- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Re: Frequency missing a case field
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A task I find myself having to do requires functionality that existed in ArcInfo Workstation's FREQUENCY command. That tool worked pretty much like the ArcGIS Frequency tool except there was an option for a {case_field} that would be added to the input table to make it easy to join the frequency table to the input table later using a single case field.
Does anyone have a cookbook example of how to generate such a case field in the input table for each unique combination found?
Thanks.
(Posted early 2011; updated 5/2015)
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
No, he can't. Summary Statistics adds nothing to the source and output data that permits a standard many-to-one join to work when a multi-field case field key is used. He wants a single field to represent the unique combination of values from 2 or more fields in both the source and output data so that a standard join will work to create an in memory many-to-one tableview.
To do what he wants there is no help from Esri other than the failed Make Query Table tool (its performance is unacceptably bad and it does not support outer joins or work between different geodatabases or data directories like a standard join does). So each user is left on their own to write their own program to use a dictionary and cursor to track the multi-field unique values and write back an ID to both the source and output data (with no interface that makes their code reusable for other data source/field combinations), or create their own field that contains the concatenation of all of the values that make up the multi-field key to be able to do such a join (the option I normally use if I can modify the source data).
I have written programs that can match multi-field keys using dictionaries and cursors and create a join field that does what he wants, but I have never developed the code to support a tool interface that can be added to a geoprocessing workflow that would allow the user to configure any input source, output table names and field configurations they want without having to do any code modifications. However, I have been thinking more and more that perhaps I should try. However, I do not think I will make the tool do the frequency or summary, just add the single join field to two data sources that share a multi-field match after such outputs are created. That way it will work no matter how the two data sources were created or even if the sources share a many-to-many relationship.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can't you just use summary statistics instead?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
No, he can't. Summary Statistics adds nothing to the source and output data that permits a standard many-to-one join to work when a multi-field case field key is used. He wants a single field to represent the unique combination of values from 2 or more fields in both the source and output data so that a standard join will work to create an in memory many-to-one tableview.
To do what he wants there is no help from Esri other than the failed Make Query Table tool (its performance is unacceptably bad and it does not support outer joins or work between different geodatabases or data directories like a standard join does). So each user is left on their own to write their own program to use a dictionary and cursor to track the multi-field unique values and write back an ID to both the source and output data (with no interface that makes their code reusable for other data source/field combinations), or create their own field that contains the concatenation of all of the values that make up the multi-field key to be able to do such a join (the option I normally use if I can modify the source data).
I have written programs that can match multi-field keys using dictionaries and cursors and create a join field that does what he wants, but I have never developed the code to support a tool interface that can be added to a geoprocessing workflow that would allow the user to configure any input source, output table names and field configurations they want without having to do any code modifications. However, I have been thinking more and more that perhaps I should try. However, I do not think I will make the tool do the frequency or summary, just add the single join field to two data sources that share a multi-field match after such outputs are created. That way it will work no matter how the two data sources were created or even if the sources share a many-to-many relationship.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Like Richard Fairhurst I have had to solve this problem and indeed created some tools that solve this problem as multiple-field joins are not supported in ArcGIS. Hadn't thought of doing this with a python dictionary, I was thinking more of doing this with a lists and sets. I'm sure there are dozens of ways of doing this.
Sephe Fox the dates are messed up because I've been going back and updating/formatting/renaming titles/placing my old content to make them easier to find in Geonet.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Edit: May 30, 2015 - 5:10 AM PST - Added an Ascending or Descending Sort Order column to order the values of each field in the Case field list so that the sequence order of the Case ID numbers can be fully controlled.
Edit: May 22, 2015 - 11:44 PM PST - Improved speed of the code for the Intersect option.
Edit: May 22, 2015 - 4:16 PM PST - Changed code to allow for 3 different options for assigning unique Case ID numbers to the tables. It now allow you to assign them to all Primary Table Case Keys (Default), all Case Keys in both Tables (Union), or only to Case Key found in both tables (Intersection).
Edit: May 19, 2015 - 1:50 PM PST - Updated code and attachment to correctly handle 3 or more case fields.
