- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- How to dissolve features and retain fields/values
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to dissolve features and retain fields/values
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
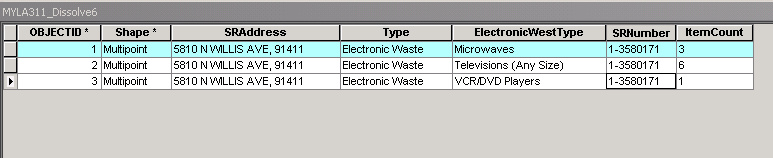
I have a feature class with 3 point features, I would like to dissolve these so that my 3 features maintain all fields and values in one feature.
I would like one feature that has SRAddress, SRNumber, Type, E-WasteType1, Count1, E-WasteType2, Count2, E-WasteType3, Count3
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There's probably a much simpler way to get at this (i.e. a time-saving tool or more efficient use of dictionary, etc.), but here's how you can dump the list of values into a new field ("ItemList"), then dissolve. Note that you'll have to change the feature class name, "Electronic" field name (I was using a shapefile, so couldn't fit long name), and add a text field called "ItemList".
>>> valueList = [] # empty list
... with arcpy.da.SearchCursor("SR_Data",["SRAddress","SRNumber"]) as cursor:
... for row in cursor:
# get all combinations of SRAddress & SRNumber
... valueList.append(row[0]+str(row[1]))
# make unique value set
... valueSet = set(valueList)
# convert set to dictionary keys
... valueDict = dict.fromkeys(valueSet)
... with arcpy.da.SearchCursor("SR_Data",["SRAddress","SRNumber","Electronic","ItemCount"]) as cursor:
... for row in cursor:
# create comma-separated list of values matching each dictionary key
... if not valueDict[row[0]+str(row[1])]:
... valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3])
... else:
... valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3]) + ', ' + str(valueDict[row[0]+str(row[1])])
... with arcpy.da.UpdateCursor("SR_Data",["SRAddress","SRNumber","ItemList"]) as cursor:
... for row in cursor:
# write comma-separated list for each row, matching SRAddress & SRNumber
... row[2] = valueDict[row[0]+str(row[1])]
... cursor.updateRow(row)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Personally, I would crack out the data into a different table and then use a relate.
Is there a specific reason you are using multipoint data?
If you really need it to be a single point with multiple fields, you're going to have to do some table manipulation on your original table, such that you have one record per site and then perform a join into your point feature class and export the joined feature class into yet another feature class.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There's probably a much simpler way to get at this (i.e. a time-saving tool or more efficient use of dictionary, etc.), but here's how you can dump the list of values into a new field ("ItemList"), then dissolve. Note that you'll have to change the feature class name, "Electronic" field name (I was using a shapefile, so couldn't fit long name), and add a text field called "ItemList".
>>> valueList = [] # empty list
... with arcpy.da.SearchCursor("SR_Data",["SRAddress","SRNumber"]) as cursor:
... for row in cursor:
# get all combinations of SRAddress & SRNumber
... valueList.append(row[0]+str(row[1]))
# make unique value set
... valueSet = set(valueList)
# convert set to dictionary keys
... valueDict = dict.fromkeys(valueSet)
... with arcpy.da.SearchCursor("SR_Data",["SRAddress","SRNumber","Electronic","ItemCount"]) as cursor:
... for row in cursor:
# create comma-separated list of values matching each dictionary key
... if not valueDict[row[0]+str(row[1])]:
... valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3])
... else:
... valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3]) + ', ' + str(valueDict[row[0]+str(row[1])])
... with arcpy.da.UpdateCursor("SR_Data",["SRAddress","SRNumber","ItemList"]) as cursor:
... for row in cursor:
# write comma-separated list for each row, matching SRAddress & SRNumber
... row[2] = valueDict[row[0]+str(row[1])]
... cursor.updateRow(row)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Darren, This is the type of solution I was looking for, however, are you suggesting dissolving the itemlist field?? This will only maintain that field. I would one feature with the fields SRAddress, SRNumber, Type, Electronic 1, Count 1, Electronic 2, Count 2, Electronic 3, Count 3, up until 10.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I would dissolve based on SRAddress, SRNumber, Type, and ItemList, which includes electronic 1, count 1, etc. You can dissolve on multiple fields, even if they all match, in order to carry those fields forward.
My code above does not consider Type, but you could add it in amongst the references to SRAddress and SRNumber.
I would not suggest adding new fields for each item and count in ItemList - changing the schema like this causes all kinds of problems. It's easier to parse one defined field into components.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Darren, A couple of questions, I would like to do the same for another field, but there is not always a guaranteed 1-1 relationship between items and comments. Is there a way to implement a loop for the rows instead of using the index? For instance, when I try to insert a comments field and concatenate all comments for the associated request, my output becomes truncated giving me only 1 itemcount and itemtype.
