Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Cancel
- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- ???Select by attributes??? for Arabic fonts in SDE...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
???Select by attributes??? for Arabic fonts in SDE/file geodatabases,
Subscribe
02-21-2013
10:33 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
???Select by attributes??? for Arabic fonts in SDE/file geodatabases,
I have the name of communities in English and Arabic language. Of course, there is no any problem when searching these names in English language whether from the SDE of file goedatabase
I got the same feature class in SDE and file geodatabase
1. Searching the Arabic names in file geodatabase works very well and has no problem
[ATTACH=CONFIG]22050[/ATTACH]
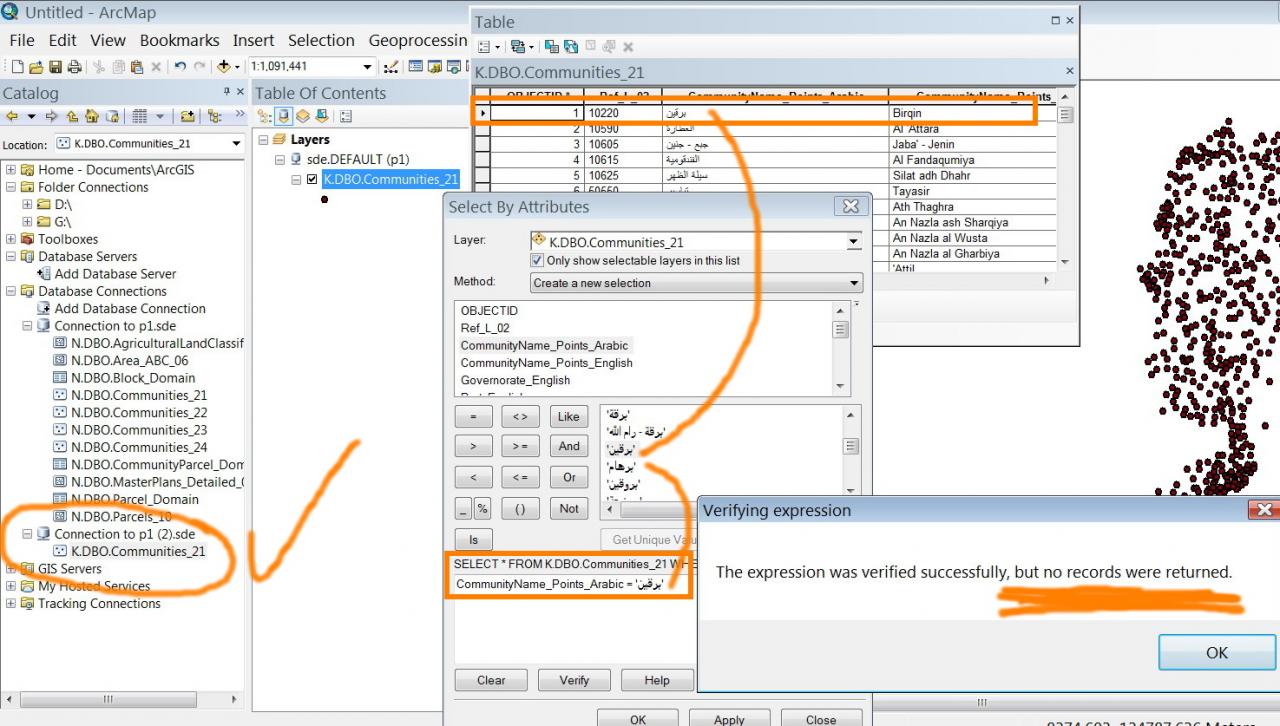
2. Searching the Arabic names from the SDE geodatabase has a problem. It doesn???t recognize Arabic languages and thus ends up with finding nothing.
[ATTACH=CONFIG]22051[/ATTACH]
What might be the issue here?
