- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Assigning names to contiguous line segments
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have hundreds of polylines across the US, with each polyline consisting of 10 to 100 segments. One segment in each line has a name field. I want to assign the name in a given segment to all other segments in the same line. I can't use a spatial join and assign the name of the closest segment, as it may assign the name from a nearby line, not the line segment in the same line. I can use a spatial join and assign the name of touching segments, but I would have to repeat this process 100 times if a line has 100 segments. Any suggestions on how to make this process quicker?
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Most likely you have bad topology control and your tolerance is too precise for the level of accuracy that was maintained during the creation of this data. Unless line ends precisely meet they will not merge together the way you want.
If you have a Standard license or above you could try the Snap tool in the Editor toolset to try to get the ends to snap together. You should just use the Ends option to snap the line ends only. This tool directly modifies your original lines, so make a backup in case things go wrong and process it in an Editor session so you can undo your attempts and try different tolerances. Once your lines are topologically accurate to the tolerance setting of your data, the Dissolve ends option should work.
Additionally, be sure you leave all of the Dissolve fields unchecked. You must not allow any attributes to affect the dissolve. Only summary statistics fields should be used. If you do not include any summary statistics fields your output should have no fields other than ObjectID and Shape.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Does each shapefile or FC have only one line in it? Or are there hundreds of lines in each FC/shapefile? I am guessing that each segment has on row in the attribute table. Does each segment have a field with a line name? Maybe you could post a screenshot of the table if it is not sensitive information....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
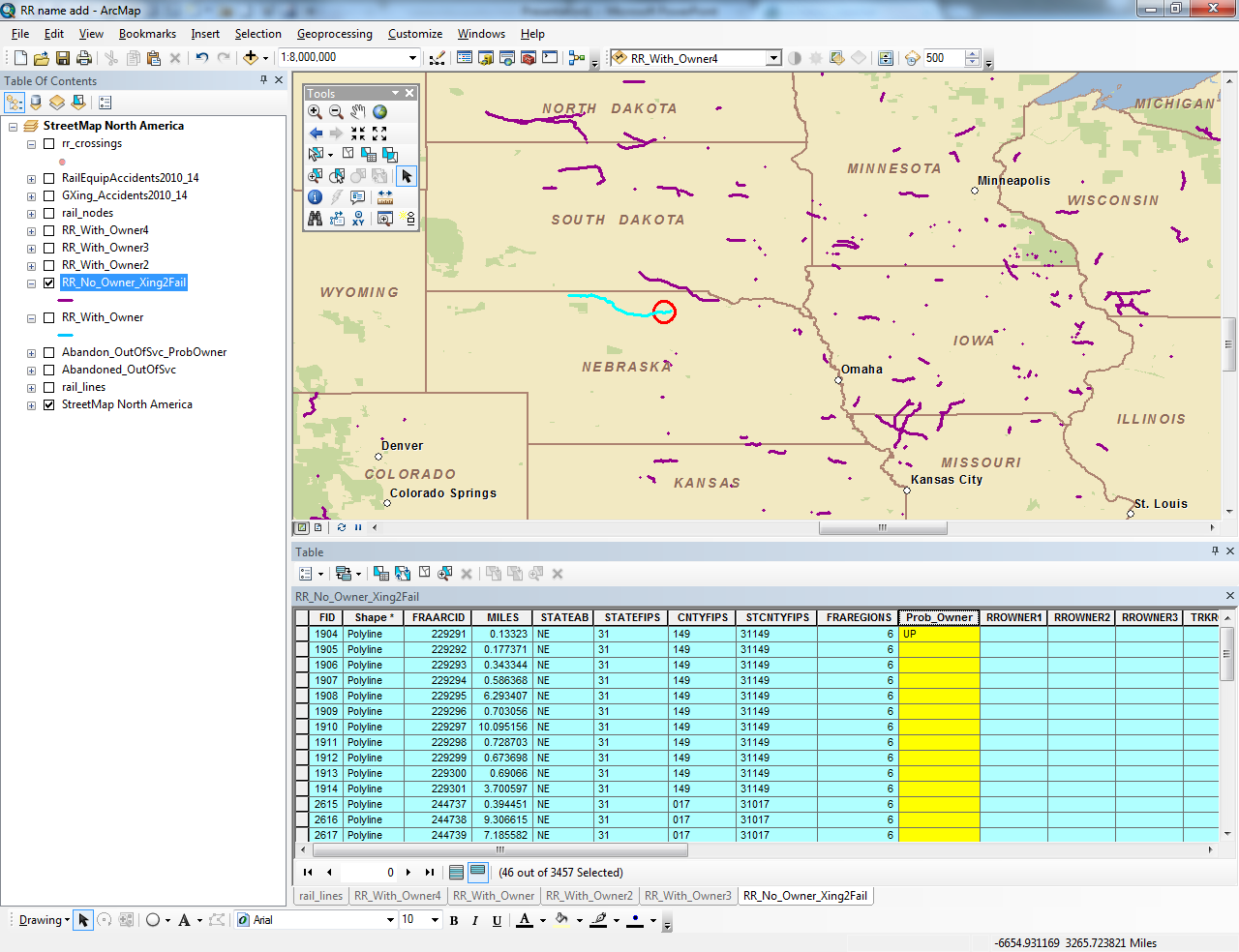
There are multiple segments in each line. The map provided shows the various lines around the country I'm dealing with. I have selected one line in northern Nebraska with 46 segments, and circled one segment which has a name associated with it (the Prob_Owner field). I want to assign this name to all other segments in this line. Bear in mind I need to do this for hundreds of lines across the US as shown in the map, so the solution will, ideally, allow me to do this efficiently.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I see so each line is contiguous and each has many sub segments. But there is no attribute to tie the line segments together - such as a line name? So one would have to use some sort of spatial operations to understand how the segments relate to a line. Just trying to understand the problem....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Precisely! Well said.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You could first Merge all line segments together without attributes and require that lines must join end to end in order to merge. Calculate a long field named Parts with the following Python calculation to get a part count for each merged line: !Shape.partCount! If no crossing lines exist and the lines actually meet end to end, then a single line will be created for all contiguous original line segments in a linear sequence and they will have a single part. A spatial join of your original lines that actually have a name to the merged lines would show if more than one name was associated to the merged line (use One-to-One with the Join Merge Rule for the name field and a semi-colon delimiter). If only one name exists for the line, you can spatial join the original lines to that merged line and transfer the name attribute to all of the segments that make up that line.