Edit: May 9, 2015 9:15 PM PST - Fixed error in toolbox code for unmatched case values in Secondary Table. Attached updated toolbox.
I have created a Python toolbox tool that is doing almost everything I want. The zipped python toolbox attached was designed in ArcGIS 10.3, but hopefully it will run in lower versions. The toolbox should be placed in the "%APPDATA%\ESRI\Desktop10.[3]\ArcToolbox\My Toolboxes" folder in Windows 7 (modify the items in brackets to fit your Desktop version of 10.3 or higher).
I use python lists and itertools to get my sorted unique list of multiple field key values and to generate the sequential numbers associated with each key, but I convert the list into a dictionary prior to running the updateCursor so that I gain the speed or dictionary random access matching when I am writing the Case ID number values back to the data sources. Dictionary key matching is much faster than trying to locate matching items in a list. Here is the interface:
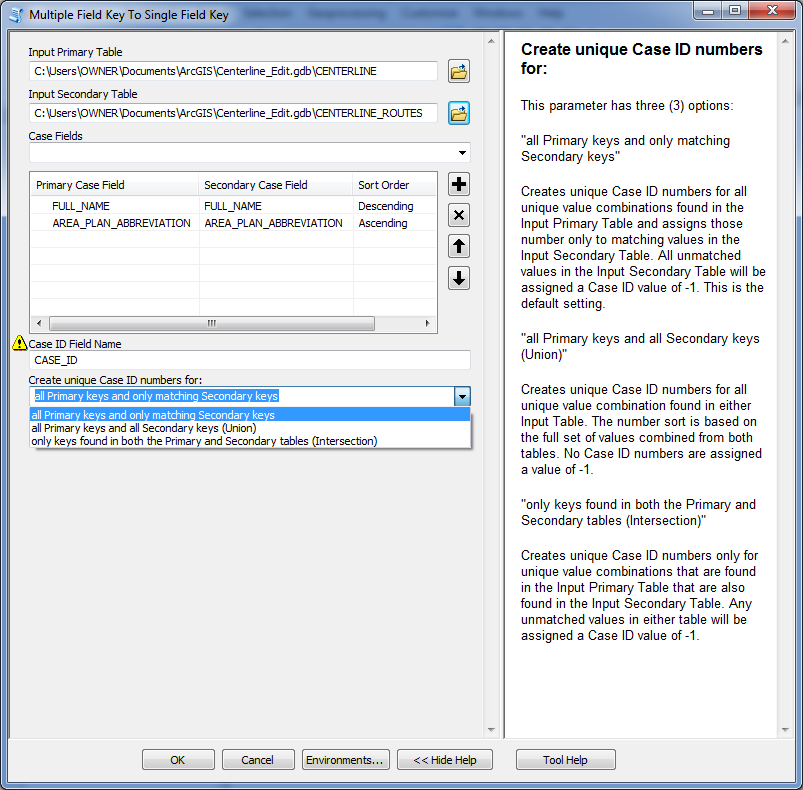
The validation works to make sure that the two input data sources are not the same and that the fields used in the case field list are actually in both sources. The user can choose as many fields as they want to make up their unique multiple field case value keys. The field names do not have to be the same in both data sources. The position of the fields in the list will control the sort priority of the Case Fields (highest priority = top field) and the Sort Order column controls whether the values in each field are sorted in Ascending or Descending order. The sort order of the Case field values controls the Case ID number sequencing. The arrangement of the fields can be different from the field arrangement actually used in the sources.
However, I am having a problem that I cannot seem to solve. I cannot seem to get the schema additionalFields parameter to update the field list for my outputs so that the Case ID field is shown in ModelBuilder if the field doesn't exist and is being added to the data sources by the tool. Does anyone know how to make that work or spot what I am doing wrong?
