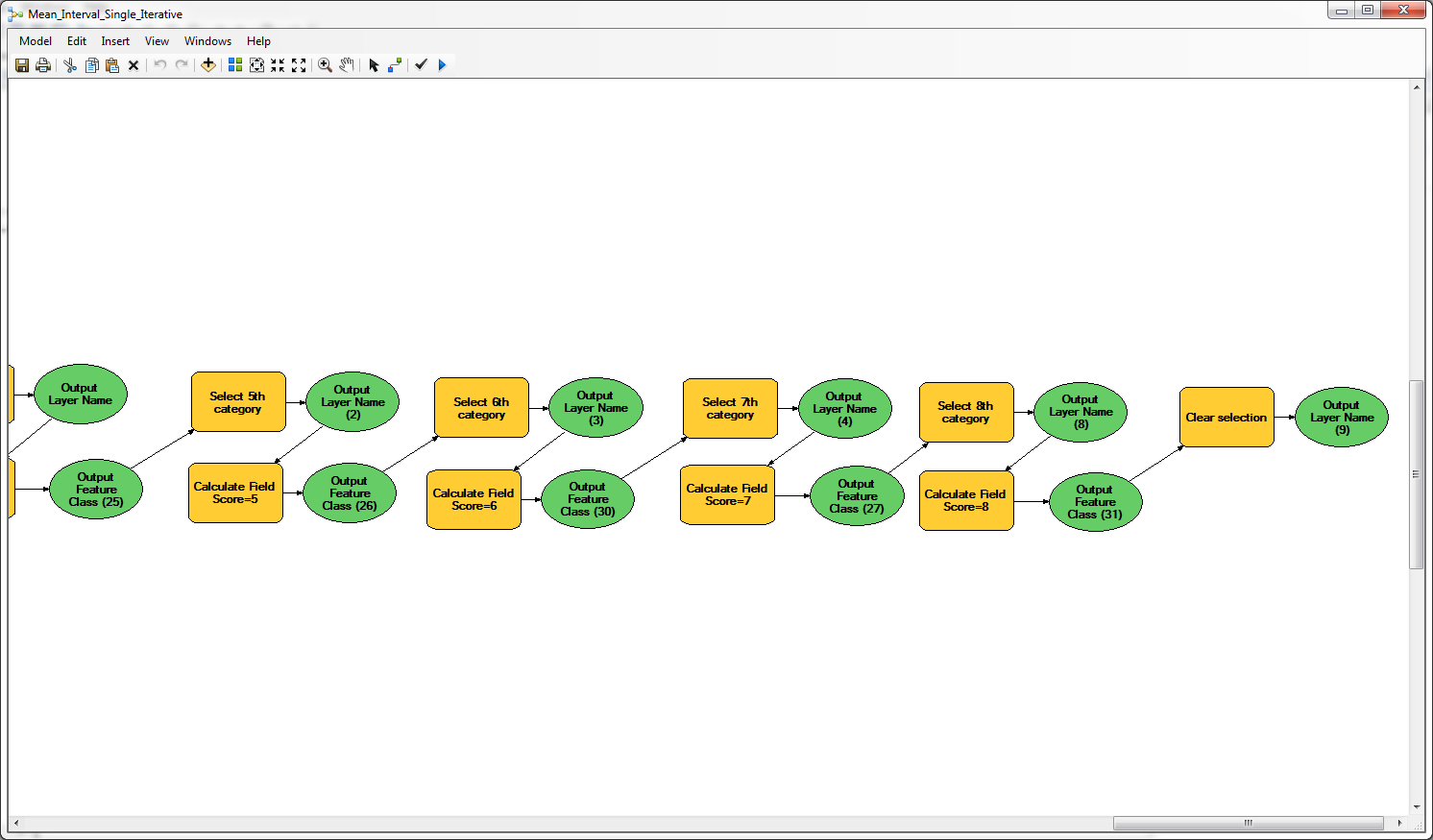
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Although you indicate that the model is not very complex, I see that you use around 60 tools. In this case I would go for a Python script which also provides more tools for debugging in case the result is not what you expected. I suppose an edited version of the script would not be to complex.