"ListOfLa311ServiceRequestNotes": {
"La311ServiceRequestNotes": [
{
"Comment": "Out on the sidewalk near the curb. Hopefully it is still there.",
"CommentType": "Address Comments",
"CreatedByUser": "MYLATHREEONEONE",
"CreatedDate": "02/17/2015 16:53:26",
"Date1": "",
"Date2": "",
"Date3": "",
"FeedbackSRType": "",
"IntegrationId": "021720151654176661",
"IsSrNoAvailable": "",
"ListOfLa311SrNotesAuditTrail": {},
"Notification": "N",
"Text1": ""
},
{
"Comment": "So glad to get rid of this old junk. Thanks.",
"CommentType": "External",
"CreatedByUser": "MYLATHREEONEONE",
"CreatedDate": "02/17/2015 16:53:26",
"Date1": "",
"Date2": "",
"Date3": "",
"FeedbackSRType": "",
"IntegrationId": "021720151654176662",
"IsSrNoAvailable": "",
"ListOfLa311SrNotesAuditTrail": {},
"Notification": "N",
"Text1": ""
}
]
},

import json
import jsonpickle
import requests
import arcpy
fc = "C:\MYLATesting.gdb\MYLA311"
if arcpy.Exists(fc):
arcpy.Delete_management(fc)
ListTable ="C:\MYLATesting.gdb\MYLA311Dissolve"
if arcpy.Exists(ListTable):
arcpy.Delete_management(ListTable)
f2 = open('C:\Users\Administrator\Desktop\DetailView.json', 'r')
data2 = jsonpickle.encode( jsonpickle.decode(f2.read()) )
url2 = "myURL"
headers2 = {'Content-type': 'text/plain', 'Accept': '/'}
r2 = requests.post(url2, data=data2, headers=headers2)
decoded2 = json.loads(r2.text)
items = []
for sr in decoded2['Response']['ListOfServiceRequest']['ServiceRequest']:
SRAddress = sr['SRAddress']
latitude = sr['Latitude']
longitude = sr['Longitude']
SRNumber = sr['SRNumber']
FirstName = sr['FirstName']
LastName = sr['LastName']
HomePhone = sr['HomePhone']
for ew in sr["ListOfLa311ElectronicWaste"][u"La311ElectronicWaste"]:
CommodityType = ew['Type']
ItemType = ew['ElectronicWestType']
ItemCount = ew['ItemCount']
for comm in sr["ListOfLa311ServiceRequestNotes"][u"La311ServiceRequestNotes"]:
Comment = comm['Comment']
items.append((SRAddress,
latitude,
longitude,
CommodityType,
ItemType,
SRNumber,
ItemCount,
FirstName,
LastName,
Comment,
HomePhone))
import numpy as np #NOTE THIS
dt = np.dtype([('SRAddress', 'U40'),
('latitude', '<f8'),
('longitude', '<f8'),
('Type', 'U40'),
('ElectronicWestType', 'U40'),
('SRNumber', 'U40'),
('ItemCount', 'U40'),
('FirstName', 'U40'),
('LastName', 'U40'),
('Comment', 'U40'),
('HomePhone', 'U40')])
arr = np.array(items,dtype=dt)
sr = arcpy.SpatialReference(4326)
arcpy.da.NumPyArrayToFeatureClass(arr, fc, ['longitude', 'latitude'], sr )
arcpy.AddField_management(fc, "SRList", "TEXT", 255)
arcpy.AddField_management(fc, "Comments", "TEXT", 255)
valueList = [] # empty list
with arcpy.da.SearchCursor(fc,["SRAddress","SRNumber"]) as cursor:
for row in cursor:
# get all combinations of SRAddress & SRNumber
valueList.append(row[0]+str(row[1]))
# make unique value set
valueSet = set(valueList)
# convert set to dictionary keys
valueDict = dict.fromkeys(valueSet)
with arcpy.da.SearchCursor(fc,["SRAddress","SRNumber","ElectronicWestType","ItemCount", "Comment"]) as cursor:
for row in cursor:
# create comma-separated list of values matching each dictionary key
if not valueDict[row[0]+str(row[1])]:
valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3])
else:
valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3]) + ', ' + str(valueDict[row[0]+str(row[1])])
with arcpy.da.UpdateCursor(fc,["SRAddress","SRNumber","SRList"]) as cursor:
for row in cursor:
# write comma-separated list for each row, matching SRAddress & SRNumber
row[2] = valueDict[row[0]+str(row[1])]
cursor.updateRow(row)
arcpy.Dissolve_management(fc, "C:\MYLATesting.gdb\MYLA311Dissolve", ["SRNumber", "SRAddress", "Type", "SRList", "FirstName", "LastName", "HomePhone", "Comment"])
print json.dumps(decoded2, sort_keys=True, indent=4)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
When running your code and switching the parameters, I receive an error that says
line 29, in <module> cursor.updateRow(row) StopIteration: iteration not started
import arcpy fc = "C:\MYLATesting.gdb\MYLA311" valueList = [] # empty list with arcpy.da.SearchCursor(fc,["SRAddress","SRNumber"]) as cursor: for row in cursor: # get all combinations of SRAddress & SRNumber valueList.append(row[0]+str(row[1])) # make unique value set valueSet = set(valueList) # convert set to dictionary keys valueDict = dict.fromkeys(valueSet) with arcpy.da.SearchCursor(fc,["SRAddress","SRNumber","ElectronicWestType","ItemCount"]) as cursor: for row in cursor: # create comma-separated list of values matching each dictionary key if not valueDict[row[0]+str(row[1])]: valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3]) else: valueDict[row[0]+str(row[1])] = str(row[2]) + ', ' + str(row[3]) + ', ' + str(valueDict[row[0]+str(row[1])]) with arcpy.da.UpdateCursor(fc,["SRAddress","SRNumber","ItemList"]) as cursor: for row in cursor: # write comma-separated list for each row, matching SRAddress & SRNumber row[2] = valueDict[row[0]+str(row[1])] cursor.updateRow(row)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Make sure the line "cursor.updateRow(row)" is at the same indentation level as the previous line ("row[2] = ...").
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Darren, I marked your question correct as it does answer part of it that I really didn't specify. Please see the end of this thread for clarification. https://community.esri.com/message/459452?et=watches.email.thread#459452