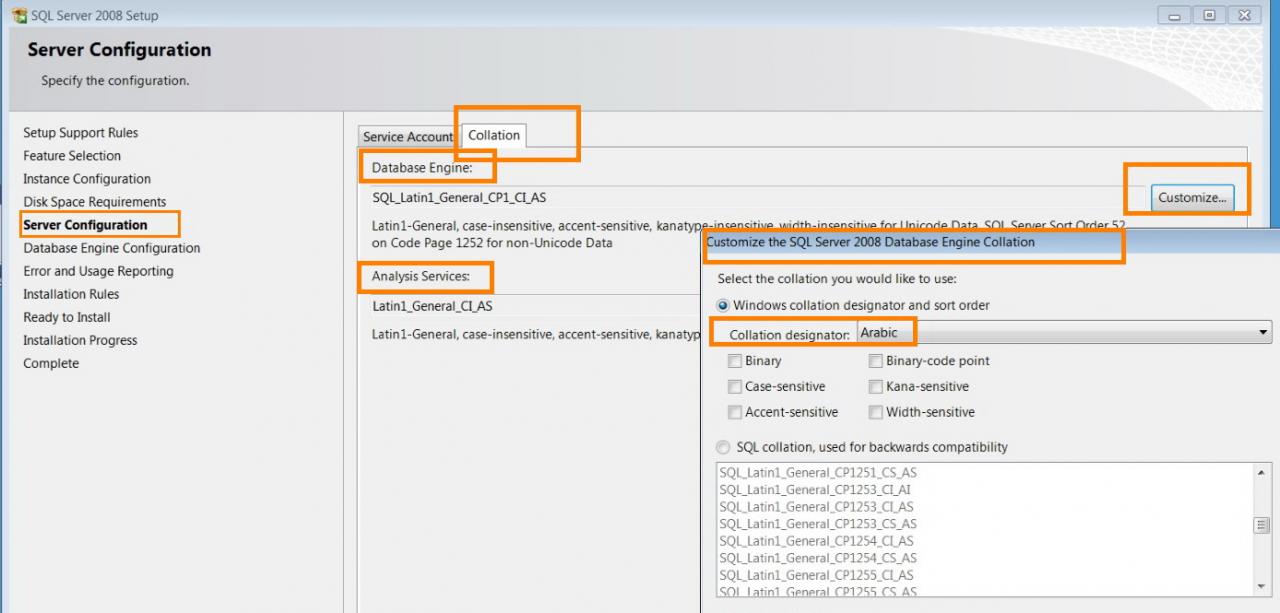
I installed the ???collation designator??? to be Arbaic, nevertheless, Arbaic words are not recognized in the SDE geodatabase and are not searched correctly.
[ATTACH=CONFIG]22052[/ATTACH], [ATTACH=CONFIG]22053[/ATTACH]
What other features need to be set?
Thank you
Best
Jamal
I have the name of communities in English and Arabic language. Of course, there is no any problem when searching these names in English language whether from the SDE of file goedatabase
I got the same feature class in SDE and file geodatabase
1. Searching the Arabic names in file geodatabase works very well and has no problem
[ATTACH=CONFIG]22050[/ATTACH]
2. Searching the Arabic names from the SDE geodatabase has a problem. It doesn???t recognize Arabic languages and thus ends up with finding nothing.
[ATTACH=CONFIG]22051[/ATTACH]
What might be the issue here?
I installed the ???collation designator??? to be Arbaic, nevertheless, Arbaic words are not recognized in the SDE geodatabase and are not searched correctly.
[ATTACH=CONFIG]22052[/ATTACH], [ATTACH=CONFIG]22053[/ATTACH]
What other features need to be set?
Thank you
Best
Jamal
----------------------------------------
Jamal Numan
Geomolg Geoportal for Spatial Information
Ramallah, West Bank, Palestine
Jamal Numan
Geomolg Geoportal for Spatial Information
Ramallah, West Bank, Palestine
Solved! Go to Solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 Solution
Accepted Solutions
02-21-2013
01:28 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You must use the N prefix before the character string when querying unicode data like this
eg.
where name = N'character_string'
This article describes the issue and solution in more detail: http://support.esri.com/en/knowledgebase/techarticles/detail/32474
eg.
where name = N'character_string'
This article describes the issue and solution in more detail: http://support.esri.com/en/knowledgebase/techarticles/detail/32474
15 Replies
by
Anonymous User
Not applicable
02-21-2013
12:40 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Original User: mboeringa2010
Jamal,
This is actually quite outside my knowledge base, and I had to look-up what "collation" in SQL Server actually means, but by doing so, I noticed the following text on this Microsoft site about collation:
"If you do not specify a collation, the default collation for the database is the default collation for the instance. Whenever you define a character column, you can specify its collation. If you do not specify a collation, the column is created with the default collation of the database."