Is it possible to export the model as a python script to see what is actually being done? The tools in the screenshot are showing the descriptions that you added to make the model easier to understand, but it reveals the actual tools and parameters used.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# VPI_single_interative_BM_export.py
# Created on: 2017-08-03 10:21:29.00000
# (generated by ArcGIS/ModelBuilder)
# Description:
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy
# Load required toolboxes
arcpy.ImportToolbox("Model Functions")
# Local variables:
VPI_Intervals_Around_Mean_results_gdb = "P:\\Trans\\Technical\\Data Development\\Internal\\EnvironmentalStudies\\EJ2017\\gdb\\VPI_Intervals_Around_Mean_results.gdb"
Disability = "\\\\bmc\\dfs\\Projects\\Trans\\Technical\\Data Development\\Internal\\EnvironmentalStudies\\EJ2017\\gdb\\VPI_Intervals_Around_Mean_results.gdb\\Disability"
Output_Feature_Class__23_ = Disability
Statistics_table = "\\\\bmc\\dfs\\Projects\\Trans\\Technical\\Data Development\\Internal\\EnvironmentalStudies\\EJ2017\\gdb\\VPI_Intervals_Around_Mean_results.gdb\\%TableName%_Statistics"
Min = Statistics_table
Max = Statistics_table
Mean = Statistics_table
Output_Feature_Class = Statistics_table
Output_Feature_Class__2_ = Output_Feature_Class
Output_Feature_Class__3_ = Output_Feature_Class__2_
Output_Feature_Class__4_ = Output_Feature_Class__3_
Poverty__Statistics__2_ = Output_Feature_Class__4_
Output_Feature_Class__5_ = Poverty__Statistics__2_
Output_Feature_Class__6_ = Output_Feature_Class__5_
RBM = Output_Feature_Class__5_
RAM = Output_Feature_Class__5_
Output_Feature_Class__7_ = Output_Feature_Class__6_
RBM_Quartile = Output_Feature_Class__7_
RAM_Quartile = Output_Feature_Class__7_
Poverty__Statistics__3_ = Output_Feature_Class__7_
Output_Feature_Class__8_ = Poverty__Statistics__3_
Output_Feature_Class__9_ = Output_Feature_Class__8_
Output_Feature_Class__10_ = Output_Feature_Class__9_
Output_Feature_Class__11_ = Output_Feature_Class__10_
Output_Feature_Class__12_ = Output_Feature_Class__11_
Output_Feature_Class__13_ = Output_Feature_Class__12_
Output_Feature_Class__14_ = Output_Feature_Class__13_
Output_Feature_Class__15_ = Output_Feature_Class__14_
Output_Feature_Class__16_ = Output_Feature_Class__15_
Output_Feature_Class__17_ = Output_Feature_Class__16_
Output_Feature_Class__18_ = Output_Feature_Class__17_
Output_Feature_Class__19_ = Output_Feature_Class__18_
Output_Feature_Class__20_ = Output_Feature_Class__19_
Output_Feature_Class__21_ = Output_Feature_Class__20_
Output_Feature_Class__22_ = Output_Feature_Class__21_
Score1 = Output_Feature_Class__22_
Score2 = Output_Feature_Class__22_
Score3 = Output_Feature_Class__22_
Score4 = Output_Feature_Class__22_
Score5 = Output_Feature_Class__22_
Score6 = Output_Feature_Class__22_
Score7 = Output_Feature_Class__22_
Score8 = Output_Feature_Class__22_
v_TableName__Table_View = "%TableName%_Table_View"
Output_Layer_Name__5_ = v_TableName__Table_View
Output_Feature_Class__24_ = Output_Layer_Name__5_
Output_Layer_Name__7_ = Output_Feature_Class__24_
Output_Feature_Class__28_ = Output_Layer_Name__7_
Output_Layer_Name__6_ = Output_Feature_Class__28_
Output_Feature_Class__29_ = Output_Layer_Name__6_
Output_Layer_Name = Output_Feature_Class__29_
Output_Feature_Class__25_ = Output_Layer_Name
Output_Layer_Name__2_ = Output_Feature_Class__25_
Output_Feature_Class__26_ = Output_Layer_Name__2_
Output_Layer_Name__3_ = Output_Feature_Class__26_
Output_Feature_Class__30_ = Output_Layer_Name__3_
Output_Layer_Name__4_ = Output_Feature_Class__30_
Output_Feature_Class__27_ = Output_Layer_Name__4_
Output_Layer_Name__8_ = Output_Feature_Class__27_
