- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- How to union to polygons with lots of overlap
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to union to polygons with lots of overlap
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi all,
I've got myself a tricky situation that I hope someone can help me out with. Explaining the problem is a bit tricky, but I'll do my best. Please note that I am certainly not GIS expert, so please do your best to explain any solution as simple and detailed as you can. I'm using ArcMAP.
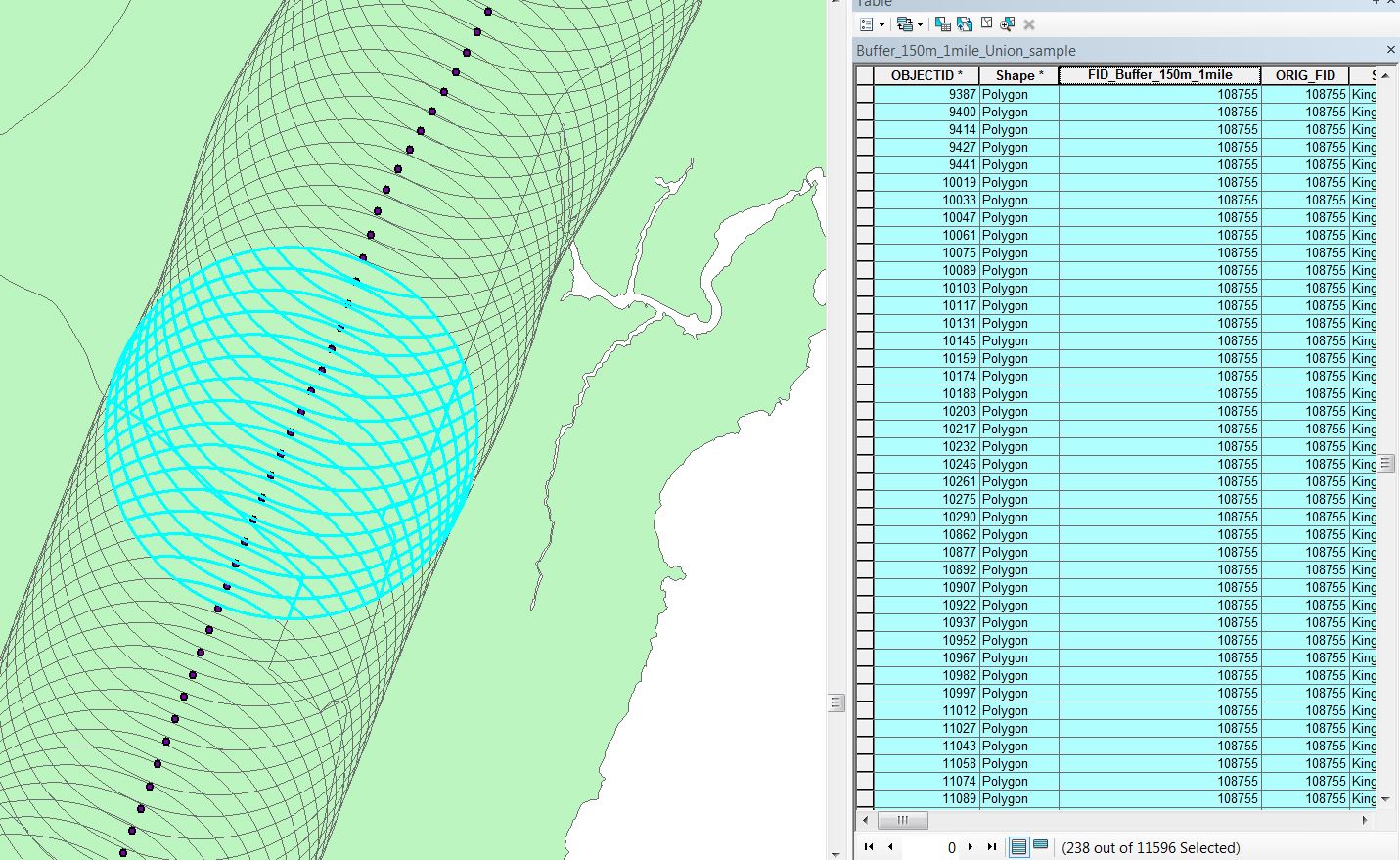
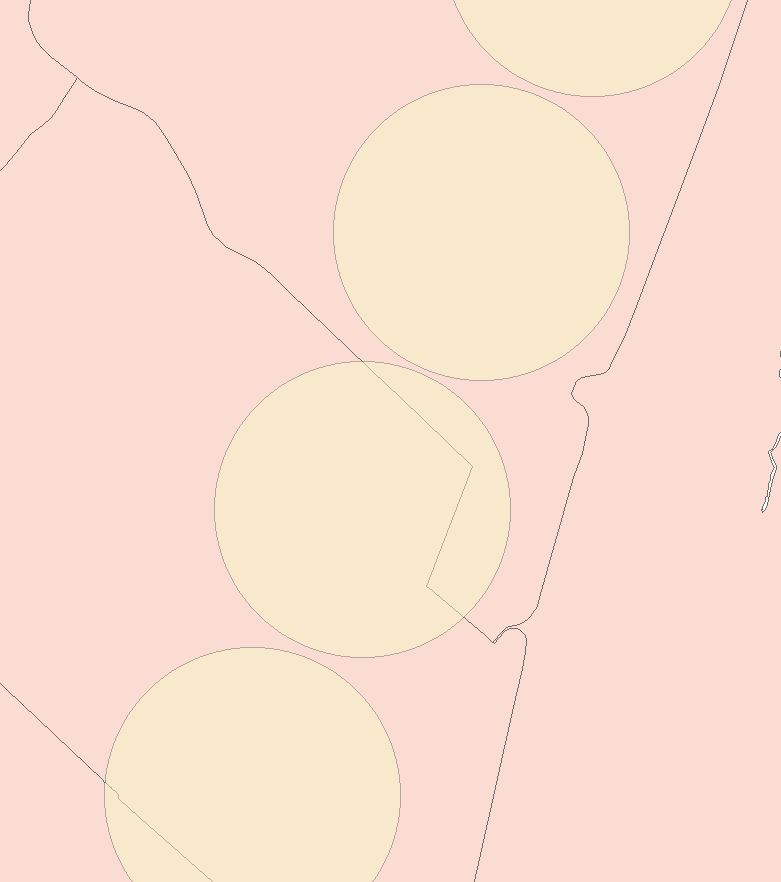
What I'm trying to do is take points along a road network, and determine the population in a 1 mile radius. To do this I have created a points layer, and have found a polygon layer with a certain population in each polygon. The polygon's range in size from a few hundred square km's to a hundred square kilometers (Picture #1). The way I've done this so far is to create a 1 mile buffer around each point (Picture #2). Now in order to determine the population in each buffer zone, I need to know the population density in each population polygon (I have this calculated) as well as the area that each mile buffer includes. When I union these two layers, my result is a layer with population density and area for each buffer. From there I can easily determine the population in each buffer (picture #3). However, it starts to become very difficult to do this when the points get closer together, because the buffer zone's begin to overlap eachother. When I try to union the buffer and the population polygons, it looks at each buffer overlap as its own individual polygon (picture #4). So now instead of 2 records for my one point, I end up with 237 records for my point. Across my entire network, I have a couple hundred thousand points. My computer can't handle the hundreds of millions of overlaps this causes. Does anybody have a way I can avoid this? I tried to dissolve the buffer layer, but when I Union the dissolved buffer it goes back to looking at each overlap as its own polygon, and I still end up with 100 million records.
I'm not committed to using the union method I've explained using above, but any attempt to use other methods such as spatial join doesn't seem to provide the information I need in the new layer (such as the area of the various population polygons it contains). Hopefully I've managed to explain my problem well enough, and haven't made you all too bored to read this entire problem. Thanks in advance for any suggestions or advice! I'll answer any questions you throw at me as best I can.
Thanks,
Zach
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
One way to go is to process each polygon individually. This can be automated by employing Modelbuilder or Python.
I'm not great with Python, but here is how to do it with Modelbuilder:
- Create a New Toolbox. What is ModelBuilder?—ArcGIS Pro | ArcGIS Desktop
- Create a Model