The bold sentence raises a question: did you set the collation after or before adding this dataset to the geodatabase? If you altered collation after the dataset was added to the geodatabase, the column with the arabic characters will still use the old, default, collation if I understand the above text well.
So the recommended order seems to be to first set the collation, than load data in the geodatabase. There is an option to change the collation of an existing column, as specified here, but it seems to have some caveats (like no index on column) that may make it impractical to use on an existing geodatabase Feature Class. Probably best to set the collation first and than load data as I wrote before.
Jamal,
This is actually quite outside my knowledge base, and I had to look-up what "collation" in SQL Server actually means, but by doing so, I noticed the following text on this Microsoft site about collation:
"If you do not specify a collation, the default collation for the database is the default collation for the instance. Whenever you define a character column, you can specify its collation. If you do not specify a collation, the column is created with the default collation of the database."
The bold sentence raises a question: did you set the collation after or before adding this dataset to the geodatabase? If you altered collation after the dataset was added to the geodatabase, the column with the arabic characters will still use the old, default, collation if I understand the above text well.
So the recommended order seems to be to first set the collation, than load data in the geodatabase. There is an option to change the collation of an existing column, as specified here, but it seems to have some caveats (like no index on column) that may make it impractical to use on an existing geodatabase Feature Class. Probably best to set the collation first and than load data as I wrote before.
02-21-2013
01:28 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You must use the N prefix before the character string when querying unicode data like this
eg.
where name = N'character_string'
This article describes the issue and solution in more detail: http://support.esri.com/en/knowledgebase/techarticles/detail/32474
eg.
where name = N'character_string'
This article describes the issue and solution in more detail: http://support.esri.com/en/knowledgebase/techarticles/detail/32474
02-10-2017
09:13 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
shannon search from attribute table doesn't work either, its standard way to write N before uni code string and we know that but i cant figure out why geodatabase that is stored in sql cant find unicode from attribute table form sql writing select statment works fine.
by
Anonymous User
Not applicable
02-21-2013
09:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Original User: [email protected]
Thank you guys for the help. It worked like a charm.
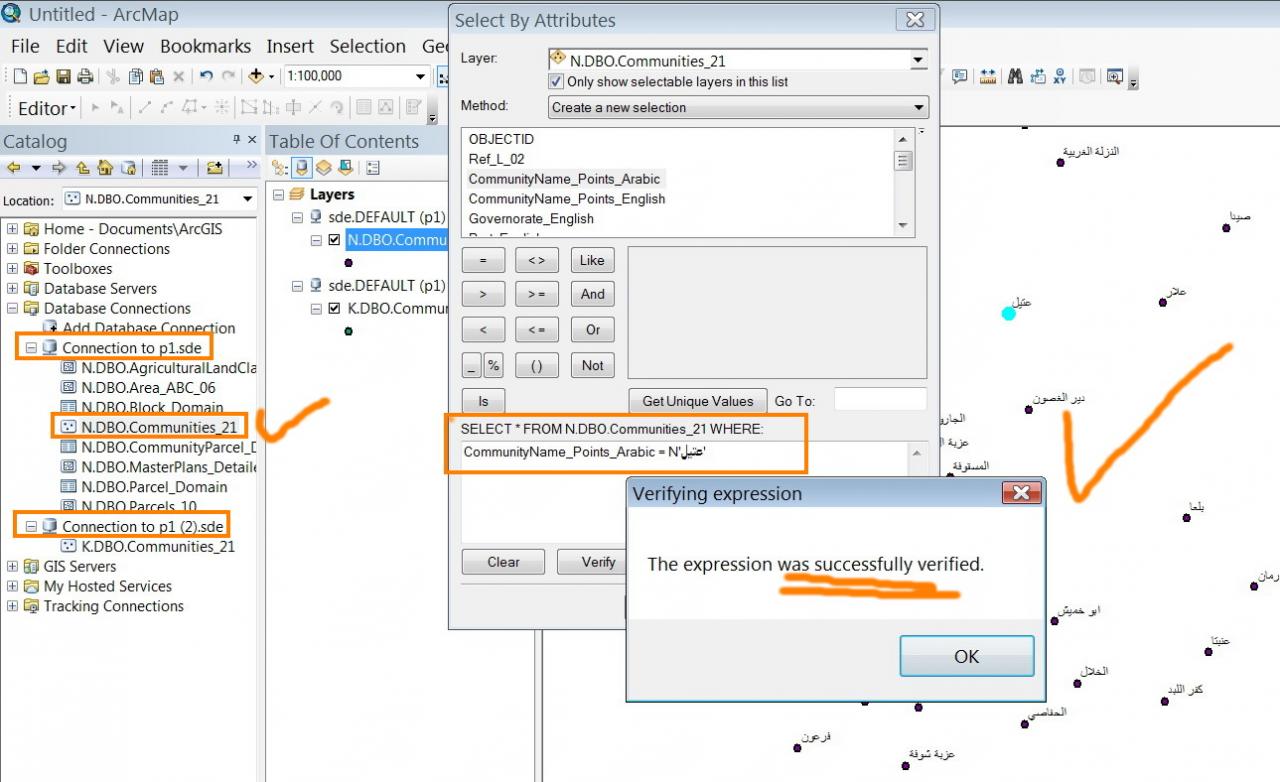
For example, I could select
CommunityName_Points_Arabic = N'عت�?�?'