Output_Feature_Class__31_ = Output_Layer_Name__8_
Output_Layer_Name__9_ = Output_Feature_Class__31_
TableName = "Disability"
Name = "Disability"
# Process: Iterate Tables
arcpy.IterateTables_mb(VPI_Intervals_Around_Mean_results_gdb, "", "", "NOT_RECURSIVE")
# Process: Summary Statistics
arcpy.Statistics_analysis(Disability, Statistics_table, "PCT MIN;PCT MAX;REG FIRST", "")
# Process: Get Min
arcpy.GetFieldValue_mb(Statistics_table, "MIN_PCT", "Any value", "0")
# Process: Get Max
arcpy.GetFieldValue_mb(Statistics_table, "MAX_PCT", "Any value", "0")
# Process: Get Mean
arcpy.GetFieldValue_mb(Statistics_table, "FIRST_REG", "Any value", "0")
# Process: Add Field Range Below Mean
arcpy.AddField_management(Statistics_table, "Range_Below_Mean", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Range Above Mean
arcpy.AddField_management(Output_Feature_Class, "Range_Above_Mean", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field RBM Quartile
arcpy.AddField_management(Output_Feature_Class__2_, "RBM_Quartile", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field RAM Quartile
arcpy.AddField_management(Output_Feature_Class__3_, "RAM_Quartile", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Calculate Range Below Mean
arcpy.CalculateField_management(Output_Feature_Class__4_, "Range_Below_Mean", "%Mean%-%Min%", "VB", "")
# Process: Calculate Range Above Mean
arcpy.CalculateField_management(Poverty__Statistics__2_, "Range_Above_Mean", "%Max%-%Mean%", "VB", "")
# Process: Get RAM
arcpy.GetFieldValue_mb(Output_Feature_Class__5_, "Range_Above_Mean", "Any value", "0")
# Process: Get RBM
arcpy.GetFieldValue_mb(Output_Feature_Class__5_, "Range_Below_Mean", "Any value", "0")
# Process: Calculate RBM Quartile
arcpy.CalculateField_management(Output_Feature_Class__5_, "RBM_Quartile", "%RBM%/4", "VB", "")
# Process: Calculate RAM Quartile
arcpy.CalculateField_management(Output_Feature_Class__6_, "RAM_Quartile", "%RAM%/4", "VB", "")
# Process: Get RBM Quartile
arcpy.GetFieldValue_mb(Output_Feature_Class__7_, "RBM_Quartile", "Any value", "0")
# Process: Get RAM Quartile
arcpy.GetFieldValue_mb(Output_Feature_Class__7_, "RAM_Quartile", "Any value", "0")
# Process: Add Field Score1 (RBM value)
arcpy.AddField_management(Output_Feature_Class__7_, "Score1", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score2 (RBM value)
arcpy.AddField_management(Poverty__Statistics__3_, "Score2", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score3 (RBM value)
arcpy.AddField_management(Output_Feature_Class__8_, "Score3", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score4 (RBM value)
arcpy.AddField_management(Output_Feature_Class__9_, "Score4", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score5 (RAM value)
arcpy.AddField_management(Output_Feature_Class__10_, "Score5", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score6 (RAM value)
arcpy.AddField_management(Output_Feature_Class__11_, "Score6", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score7 (RAM value)
arcpy.AddField_management(Output_Feature_Class__12_, "Score7", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Field Score8 (RAM value)
arcpy.AddField_management(Output_Feature_Class__13_, "Score8", "DOUBLE", "18", "18", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Calculate Score1
arcpy.CalculateField_management(Output_Feature_Class__14_, "Score1", "%Min%+%RBM_Quartile%", "VB", "")
# Process: Calculate Score2
arcpy.CalculateField_management(Output_Feature_Class__15_, "Score2", "%Min%+%RBM_Quartile%+%RBM_Quartile%", "VB", "")
