- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Re: Removing Excess Records in Point Feature
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Im geotagging photos to points and would like to remove excess points. Im currently associating these photos/points to my parcel layer and i only need a few points per parcel. Setting the garmin and driving in real world conditions with varying parcel frontage creates quite a bit of excess data, how can i reduce the clutter?
Is there a tolerance i can set to only generate points for every 20 ft? Or is there another geoprocessing tool that will remove excess points based on a set distance?
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
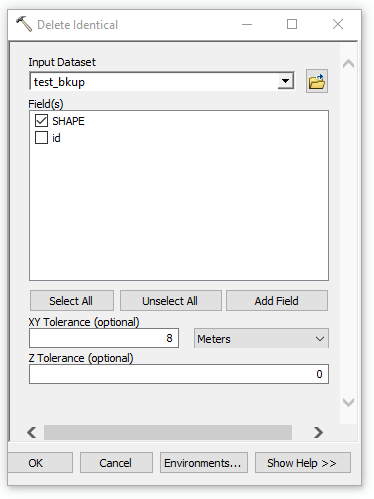
Try the Delete Identical tool.
WARNING - This tool edits the data in situ so make a back up before try this approach!
Here are some points (coloured by group ID), the black squares are the points remaining after running the tool.
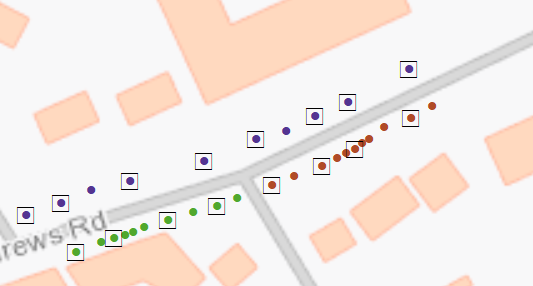
So for example the green points have been reduced to 4 points.
Set the SHAPE field to be the field that is tested and then set XY tolerance. It is this value that you need play around with for your data. For my points 8m seemed like a good value to reduce the points, the higher the value the less points you will have.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Preston,
You can try Using Select By Location—Help | ArcGIS Desktop to select the points within 20 ft and delete them.
I hope this helps!
~Shan
~Shan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Shan,
Unfortunately the select by location wont work with this. Im essentially trying to remove clusters of points from the input layer and as of right now i dont have a source layer that will aid in the selection. I should back up and also say that im trying to incorporate this consolidation of points within a model builder so im really looking for a geoprocessing tool.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
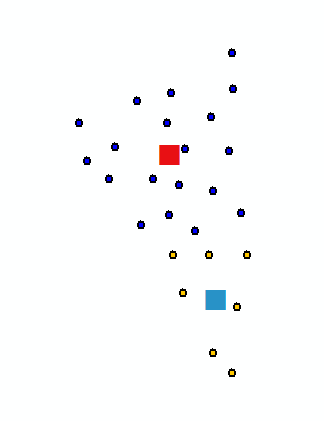
You could also try the mean center tool assuming your points are grouped by some ID field. Below is an example of a cluster of points colour coded by an ID field and their central mean. Just search the help file to locate this tool in ArcToolbox.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Duncan,
This is close to what im after. I could use this tool if i were only concerned with getting 1 point per common attribute (one point per parcel number). My goal here is to retain a few points per parcel and eliminate the clusters. Im wondering if there is a way to attribute by proximity or rather maybe i could attribute a field with an xy coordinate, reduce the character count in the field and then use the mean center. Im thinking out loud here, ill give this a shot.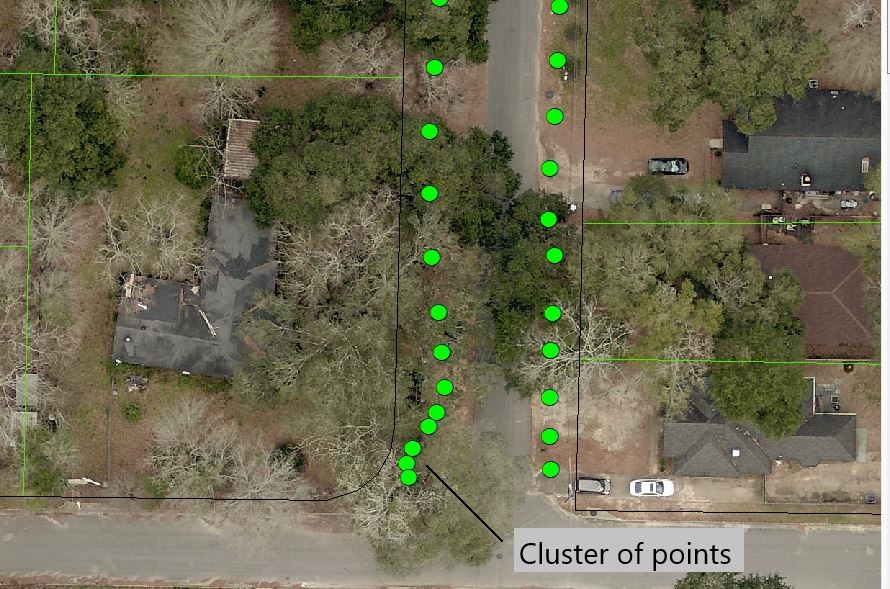
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try the Delete Identical tool.
WARNING - This tool edits the data in situ so make a back up before try this approach!
Here are some points (coloured by group ID), the black squares are the points remaining after running the tool.
So for example the green points have been reduced to 4 points.
Set the SHAPE field to be the field that is tested and then set XY tolerance. It is this value that you need play around with for your data. For my points 8m seemed like a good value to reduce the points, the higher the value the less points you will have.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Oh boy. So the tool worked! I had tried the tool in the past and was not getting any results. After your recommendation i dug back into it and found the reason why it was not initially working. My Shape field was populated with Point ZM which Delete Identical does not like. A simple Feature Class to Feature Class to a point layer solved the problem. Thank You very much.
As a side note, do you know of a tool that would limit the amount of points associated with a target feature (polygon)? Say i have multiple polygons with a varying amount of geographically associated points via a spatial join. I want to standardized the amount of points per polygon to say 3. I would imagine there would be a maximum tolerance setting under the spatial join tool but i dont see one.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I don't think there is an off the shelf tool that does that, you would need to script it. So if say 1 polygon intersected 10 points another 2000 you both want them to say have just 3 points? Assuming the points are randomly located within their respective polygons then you could script to take the first 3.