[ATTACH=CONFIG]22067[/ATTACH]
Using the �??N�?� is sufficient without the need to install the collation designator. What do you think Marco? However, installing the �??Arabic�?� collation might be still needed referring to the fact that my database includes Arabic fonts. It should be necessary to avoid other types of error and weird behaviour.
Best
Jamal
You must use the N prefix before the character string when querying unicode data like this
eg.
where name = N'character_string'
This article describes the issue and solution in more detail: http://support.esri.com/en/knowledgebase/techarticles/detail/32474
Thank you guys for the help. It worked like a charm.
For example, I could select
CommunityName_Points_Arabic = N'عت�?�?'
[ATTACH=CONFIG]22067[/ATTACH]
Using the �??N�?� is sufficient without the need to install the collation designator. What do you think Marco? However, installing the �??Arabic�?� collation might be still needed referring to the fact that my database includes Arabic fonts. It should be necessary to avoid other types of error and weird behaviour.
Best
Jamal
{kind=link}
02-22-2013
02:35 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Using the �??N�?� is sufficient without the need to install the collation designator. What do you think Marco? However, installing the �??Arabic�?� collation might be still needed referring to the fact that my database includes Arabic fonts. It should be necessary to avoid other types of error and weird behaviour.
Best
Jamal
Jamal, I still think it would be worthwhile to set the collation to Arabic and try to re-load the data in your geodatabase (re-loading to force setting of Arabic collation on the Arabic unicode column). If I understand it well, your queries should than not need the "N" prefix, which is more consistent with the normal ArcGIS usage and less confusing to you or your geodatabase users.
As the ArcGIS troubleshooting page also states: "No results are returned by ArcMap unless the SQL Server instance being queried is using a (Thai) locale or collation."
Alternatively, you might still try to change the collation of specifically the Arabic character column in SQL Server Managent Studio by using the ALTER statement against the column, as explained on this page (scroll down to see it under "Column-level collations"):
Collation and International Terminology
Example from the page:
ALTER TABLE myTable ALTER COLUMN mycol NVARCHAR(10) COLLATE Greek_CS_AI
And as you also say, it should potentially give a more consistent behaviour with the sorting of the data in different applications and SQL Server.
There also seem to be some new things with SQL Server 2008 and collations and a recommendation and push by Microsoft to use "BIN2" binary collations by checking the "Binary-code point" checkbox in the dialog you made a screenshot of. See this Microsoft MSDN page under "Binary collations":
Windows Collation Sorting Styles
But anyway, as I wrote before this is all a bit outside my knowledge base. I think Vince or Shannon might be able to give better informed answers on this specific subject.
by
Anonymous User
Not applicable
02-22-2013
03:07 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Original User: [email protected]
Thank you Marco for the input.
