- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Re: Model Builder - Create a GDB with Datasets usi...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Model Builder - Create a GDB with Datasets using other reference GDB
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
I have the Source GDB with 4 DataSets with Data. So I want to Create a Empty GDB and create a Datasets as per the Source GDB. Presently I have ignored the Co-Ordinate System. I have tried in different ways but I can't able to create. If the Target GDB is already created, I was able to Create the Datasets as per the Source Dataset names. But If I create the GDB also in model, I am getting problem.
If I ran the as per the attachment, every time Create GDB also iterating. So I was tried with different ways, but I can't able to explain the experiment. If anybody create Please try to help me.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
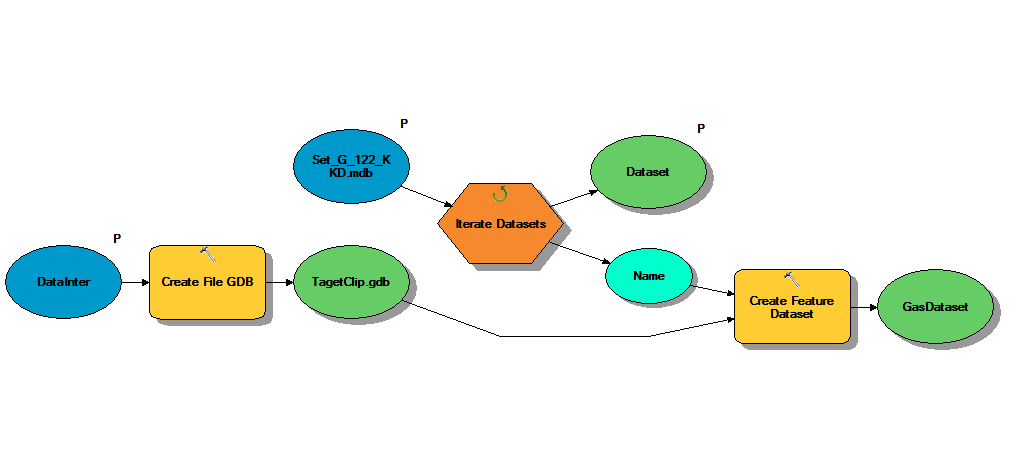
I tested this on my machine and everything appears to work fine. Images of my model are shown below.
Parent Model
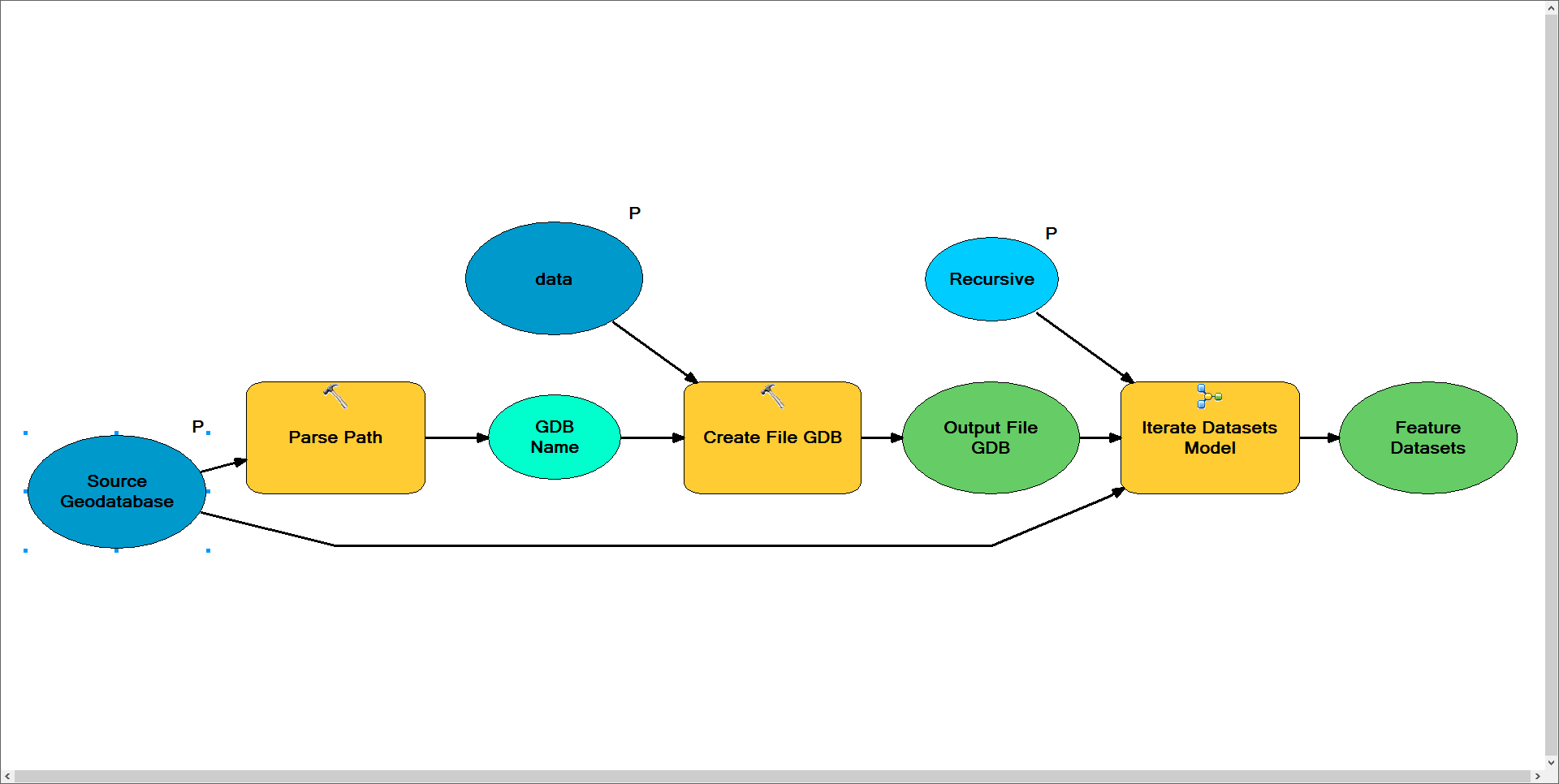
Notes: I need this model to create the new geodatabase once. As such, I've placed the iteration logic within a submodel in this model. The model is designed to grab the new geodatabase name from the source geodatabase. In this case your source was a personal geodatabase (*.mdb) and this model outputs a file geodatabase (*.gdb). It then feeds this newly created file geodatabase as the output workspace for the Iterate Datasets submodel and uses the personal geodatabase as the input workspace.