- Edit the Model. Add your polygons and your buffers
- Add an Iterator. Examples of using iterators in ModelBuilder—Help | ArcGIS for Desktop
- Use "Inline Variable Substitution" to ensure there is a unique output for each buffer run. Otherwise each time the Iterator moves on to a new buffer it will overwrite the output with the result from the latest iteration. Inline variable substitution—ArcGIS Pro | ArcGIS Desktop
- Note: you probably can also add in the processing to do the calculations as another step in the model. Calculate Value—Tools | ArcGIS Desktop
Note that if you have not worked with Modelbuilder before that it will probably take some front-end time to learn it and get confident with it. I'd suggest saving off just a few buffers to a separate feature class for testing purposes until you get the Model working, then point at the full buffer dataset to do the runs.
Also - be sure to keep the file paths and filenames simple. Ensure there are no spaces in either the file paths or filenames, or the model will often fail with no error message. Likewise, if the path is very long, even if it has no spaces the model may fail to run, and again no error message. It is pretty common to have to do data organizing and cleanup like this before doing a run for the first time on data.
Chris Donohue, GISP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Chris, that sounds like it could be exactly what I'm looking for, so I'll give it a shot. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A couple thoughts:
Would an Intersect be more appropriate than Union?
When dealing with population polygons, you have to make and/or accept the assumption that the population is evenly distributed across the polygon. When you intersect or union data with population polygons, you end up with just a piece of the population polygon, or a percentage of the original area. In analyses I've done with population polygons, I'm okay with the population distribution, and I add an new field called Area_Orig which is calculated to (drum roll) the Shape Area of the untouched polygon. That way, after the geoprocess I can divide new area by original area for a rational surrogate of population
(new area / original area) * population = number of population effected
population = 1,111
original area = 2,500 sq units
new area = 1,200 sq units
1200 / 2500 = .48 (48% of the original area, so 48% of the population)
.48 * 1111 = 533 (real number of population)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joe,
In terms of calculating population, this is exactly what I've done actually! Good to know I'm doing the same thing as others. In respect to using Intersect instead of Union, I seem to get the exact same results actually. The only difference is it seems to process much faster (in the sample set of data I used, 4 seconds instead of 2 minutes!!!). Likely won't solve my problem, but could certainly come in handy in whatever solution I end up using. So thanks!