- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- Trim strings at specific point using Field Calcula...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Trim strings at specific point using Field Calculator
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a feature class which contains 40,000 mailing addresses. Each address contains the street address, city, state and zipcode separated by spaces.
Example 1: 123 Northwest Johnson St Cleveland Ohio 12345
Example 2: PO Box 3 Pine Springs Ohio 12345
I want to pull out just the street addresses. How do I say: trim off the string starting at the 3rd or 4th to last space? Thanks. Any help would be appreciated. I'm trying combinations of split, trim, etc. but can't get it right.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Below an example of getting the address without the part from the last space (using the Python parser):
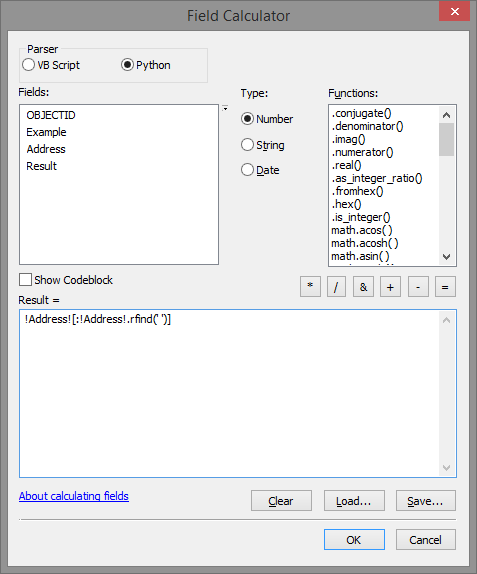
Formula (with "Address" being the name of the field that contains the address string):
!Address![:!Address!.rfind(' ')]
The result:
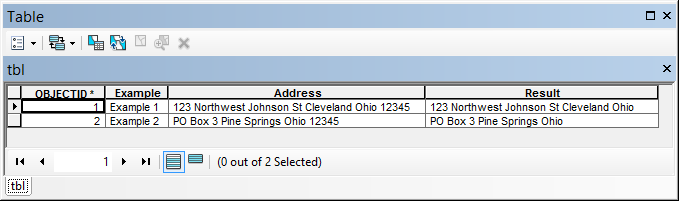
If you can detect the part you want to exclude, it is easy. However if you want to obtain "123 Northwest" or "PO Box 3", there is no easy way to detect the parts you need or those you want to exclude.
Kind regards, Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try This
Mid( [Address],1,13 ) Get 123 Northwest
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If you haven't already tried it, you might be able to accomplish part of what you want with VB Script and the Left, Mid, and Right string functions. Whether this will be usable will depend on how your data is arranged; though from what you have depicted in your examples it would at least allow you to strip the zip code off.
Check out the ESRI help, VBScript string functions section (part way down the page):
Calculate Field Examples
As to culling out the City, that looks a bit trickier, given the variability in name-length of a city and the presence of multiple words for some cities. Off the wall idea - somehow tie in a search to a list of known cities that your data would include to then identify what to remove?
Chris Donohue, GISP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The problem is the variability in contents. Even if you pop() the last two elements (Zip and State) you are still left with a variable length list.
You might want to try filtering the data through a query or queries. One such query might be
[ADDRESS_FIELD] not like 'PO BOX %'. Maybe look for street types as well. These might give you an idea of what you need to do to tease out the data you're after. You need to get acquainted with the data to be able to do such filtering. After all that you'll still have a ton of error trapping the figure out. Sorry, not a lot of help...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Xander and Joe are on the right track...
Examine the address from the perspective of non-standard lengths brought about the uncertain number of spaces separating elements in the address.
>>> #---------------------------------------------------
>>> # parsing non-standard address...problem examination
>>>
>>> address = "123 Northwest Johnson St Cleveland Ohio 12345"
>>> bits = address.split(" ") # split it into its components
>>> bits
['123', 'Northwest', 'Johnson', 'St', 'Cleveland', 'Ohio', '12345']
>>> for fiddly in range(len(bits)): # now lets examine the fiddly bits
... print bits[:-fiddly], "step", fiddly
...
[] step 0
['123', 'Northwest', 'Johnson', 'St', 'Cleveland', 'Ohio'] step 1
['123', 'Northwest', 'Johnson', 'St', 'Cleveland'] step 2
['123', 'Northwest', 'Johnson', 'St'] step 3
['123', 'Northwest', 'Johnson'] step 4
['123', 'Northwest'] step 5
['123'] step 6
>>>
>>> # Now for problem address 2
>>> address = "PO Box 3 Pine Springs Ohio 12345"
>>> bits = address.split(" ") # split it into its components
>>> bits
['PO', 'Box', '3', 'Pine', 'Springs', 'Ohio', '12345']
>>> for fiddly in range(len(bits)): # now lets examine the fiddly bits
... print bits[:-fiddly], "step", fiddly
...
[] step 0
['PO', 'Box', '3', 'Pine', 'Springs', 'Ohio'] step 1
['PO', 'Box', '3', 'Pine', 'Springs'] step 2
['PO', 'Box', '3', 'Pine'] step 3
['PO', 'Box', '3'] step 4
['PO', 'Box'] step 5
['PO'] step 6
>>>
>>> # In address 1 it took until step 3 to get rid of everything
>>> # up to the city level. in address 2 this was completed by step 2...
>>> # Conclusion? Unless the address contain the same number of elements
>>> # it is not possible to parse data in one pass
>>>A good reason to parse during data collection and entry.
Do note... that a screw will be thrown into the works when you start mixing state names which are multipart as well...consider
address = "123 Northwest Johnson St South New York New York 12345" # Now What!!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A different idea - how about this as a possible approach - find an existing dataset of already-parsed addresses that include all the ones you have, then match yours to the parsed ones. Then output the parsed ones and pare down from there. I don't know exactly where you would find the parsed dataset(s), but given the proliferation of address information, geocoding, and the like, I suspect it could be feasible.
Can anyone chime in on where specific sources of such already-parsed datasets could be found?
Also, Derek, to help with this - what States are your addresses in?
Chris Donohue, GISP
[Edit: fixed some typos]
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Have you tried to geocode a sample?
Removind Cleveland Ohio ZIP is going to narrow it down but you are still left with the problem of
'123', 'Northwest', 'Johnson', 'St', ..... being 4 positions in the list
'PO', 'Box', '3', 'Pine', 'Springs', ...... and, this being 5
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dan has a point - maybe try geocoding them. I'm in no ways an expert on Geocoding, but I know there are quite a few geocoding services out there. While you may not necessarily be interested in the coordinate location of your address, the address result may very well be parsed for you as part of the process.
Here's a site I remember people mentioning in a post here on GeoNet several weeks ago.
Texas A&M Geoservices
List of Online Geocoding Systems
There may also be local geocoding services publicly available from government entities in your area. Maybe try the city and county governments of your area of interest.
Chris Donohue, GISP