Anyway, here is my code:
import arcpy
class Toolbox(object):
def __init__(self):
"""Define the toolbox (the name of the toolbox is the name of the
.pyt file)."""
self.label = "Field Match Tools"
self.alias = ""
# List of tool classes associated with this toolbox
self.tools = [MultiFieldKeyToSingleFieldKey]
class MultiFieldKeyToSingleFieldKey(object):
def __init__(self):
"""Define the tool (tool name is the name of the class)."""
self.label = "Multiple Field Key To Single Field Key"
self.description = ""
self.canRunInBackground = False
def getParameterInfo(self):
"""Define parameter definitions"""
# First parameter
param0 = arcpy.Parameter(
displayName="Input Primary Table",
name="in_prim_table",
datatype="DETable",
parameterType="Required",
direction="Input")
# Second parameter
param1 = arcpy.Parameter(
displayName="Input Secondary Table",
name="in_sec_table",
datatype="DETable",
parameterType="Required",
direction="Input")
# Third parameter
param2 = arcpy.Parameter(
displayName="Case Fields",
name="case_fields",
datatype="GPValueTable",
parameterType="Required",
direction="Input")
param2.columns = [['GPString', 'Primary Case Field'], ['GPString', 'Secondary Case Field'], ['GPString', 'Sort Order']]
param2.filters[0].type="ValueList"
param2.filters[0].list = ["X"]
param2.filters[1].type="ValueList"
param2.filters[1].list=["x"]
param2.filters[2].type="ValueList"
param2.filters[2].list=["Ascending", "Descending"]
param2.parameterDependencies = [param0.name]
# Fourth parameter
param3 = arcpy.Parameter(
displayName="Case ID Field Name",
name="in_Case_ID_field",
datatype="GPString",
parameterType="Required",
direction="Input")
param3.value = "CASE_ID"
# Fifth parameter
param4 = arcpy.Parameter(
displayName="Create unique Case ID numbers for:",
name="case_key_combo_type",
datatype="GPString",
parameterType="Required",
direction="Input")
param4.filter.type = "valueList"
param4.filter.list = ["all Primary keys and only matching Secondary keys","all Primary keys and all Secondary keys (Union)","only keys found in both the Primary and Secondary tables (Intersection)"]
param4.value = "all Primary keys and only matching Secondary keys"
newField = arcpy.Field()
newField.name = param3.value
newField.type = "LONG"
newField.precision = 10
newField.aliasName = param3.value
newField.isNullable = "NULLABLE"
# Fifth parameter
param5 = arcpy.Parameter(
displayName="Output Primary Table",
name="out_prim_table",
datatype="DETable",
parameterType="Derived",
direction="Output")
param5.parameterDependencies = [param0.name]
param5.schema.clone = True
param5.schema.additionalFields = [newField]
# Sixth parameter
param6 = arcpy.Parameter(
displayName="Output Secondary Table",
name="out_sec_table",
datatype="DETable",
parameterType="Derived",
direction="Output")
param6.parameterDependencies = [param1.name]
param6.schema.clone = True
param6.schema.additionalFields = [newField]
params = [param0, param1, param2, param3, param4, param5, param6]
return params
def isLicensed(self):
"""Set whether tool is licensed to execute."""
return True
def updateParameters(self, parameters):
"""Modify the values and properties of parameters before internal
validation is performed. This method is called whenever a parameter
has been changed."""
if parameters[0].value:
# Return primary table
tbl = parameters[0].value
desc = arcpy.Describe(tbl)
fields = desc.fields
l=[]
for f in fields:
if f.type in ["String", "Text", "Short", "Long", "Float", "Single", "Double", "Integer","OID", "GUID"]:
l.append(f.name)
parameters[2].filters[0].list = l
if parameters[1].value:
# Return secondary table
tbl = parameters[1].value
desc = arcpy.Describe(tbl)
fields = desc.fields
l=[]
for f in fields:
if f.type in ["String", "Text", "Short", "Long", "Float", "Single", "Double", "Integer","OID", "GUID"]:
l.append(f.name)
parameters[2].filters[1].list = l
if parameters[2].value != None:
mylist = parameters[2].value
for i, e in list(enumerate(mylist)):
if mylist[2] != "Descending":
mylist[2] = "Ascending"
parameters[2].value = mylist
return
def updateMessages(self, parameters):
"""Modify the messages created by internal validation for each tool
parameter. This method is called after internal validation."""