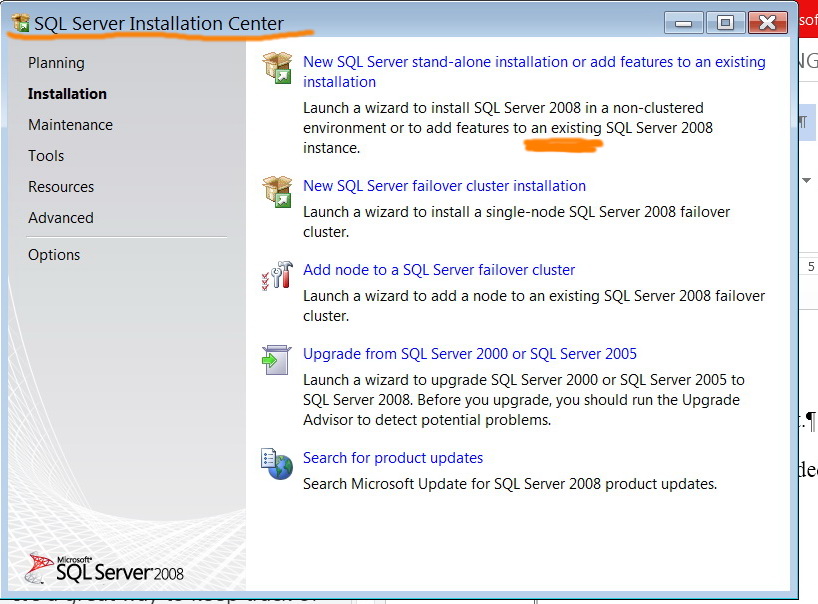
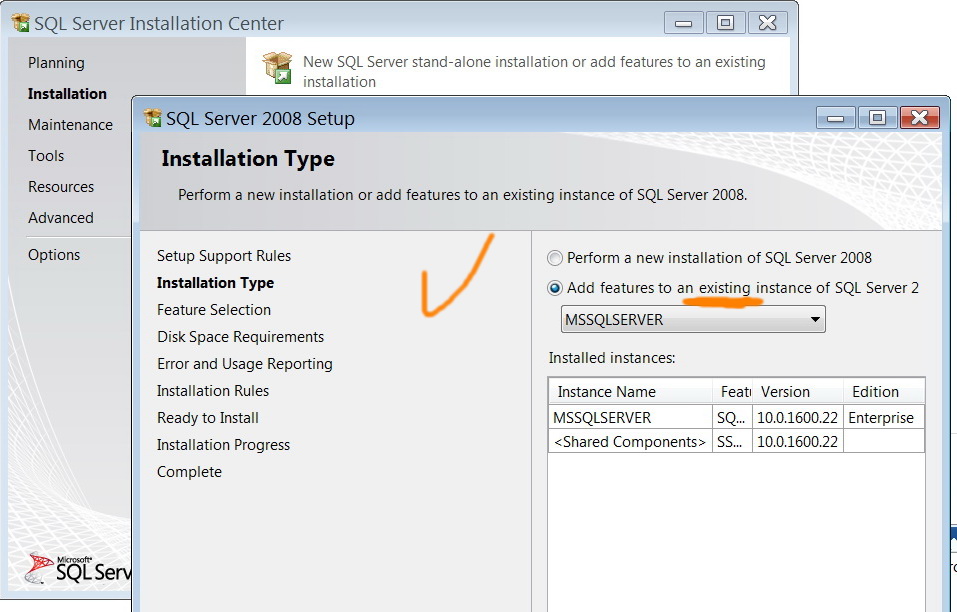
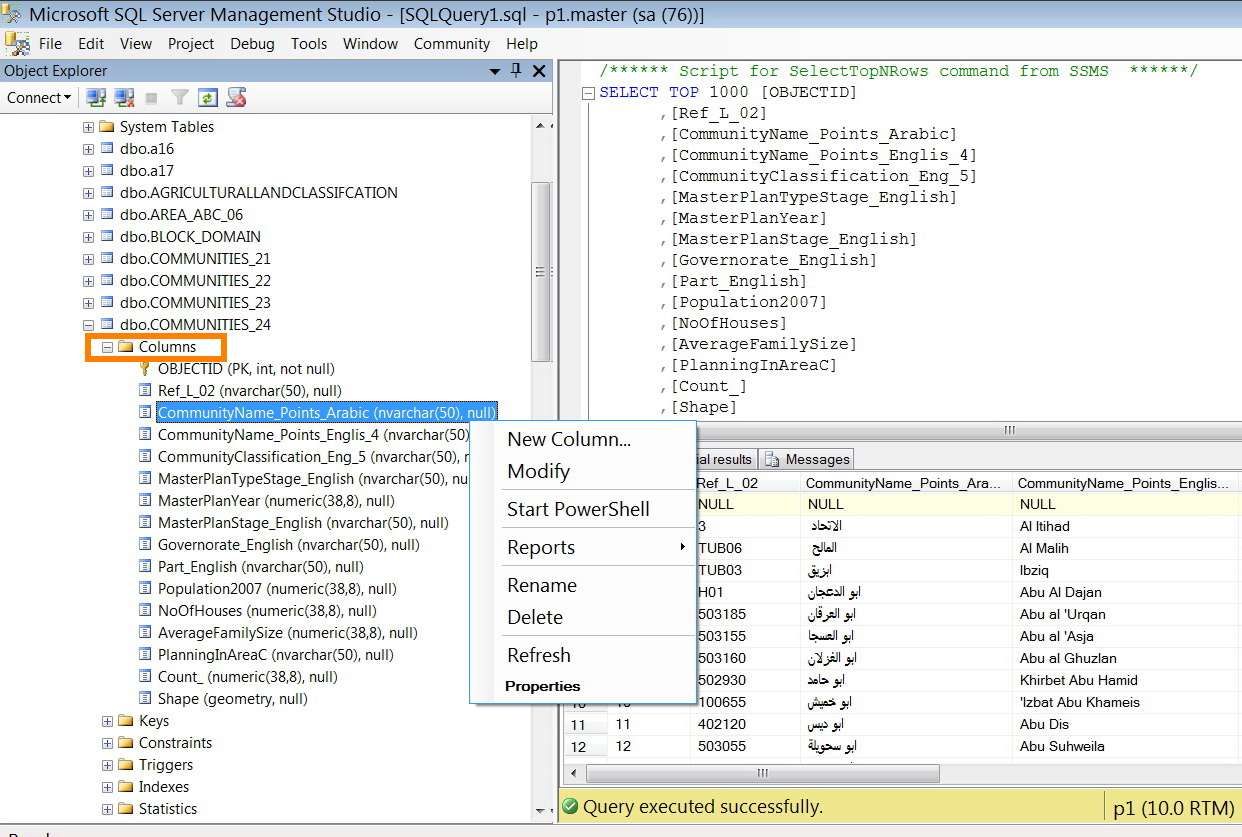
That�??s exactly what I did! You should be able to find this on my previous screenshot (enterprise geodatabase with that feature class)
1. I added the �??Arabic�?� as Collation designator (adding feature to an existing instance)
[ATTACH=CONFIG]22075[/ATTACH], [ATTACH=CONFIG]22074[/ATTACH]
2. Then I created an enterprise geodatabase
3. I copied the feature class to it
4. I tried the sql search! But no luck! It didn�??t work without the �??N�?�
[ATTACH=CONFIG]22076[/ATTACH]
Best
Jamal
Jamal, I still think it would be worthwhile to set the collation to Arabic and try to re-load the data in your geodatabase (re-loading to force setting of Arabic collation on the Arabic unicode column). If I understand it well, your queries should than not need the "N" prefix, which is more consistent with the normal ArcGIS usage and less confusing to you or your geodatabase users.
As the ArcGIS troubleshooting page also states: "No results are returned by ArcMap unless the SQL Server instance being queried is using a (Thai) locale or collation."
Alternatively, you might still try to change the collation of specifically the Arabic character column in SQL Server Managent Studio by using the ALTER statement against the column, as explained on this page (scroll down to see it under "Column-level collations"):
Collation and International Terminology
Example from the page:
ALTER TABLE myTable ALTER COLUMN mycol NVARCHAR(10) COLLATE Greek_CS_AI
And as you also say, it should potentially give a more consistent behaviour with the sorting of the data in different applications and SQL Server.
There also seem to be some new things with SQL Server 2008 and collations and a recommendation and push by Microsoft to use "BIN2" binary collations by checking the "Binary-code point" checkbox in the dialog you made a screenshot of. See this Microsoft MSDN page under "Binary collations":
Windows Collation Sorting Styles
But anyway, as I wrote before this is all a bit outside my knowledge base. I think Vince or Shannon might be able to give better informed answers on this specific subject.
Thank you Marco for the input.