Sub Model to Create Feature Datasets
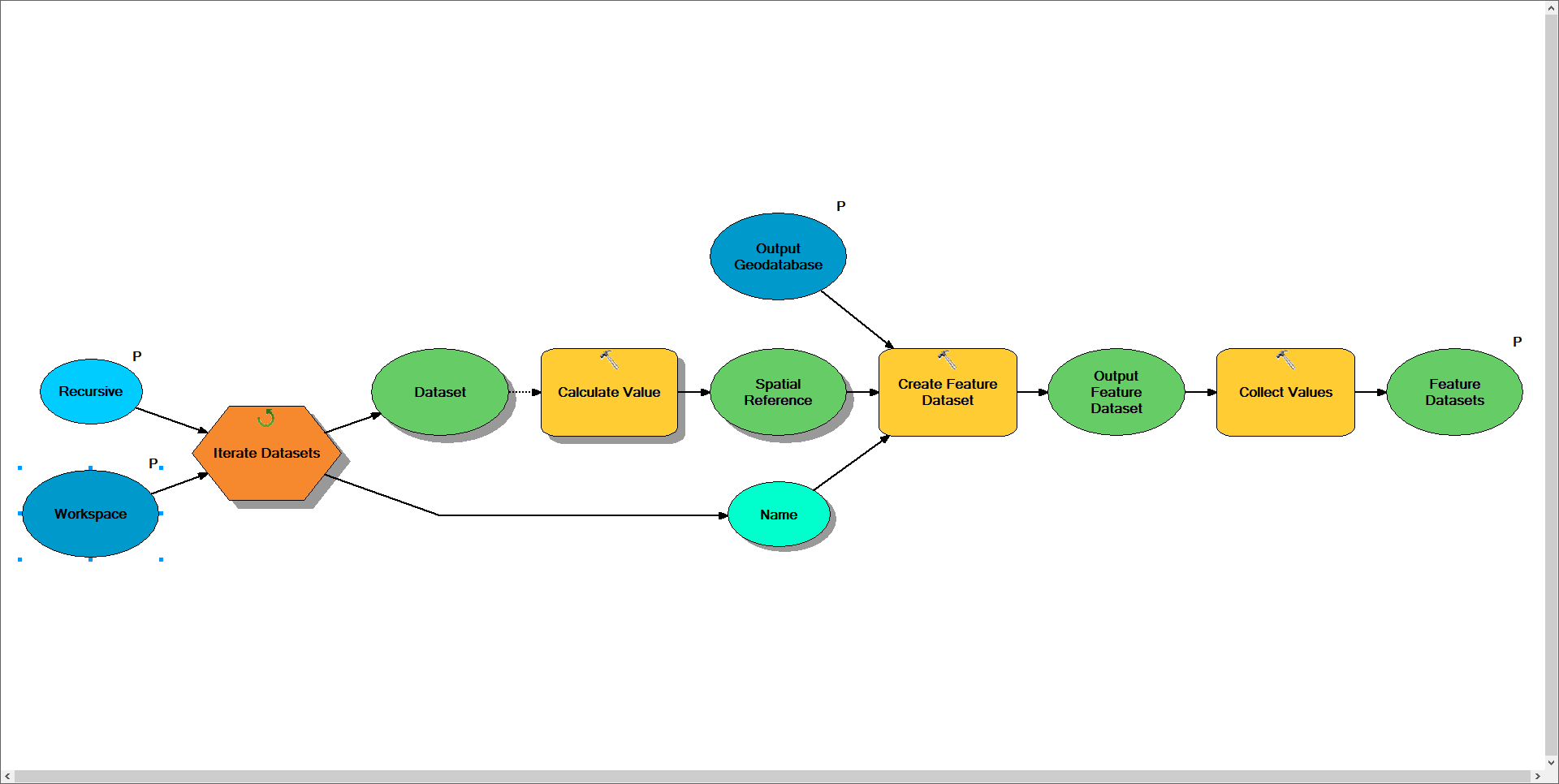
Notes: This model is designed to iterate through the input workspace and locate each of it's feature datasets. For each feature dataset found the model will use python to determine its spatial reference, grab the name of the feature dataset from the iterator, and use the specified output workspace to create a new copy of the feature dataset. Warning: As a result of an iterator being in this model the entire model will repeat for each dataset found.
I'm not sure if you're wanting to use this model to recreate the entire geodatabase, but if you were you would continue this workflow to do so. I would think you'd need three more models to handle the other datatypes (i.e. tables, rasters, and feature classes). Due to the limitation that model can only contain a single iterator I would think you'd need a minimum of 6 models to complete this task, of which I've provided the first two.