# Process: Calculate Score3
arcpy.CalculateField_management(Output_Feature_Class__16_, "Score3", "%Min%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%", "VB", "")
# Process: Calculate Score4
arcpy.CalculateField_management(Output_Feature_Class__17_, "Score4", "%Min%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%", "VB", "")
# Process: Calculate Score5
arcpy.CalculateField_management(Output_Feature_Class__18_, "Score5", "%Min%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RAM_Quartile%", "VB", "")
# Process: Calculate Score6
arcpy.CalculateField_management(Output_Feature_Class__19_, "Score6", "%Min%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RAM_Quartile%+%RAM_Quartile%", "VB", "")
# Process: Calculate Score7
arcpy.CalculateField_management(Output_Feature_Class__20_, "Score7", "%Min%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RAM_Quartile%+%RAM_Quartile%+%RAM_Quartile%", "VB", "")
# Process: Calculate Score8 +1 in case there is shortfall from decimal differences
arcpy.CalculateField_management(Output_Feature_Class__21_, "Score8", "%Min%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RBM_Quartile%+%RAM_Quartile%+%RAM_Quartile%+%RAM_Quartile%+%RAM_Quartile%+1", "VB", "")
# Process: Get Score1
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score1", "Any value", "0")
# Process: Get Score2
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score2", "Any value", "0")
# Process: Get Score3
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score3", "Any value", "0")
# Process: Get Score4
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score4", "Any value", "0")
# Process: Get Score5
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score5", "Any value", "0")
# Process: Get Score6
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score6", "Any value", "0")
# Process: Get Score7
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score7", "Any value", "0")
# Process: Get Score8
arcpy.GetFieldValue_mb(Output_Feature_Class__22_, "Score8", "Any value", "0")
# Process: Add Score Class Field to Data Table
arcpy.AddField_management(Disability, "Score_%TableName%", "LONG", "12", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Make Table View
arcpy.MakeTableView_management(Output_Feature_Class__23_, v_TableName__Table_View, "", "", "OBJECTID OBJECTID VISIBLE NONE;GEOID GEOID VISIBLE NONE;GEOID2 GEOID2 VISIBLE NONE;NAME NAME VISIBLE NONE;EST_TOTALPOP EST_TOTALPOP VISIBLE NONE;MOE_TOTALPOP MOE_TOTALPOP VISIBLE NONE;EST_DISABLED_M_under5 EST_DISABLED_M_under5 VISIBLE NONE;MOE_DISABLED_M_under5 MOE_DISABLED_M_under5 VISIBLE NONE;EST_DISABLED_M_5_17_yr EST_DISABLED_M_5_17_yr VISIBLE NONE;MOE_DISABLED_M_5_17_yr MOE_DISABLED_M_5_17_yr VISIBLE NONE;EST_DISABLED_M_18_34_yr EST_DISABLED_M_18_34_yr VISIBLE NONE;MOE_DISABLED_M_18_34_yr MOE_DISABLED_M_18_34_yr VISIBLE NONE;EST_DISABLED_M_35_64_yr EST_DISABLED_M_35_64_yr VISIBLE NONE;MOE_DISABLED_M_35_64_yr MOE_DISABLED_M_35_64_yr VISIBLE NONE;EST_DISABLED_M_65_74_yr EST_DISABLED_M_65_74_yr VISIBLE NONE;MOE_DISABLED_M_65_74_yr MOE_DISABLED_M_65_74_yr VISIBLE NONE;EST_DISABLED_M_75yr_up EST_DISABLED_M_75yr_up VISIBLE NONE;MOE_DISABLED_M_75yr_up MOE_DISABLED_M_75yr_up VISIBLE NONE;EST_DISABLED_F_under5 EST_DISABLED_F_under5 VISIBLE NONE;MOE_DISABLED_F_under5 MOE_DISABLED_F_under5 VISIBLE NONE;EST_DISABLED_F_5_17_yr EST_DISABLED_F_5_17_yr VISIBLE NONE;MOE_DISABLED_F_5_17_yr MOE_DISABLED_F_5_17_yr VISIBLE NONE;EST_DISABLED_F_18_34_yr EST_DISABLED_F_18_34_yr VISIBLE NONE;MOE_DISABLED_F_18_34_yr MOE_DISABLED_F_18_34_yr VISIBLE NONE;EST_DISABLED_F_35_64_yr EST_DISABLED_F_35_64_yr VISIBLE NONE;MOE_DISABLED_F_35_64_yr MOE_DISABLED_F_35_64_yr VISIBLE NONE;EST_DISABLED_F_65_74_yr EST_DISABLED_F_65_74_yr VISIBLE NONE;MOE_DISABLED_F_65_74_yr MOE_DISABLED_F_65_74_yr VISIBLE NONE;EST_DISABLED_F_75yr_up EST_DISABLED_F_75yr_up VISIBLE NONE;MOE_DISABLED_F_75yr_up MOE_DISABLED_F_75yr_up VISIBLE NONE;EST_DISABLED EST_DISABLED VISIBLE NONE;PCT_DISABLED PCT_DISABLED VISIBLE NONE;REG_PCT_DISABLED REG_PCT_DISABLED VISIBLE NONE;PCT PCT VISIBLE NONE;REG REG VISIBLE NONE;COUNTY_FIPS COUNTY_FIPS VISIBLE NONE;Score_%TableName% Score_%TableName% VISIBLE NONE")