if parameters[3].value and parameters[0].value and parameters[1].value:
desc = arcpy.Describe(parameters[0].value)
fields = desc.fields
in_primary = False
is_primary_error = False
is_primary_uneditable = False
for f in fields:
if parameters[3].value.upper() == f.name.upper():
in_primary = True
if f.type != "Integer":
is_primary_error = True
elif not f.editable:
is_primary_uneditable = False
desc2 = arcpy.Describe(parameters[1].value)
fields2 = desc2.fields
in_secondary = False
is_secondary_error = False
is_secondary_uneditable = False
for f2 in fields2:
if parameters[3].value.upper() == f2.name.upper():
in_secondary = True
if f2.type != "Integer":
is_secondary_error = True
elif not f2.editable:
is_secondary_uneditable = False
newField = arcpy.Field()
newField.name = parameters[3].value
newField.type = "LONG"
newField.precision = 10
newField.aliasName = parameters[3].value
newField.isNullable = "NULLABLE"
fields1 = []
fields2 = []
order = []
for item in parameters[2].value:
fields1.append(item[0].upper())
fields2.append(item[1].upper())
order.append(item[2])
if str(parameters[0].value).upper() == str(parameters[1].value).upper():
parameters[1].setErrorMessage("The Input Secondary Table {0} cannot be the same as the Input Primary Table {1} ".format(parameters[1].value, parameters[0].value))
else:
parameters[1].clearMessage()
if in_primary and in_secondary:
if is_primary_error and is_secondary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif is_primary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Primary Table".format(parameters[3].value.upper()))
elif is_secondary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Secondary Table".format(parameters[3].value.upper()))
elif parameters[3].value.upper() in fields1 and parameters[3].value.upper() in fields2:
parameters[3].setErrorMessage("{0} is used as a Case Field for both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif parameters[3].value.upper() in fields1:
parameters[3].setErrorMessage("{0} is used as a Case Field for the Input Primary Table".format(parameters[3].value.upper()))
elif parameters[3].value.upper() in fields2:
parameters[3].setErrorMessage("{0} is used as a Case Field for the Input Secondary Table".format(parameters[3].value.upper()))
elif is_primary_uneditable and is_secondary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif is_primary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Primary Table".format(parameters[3].value.upper()))
elif is_secondary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Secondary Table".format(parameters[3].value.upper()))
else:
parameters[3].setWarningMessage("{0} will be overwritten in both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif in_primary:
parameters[6].schema.additionalFields = [newField]
if is_primary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Primary Table".format(parameters[3].value.upper()))
elif is_primary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Primary Table".format(parameters[3].value.upper()))
else:
parameters[3].setWarningMessage("{0} will be overwritten in the Input Primary Table".format(parameters[3].value.upper()))
elif in_secondary:
parameters[5].schema.additionalFields = [newField]
if is_secondary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Secondary Table".format(parameters[3].value.upper()))
elif is_secondary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Secondary Table".format(parameters[3].value.upper()))
else:
parameters[3].setWarningMessage("{0} will be overwritten in the Input Secondary Table".format(parameters[3].value.upper()))
else:
parameters[5].schema.additionalFields = [newField]
parameters[6].schema.additionalFields = [newField]
parameters[3].clearMessage()
return
def execute(self, parameters, messages):
"""The source code of the tool."""
