- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Populate new field ID based on conditions from oth...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Populate new field ID based on conditions from other fields
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi everyone.
I am trying to populate a field using unique identification based on two existing fields.
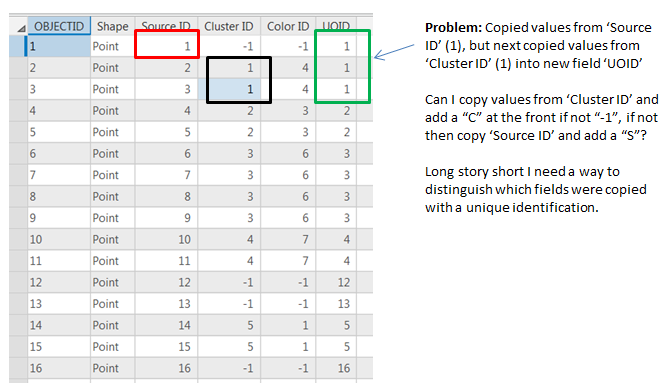
Background: I ran the Density-Based Clustering tool on a set of points. The output creates a new field called 'Cluster ID' which groups clusters sequentially. If the input points are not a cluster they are assigned "-1". I created a new field called 'UOID' which copies the field from the 'Cluster ID' unless "-1", in that case it copies the field from the 'Source ID'.
Problem: There are instances where both fields will be copied to the new field 'UOID' (for instance the number 1). Is there a python script that will allow me to populate the new field 'UOID' adding unique identification to distinguish which fields were copied? For instance can i put a "C" in front of the copied fields from the 'Cluster ID' field and a "S" in front of the 'Source ID'? Take a look at my data. Long story short i need a way to distinguish which fields were copied using unique identification.
Thank you very much!!
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Worked perfectly Lance. Now I can copy the appropriate fields, while ensuring they are uniquely identifiable. THanks alot!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Noni,
Using field calculator create a code block such as the following:
def uio(cluster, source):
if cluster > 0:
return 'C%s' %cluster
else:
return 'S%s' %sourceThe %s is replaced with the cluster or source value C1, S10, etc. Make sure the field you are placing the return into is Text and not Numeric. You would call the function using the field names:
uio(!cluster!, !source!)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Worked perfectly Lance. Now I can copy the appropriate fields, while ensuring they are uniquely identifiable. THanks alot!!