# Process: Select 1st category
arcpy.SelectLayerByAttribute_management(v_TableName__Table_View, "NEW_SELECTION", "PCT <=%Score1%")
# Process: Calculate Field Score=1
arcpy.CalculateField_management(Output_Layer_Name__5_, "Score_%TableName%", "1", "VB", "")
# Process: Select 2nd category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__24_, "NEW_SELECTION", "PCT >%Score1% AND PCT <=%Score2%")
# Process: Calculate Field Score=2
arcpy.CalculateField_management(Output_Layer_Name__7_, "Score_%TableName%", "2", "VB", "")
# Process: Select 3rd category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__28_, "NEW_SELECTION", "PCT >%Score2% AND PCT <=%Score3%")
# Process: Calculate Field Score=3
arcpy.CalculateField_management(Output_Layer_Name__6_, "Score_%TableName%", "3", "VB", "")
# Process: Select 4th category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__29_, "NEW_SELECTION", "PCT >%Score3% AND PCT <=%Score4%")
# Process: Calculate Field Score=4
arcpy.CalculateField_management(Output_Layer_Name, "Score_%TableName%", "4", "VB", "")
# Process: Select 5th category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__25_, "NEW_SELECTION", "PCT >%Score4% AND PCT <=%Score5%")
# Process: Calculate Field Score=5
arcpy.CalculateField_management(Output_Layer_Name__2_, "Score_%TableName%", "5", "VB", "")
# Process: Select 6th category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__26_, "NEW_SELECTION", "PCT >%Score5% AND PCT <=%Score6%")
# Process: Calculate Field Score=6
arcpy.CalculateField_management(Output_Layer_Name__3_, "Score_%TableName%", "6", "VB", "")
# Process: Select 7th category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__30_, "NEW_SELECTION", "PCT >%Score6% AND PCT <=%Score7%")
# Process: Calculate Field Score=7
arcpy.CalculateField_management(Output_Layer_Name__4_, "Score_%TableName%", "7", "VB", "")
# Process: Select 8th category
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__27_, "NEW_SELECTION", "PCT >%Score7%")
# Process: Calculate Field Score=8
arcpy.CalculateField_management(Output_Layer_Name__8_, "Score_%TableName%", "8", "VB", "")
# Process: Clear selection
arcpy.SelectLayerByAttribute_management(Output_Feature_Class__31_, "CLEAR_SELECTION", "")
# Process: Parse Path
arcpy.ParsePath_mb(Disability, "NAME")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just as I imagined, the Model Builder export as script is really hard to read. Lot´s of unnecessary lines of code.Is it possible to share a part of the data that you are using? I want to understand what the actual output is, to see if the code can be simplified using list and/or dictionaries (I'm pretty sure it can be).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sure, it's all derived from Census data. Here is the file gdb. The model creates a statistics table for each table in the gdb and uses the data from the statistics tables to modify the main table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks, I will have a look and see what is possible.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Find below a sample script that I created to create a score field with the scores to a copy of the input tables in the file geodatabase.