The end result would vary depending on how complex you want to setup the logic. In the above model I return the newly created feature datasets as a list and would want to build additional models to handle iterating through each of these workspaces. Otherwise you could implement logic to determine if the data is stored within a feature dataset and then locate and create the path to the matching feature dataset in the new workspace.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
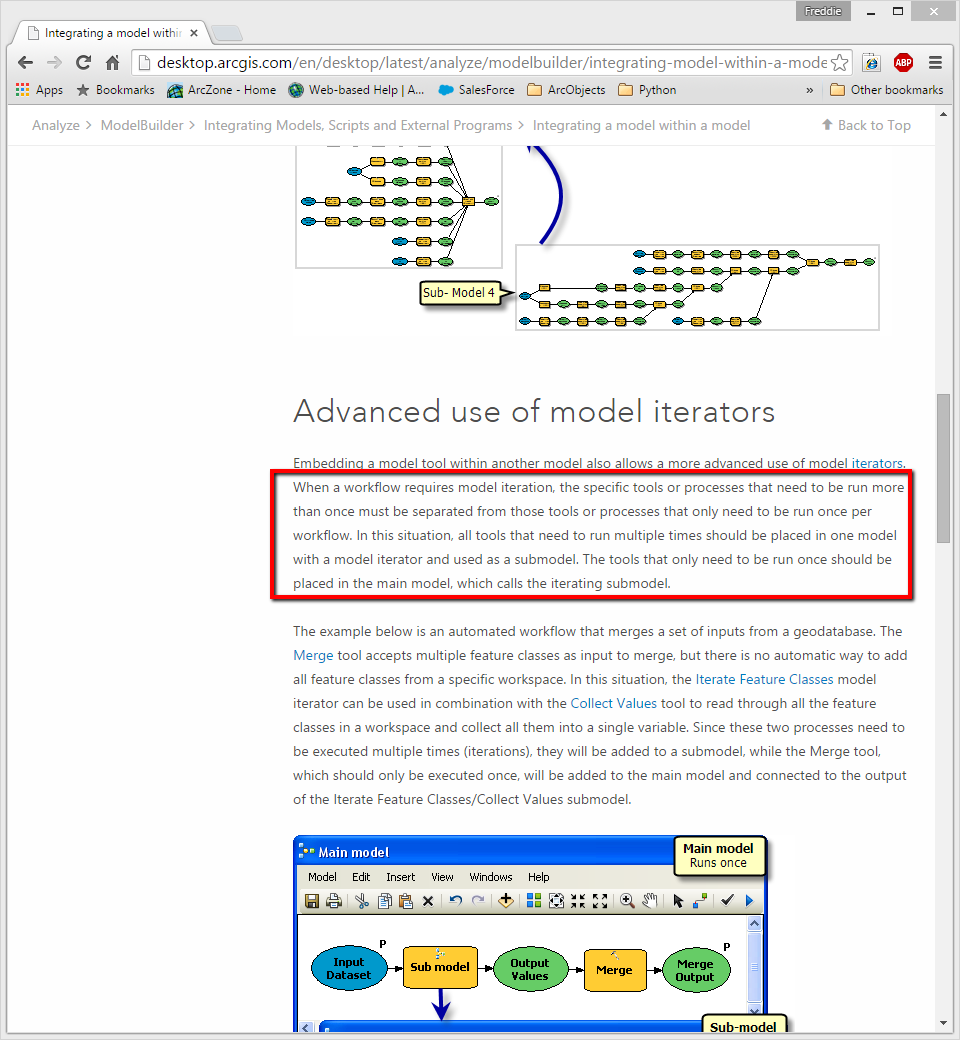
I believe you'd need to move your iteration logic into a separate model. If this logic is within the same model as the create geodatabase tool it will try to create the geodatabase on every iteration. You can see the following page for more information on this process.
Integrating a model within a model
Near the bottom of this page you'll see a section titled "Advanced use of model iterators". It will describe the problem you're running into.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for Quick reply Freddie.
But I have already tried with a calling sub model to main model in different ways. In that example they have create the feature classes through Merge tool using of collected values. In my case I have to create the datasets, this case merge tool is not useful.
Could you try to create a temporary GDB with datasets, then try for my requirement if you have find any other solution please let me know. Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I tested this on my machine and everything appears to work fine. Images of my model are shown below.