If for some reason more than one name is associated to a merged single line that is a single part line, the Name field would have a semi-colon in the name list. You would have to determine where the name changed manually based on other information or further research.
Where more than two segments meet end to end to form branching lines the part count will be 2 or more. The spatial join I recommended would tell you if only one name was associated to the branching line set, and in cases where that is true you could transfer the name attribute the same as if it was a single part line with one name.
However, if more than one name was associated with a branching line set, use the Multi-part to single-part tool to divide the merged line into single part lines. While I could write a program to get the bearing of the line segment at each line end to determine the lines that probably should join, you probably still should manually evaluate these lines that intersect no matter what to determine which alignments actually should join together through the intersection. Once you get a single part line assembled, then find the named segment associated with it and you can use it to transfer the name to the original lines. The intersections will complicate this, so you may have to buffer these lines and only transfer the attribute to original lines that can be selected using the rule that them must entirely fit in the buffer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard, just curious how to limit merged line segments to those that are touching. Are you referring to the edit merge tool, or Merge geoprocessing tool, or neither?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Actually, I meant to say use Dissolve with the Unsplit lines option as you have mentioned. I have not used it very often, so some of my recollections on how it behaves may not be entirely correct, but in general the way I described it should be correct. Using the Multipart to singlepart tool may not apply, but more often than not I have to use that tool after using Dissolve.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was unaware of the dissolve with unsplit lines option. That does look like the best option for this part.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
John,
I can think of two potential ways to solve your problem.
1. Use python to to get the end points of the lines. Use how they intersect to populate the Prob_Owner. I did not think it all the way to a solution but it is fully possible and could be fully automated.
2. Use Arc tools. I would suggest the following workflow:
a. Set up topology to highlight all of the areas where the lines intersect.
b. Select by attributes all of the segments that have names: Maybe Prob_Owner LIKE '__%' Export the section to a new FC.
c. Select by hand all of the lines that intersect other lines. Export them to a new FC. Invert the selection and export again. The goal is to have only lines that do not intersect in each FC. (if this is not practical because there are too many of them this solution is problematic. I guess I would goto python at this point or maybe there is a way to efficiently do this selection that I did not think of.)
d. Merge with the editor tool all of the features in one of the FCs from step c so that there is only one record in the FC. Then use explode off the advanced editing tool bar to turn them back in to distinct lines.
e. Spatial Join the output of step d with the the output of step b.
f. Use identify to break the output of step e with the ordinal pipeline data set.
g. Repeat steps as need for the output of step c
h. Merge everything together and clean up.
OK hope that helps