On line 16 you would change the path to the file geodatabase with your path:
"P:\\Trans\\Technical\\Data Development\\Internal\\EnvironmentalStudies\\EJ2017\\gdb\\VPI_Intervals_Around_Mean_results.gdb"
It does not write all the intermediate statistics to output fields, but below the script I have printed a list with the statistics.
#-------------------------------------------------------------------------------
# Name: table_stats.py
# Purpose:
#
# Author: xbakker
#
# Created: 04/08/2017
#-------------------------------------------------------------------------------
def main():
# import modules
import arcpy
import os
# settings
ws = r'C:\GeoNet\VPI\VPI_Intervals_Around_Mean_results.gdb'
fld_pct = 'PCT'
fld_reg = 'REG'
fld_score = 'Score'
tbl_out_template = "{0}_Statistics"
# get list of table names
arcpy.env.overwriteOutput = True
arcpy.env.workspace = ws
tbl_names = arcpy.ListTables()
# loop through table names
for tbl_name in tbl_names:
print "\nProcessing:", tbl_name
tbl_in = os.path.join(ws, tbl_name)
out_name = tbl_out_template.format(tbl_name)
tbl_out = os.path.join(ws, out_name)
# get first REG value
print "Get first REG value..."
reg = arcpy.da.SearchCursor(tbl_in, (fld_reg)).next()[0]
# get list with all the PCT values
print "create list with PCT values..."
lst_pct = [r[0] for r in arcpy.da.SearchCursor(tbl_in, (fld_pct))]
# statistics
pct_min = min(lst_pct)
pct_max = max(lst_pct)
pct_mean = sum(lst_pct) / float(len(lst_pct))
print " - PCT min :", pct_min
print " - PCT mean:", pct_mean
print " - PCT max :", pct_max
rbm = pct_mean - pct_min
ram = pct_max - pct_mean
rbm_qua = rbm / 4.0
ram_qua = ram / 4.0
print " - RBM:", rbm
print " - RAM:", ram
print " - RBM Quantile:", rbm_qua
print " - RAM Quantile:", ram_qua
# make list of score
scores = [pct_min + a * rbm_qua for a in range(4)]
scores.extend([pct_mean + a * ram_qua for a in range(5)])
print " - list of scores:", scores
# make copy of input table
print "make copy of table..."
arcpy.TableToTable_conversion(tbl_in, ws, out_name)
# add score field
print "add score..."
arcpy.AddField_management(tbl_out, fld_score, "SHORT")
# update cursor for scores
print "update output table with score..."
with arcpy.da.UpdateCursor(tbl_out, (fld_pct, fld_score)) as curs:
for row in curs:
pct = row[0]
score = GetScore(pct, scores)
curs.updateRow((pct, score, ))
def GetScore(val, scores):
for i in range(1, len(scores)):
if val <= scores[i]:
return i
break
if __name__ == '__main__':
main()
Output messages with statistics:
Processing: Disability
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 12.0926549809
- PCT max : 36.5693430657
- RBM: 12.0926549809
- RAM: 24.4766880848
- RBM Quantile: 3.02316374523
- RAM Quantile: 6.1191720212
- list of scores: [0.0, 3.0231637452271105, 6.046327490454221, 9.069491235681332, 12.092654980908442, 18.21182700210469, 24.330999023300937, 30.450171044497182, 36.56934306569343]
make copy of table...
add score...
update output table with score...