Parent Model
Notes: I need this model to create the new geodatabase once. As such, I've placed the iteration logic within a submodel in this model. The model is designed to grab the new geodatabase name from the source geodatabase. In this case your source was a personal geodatabase (*.mdb) and this model outputs a file geodatabase (*.gdb). It then feeds this newly created file geodatabase as the output workspace for the Iterate Datasets submodel and uses the personal geodatabase as the input workspace.
Sub Model to Create Feature Datasets
Notes: This model is designed to iterate through the input workspace and locate each of it's feature datasets. For each feature dataset found the model will use python to determine its spatial reference, grab the name of the feature dataset from the iterator, and use the specified output workspace to create a new copy of the feature dataset. Warning: As a result of an iterator being in this model the entire model will repeat for each dataset found.
I'm not sure if you're wanting to use this model to recreate the entire geodatabase, but if you were you would continue this workflow to do so. I would think you'd need three more models to handle the other datatypes (i.e. tables, rasters, and feature classes). Due to the limitation that model can only contain a single iterator I would think you'd need a minimum of 6 models to complete this task, of which I've provided the first two.
The end result would vary depending on how complex you want to setup the logic. In the above model I return the newly created feature datasets as a list and would want to build additional models to handle iterating through each of these workspaces. Otherwise you could implement logic to determine if the data is stored within a feature dataset and then locate and create the path to the matching feature dataset in the new workspace.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you very much Freddie. Could you provide the snap shot of Calculate Value. Please check below my snapshots of questions.
I have checked without Spatial reference its works fine.
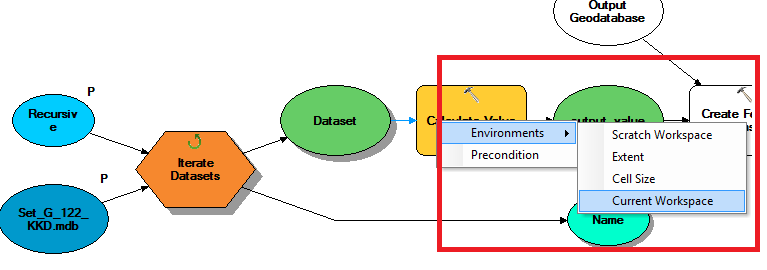
In above place which one need to give. I think is Current workspace. Please suggest me.
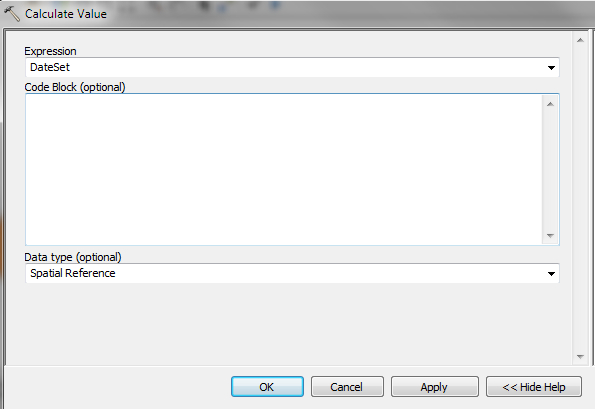
Could you provide the code. Thank you in advance
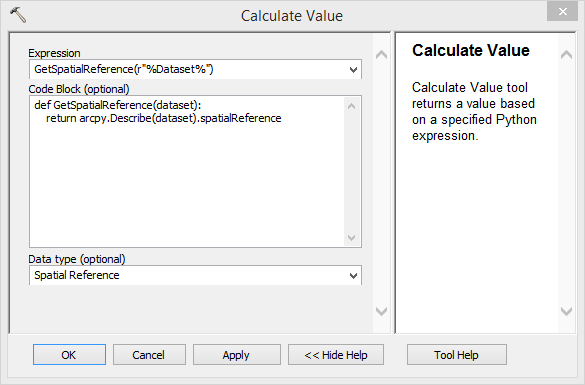
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank You 