That�??s exactly what I did! You should be able to find this on my previous screenshot (enterprise geodatabase with that feature class)
1. I added the �??Arabic�?� as Collation designator (adding feature to an existing instance)
[ATTACH=CONFIG]22075[/ATTACH], [ATTACH=CONFIG]22074[/ATTACH]
2. Then I created an enterprise geodatabase
3. I copied the feature class to it
4. I tried the sql search! But no luck! It didn�??t work without the �??N�?�
[ATTACH=CONFIG]22076[/ATTACH]
Best
Jamal
{kind=link}
{kind=link}
{kind=link}
02-22-2013
04:21 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you Marco for the input.
That�??s exactly what I did! You should be able to find this on my previous screenshot (enterprise geodatabase with that feature class)
1. I added the �??Arabic�?� as Collation designator (adding feature to an existing instance)
2. Then I created an enterprise geodatabase
3. I copied the feature class to it
4. I tried the sql search! But no luck! It didn�??t work without the �??N�?�
Best
Jamal
Jamal, did you also try to set a "Binary-code point" collation? This should force Unicode comparison in SQL Server. See this text from the MSDN page:
"Binary-code point (_BIN2)
Sorts and compares data in SQL Server tables based on Unicode code points for Unicode data. For non-Unicode data, Binary-code point will use comparisons identical to binary sorts.
The advantage of using a Binary-code point sort order is that no data resorting is required in applications that compare sorted SQL Server data. As a result, a Binary-code point sort order provides simpler application development and possible performance increases. For more information, see Guidelines for Using BIN and BIN2 Collations."
by
Anonymous User
Not applicable
02-23-2013
11:20 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Original User: [email protected]
Thank you for the contribution Marco.
I couldn�??t do this check on the sql server database.
Please, have a look on the screenshot below, am I in the right place to stick (as an example)
�??ALTER TABLE myTable ALTER COLUMN mycol NVARCHAR(10) COLLATE Greek_CS_AI�?�
[ATTACH=CONFIG]22117[/ATTACH]
Best
Jamal
Jamal, did you also try to set a "Binary-code point" collation? This should force Unicode comparison in SQL Server. See this text from the MSDN page:
"Binary-code point (_BIN2)
Sorts and compares data in SQL Server tables based on Unicode code points for Unicode data. For non-Unicode data, Binary-code point will use comparisons identical to binary sorts.
The advantage of using a Binary-code point sort order is that no data resorting is required in applications that compare sorted SQL Server data. As a result, a Binary-code point sort order provides simpler application development and possible performance increases. For more information, see Guidelines for Using BIN and BIN2 Collations."
Thank you for the contribution Marco.
I couldn�??t do this check on the sql server database.
Please, have a look on the screenshot below, am I in the right place to stick (as an example)
�??ALTER TABLE myTable ALTER COLUMN mycol NVARCHAR(10) COLLATE Greek_CS_AI�?�
[ATTACH=CONFIG]22117[/ATTACH]
Best
Jamal
{kind=link}
02-24-2013
12:08 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you for the contribution Marco.
I couldn�??t do this check on the sql server database.
Jamal,
Could you be a little bit more specific as to why you "... couldn't do this check ..."?? Were you unable to check the "Binary-code point" option in the dialog you made a screenshot of and that I attached below again? If so, this might be due to the fact that you also checked/selected "Case insensitive" and "Accent insensitive" or any of the other available options. If I understand it well, "Binary-code point" collations more or less use a predefined table with the sorting order fully determined (this is the code point/page, see this page and this page about character encoding and code pages on Wikipedia). This means you can't add options like "Case insensitive". Also see the following small remark below from this MSDN page, which confirms this incompatibility. So you will probably need to uncheck all other collation options before checking the "Binary-code point" collation option:
"If BIN or Binary-code point is selected, the Case-sensitive, Accent-sensitive, Kana-sensitive, and Width-sensitive options are not available."
Please, have a look on the screenshot below, am I in the right place to stick (as an example)
�??ALTER TABLE myTable ALTER COLUMN mycol NVARCHAR(10) COLLATE Greek_CS_AI�?�
[ATTACH=CONFIG]22117[/ATTACH]
I guess you are in the right place, but in your case the statement is probably going to look a bit more like:
"ALTER TABLE dbo.Communities_24 ALTER COLUMN CommunityName_Points_Arabic COLLATE Arabic_BIN2"
In case you wish to try to set a "Binary-code point" (BIN2) collation on this specific column.