Processing: Elderly
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 6.19322841776
- PCT max : 47.5251959686
- RBM: 6.19322841776
- RAM: 41.3319675509
- RBM Quantile: 1.54830710444
- RAM Quantile: 10.3329918877
- list of scores: [0.0, 1.5483071044406356, 3.096614208881271, 4.644921313321907, 6.193228417762542, 16.52622030548316, 26.85921219320378, 37.1922040809244, 47.525195968645015]
make copy of table...
add score...
update output table with score...
Processing: Hispanic
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 4.85961907506
- PCT max : 47.3402796819
- RBM: 4.85961907506
- RAM: 42.4806606069
- RBM Quantile: 1.21490476876
- RAM Quantile: 10.6201651517
- list of scores: [0.0, 1.214904768764334, 2.429809537528668, 3.644714306293002, 4.859619075057336, 15.479784226775589, 26.099949378493843, 36.7201145302121, 47.340279681930355]
make copy of table...
add score...
update output table with score...
Processing: LEP
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 1.75262227971
- PCT max : 22.6290097629
- RBM: 1.75262227971
- RAM: 20.8763874832
- RBM Quantile: 0.438155569927
- RAM Quantile: 5.2190968708
- list of scores: [0.0, 0.4381555699265956, 0.8763111398531912, 1.3144667097797869, 1.7526222797063824, 6.97171915050503, 12.190816021303679, 17.409912892102327, 22.629009762900974]
make copy of table...
add score...
update output table with score...
Processing: Minority
Get first REG value...
create list with PCT values...
- PCT min : 0.454545454545
- PCT mean: 43.1132722883
- PCT max : 100.0
- RBM: 42.6587268337
- RAM: 56.8867277117
- RBM Quantile: 10.6646817084
- RAM Quantile: 14.2216819279
- list of scores: [0.45454545454545453, 11.11922716297691, 21.783908871408364, 32.44859057983982, 43.113272288271276, 57.33495421620346, 71.55663614413564, 85.77831807206782, 100.0]
make copy of table...
add score...
update output table with score...
Processing: NoCar
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 13.4770798991
- PCT max : 80.9723386421
- RBM: 13.4770798991
- RAM: 67.495258743
- RBM Quantile: 3.36926997476
- RAM Quantile: 16.8738146858
- list of scores: [0.0, 3.3692699747642747, 6.738539949528549, 10.107809924292823, 13.477079899057099, 30.350894584812522, 47.22470927056794, 64.09852395632338, 80.9723386420788]
make copy of table...
add score...
update output table with score...
Processing: Poverty
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 12.8652327732
- PCT max : 76.9938650307
- RBM: 12.8652327732
- RAM: 64.1286322575
- RBM Quantile: 3.2163081933
- RAM Quantile: 16.0321580644
- list of scores: [0.0, 3.216308193301268, 6.432616386602536, 9.648924579903804, 12.865232773205072, 28.897390837572516, 44.92954890193996, 60.9617069663074, 76.99386503067484]
make copy of table...
add score...
update output table with score...
Processing: Disability_Statistics
Get first REG value...
create list with PCT values...
- PCT min : 0.0
- PCT mean: 12.0926549809
- PCT max : 36.5693430657
- RBM: 12.0926549809
- RAM: 24.4766880848
- RBM Quantile: 3.02316374523
- RAM Quantile: 6.1191720212
- list of scores: [0.0, 3.0231637452271105, 6.046327490454221, 9.069491235681332, 12.092654980908442, 18.21182700210469, 24.330999023300937, 30.450171044497182, 36.56934306569343]
make copy of table...
add score...
update output table with score...The script can easily be converted to a tool in a toolbox.
Kind regards, Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you so much for your help, this works great. The math isn't quite right but I don't think that could have been guessed from my model without a detailed explanation, I can easily adjust it.