try:
desc = arcpy.Describe(parameters[0].value)
fields = desc.fields
in_primary = False
for f in fields:
if parameters[3].value.upper() == f.name.upper():
in_primary = True
if not in_primary:
arcpy.AddField_management(parameters[0].value, parameters[3].value.upper(), "Long", 10)
arcpy.AddMessage("Added a Case ID field to the Input Primary Table")
desc2 = arcpy.Describe(parameters[1].value)
fields2 = desc2.fields
in_secondary = False
for f2 in fields2:
if parameters[3].value.upper() == f2.name.upper():
in_secondary = True
if not in_secondary:
arcpy.AddField_management(parameters[1].value, parameters[3].value.upper(), "Long", 10)
arcpy.AddMessage("Added a Case ID field to the Input Secondary Table")
tbl1 = parameters[0].value
tbl2 = parameters[1].value
fields1 = []
fields2 = []
order = []
for item in parameters[2].value:
fields1.append(item[0])
fields2.append(item[1])
order.append(item[2])
arcpy.AddMessage("Primary Case Fields are {0}".format(str(fields1)))
arcpy.AddMessage("Secondary Case Fields are {0}".format(str(fields2)))
arcpy.AddMessage("Sort Orders are {0}".format(str(order)))
import itertools
k = list((r[0:]) for r in arcpy.da.SearchCursor(tbl1, fields1))
arcpy.AddMessage("Case Values have been read from the Input Primary Table")
if parameters[4].value == "all Primary keys and all Secondary keys (Union)":
j = list((r[0:]) for r in arcpy.da.SearchCursor(tbl2, fields2))
k = k + j
j = None
arcpy.AddMessage("Case Values have been appended from the Input Secondary Table")
from operator import itemgetter
for i, e in reversed(list(enumerate(order))):
if order == "Descending":
k.sort(key=itemgetter(i), reverse=True)
else:
k.sort(key=itemgetter(i))
k = list(k for k,_ in itertools.groupby(k))
if parameters[4].value == "only keys found in both the Primary and Secondary tables (Intersection)":
j = {tuple(r[0:]):1 for r in arcpy.da.SearchCursor(tbl2, fields2)}
arcpy.AddMessage("Case Values have been read from the Input Secondary Table")
l = []
for item in k:
if tuple(item) in j:
l.append(item)
j = None
k = l
l = None
arcpy.AddMessage("Case Values have been matched to the Input Secondary Table")
arcpy.AddMessage("A list of sorted and unique Case Values has been created")
dict = {}
fields1.append(parameters[3].value)
fields2.append(parameters[3].value)
for i in xrange(len(k)):
dict[tuple(k)] = i + 1
k = None
arcpy.AddMessage("A dictionary of unique Case Value keys with Case ID number values has been created")
with arcpy.da.UpdateCursor(tbl1, fields1) as cursor:
for row in cursor:
if tuple(row[0:len(fields2)-1]) in dict:
row[len(fields1)-1] = dict[tuple(row[0:len(fields1)-1])]
else:
row[len(fields2)-1] = -1
cursor.updateRow(row)
del cursor
arcpy.AddMessage("{0} values have been updated for Input Primary Table".format(parameters[3].value))
with arcpy.da.UpdateCursor(tbl2, fields2) as cursor2:
for row2 in cursor2:
if tuple(row2[0:len(fields2)-1]) in dict:
row2[len(fields2)-1] = dict[tuple(row2[0:len(fields2)-1])]
else:
row2[len(fields2)-1] = -1
cursor2.updateRow(row2)
del cursor2
arcpy.AddMessage("{0} values have been updated for Input Secondary Table".format(parameters[3].value))
except Exception as e:
messages.addErrorMessage(e.message)
return
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Using My Toolbox is just convenient; you can run it anywhere you want right?
Thanks for the awesome .pyt template, if nothing else!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Note, this toolbox does not run at 10.2.2. The the .filters parameter is new at 10.3. (I will be waiting for 10.3.1 before updating.)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Too bad that the .filters parameter is only available at 10.3. I have 10.2.2 at work, but it may be a while before I have time to experiment with that version. If you come up with any alternative code to do what that parameter is doing (adding the pick lists of fields to the GPValueTable) let me know.
I was thinking of adding applicable SHAPE@ tokens to the end of the field lists for tables with a geometry field, either by default or with a Boolean option. That way matching of two data sources could be done on geometry values like X and Y coordinates without having to first calculate the coordinates into double fields.
Any thoughts on the code involving the schema.additionalFields that is failing to get ModelBuilder to recognize the new field added by the tool? I have tried several versions of where to place it in my logic, but nothing I have tried worked. I guess I will have to try designing a much simpler tool that just adds a field to a data source to see if I can make it work at all. It seems like it may be a bug.