- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Survey123
- :
- ArcGIS Survey123 Questions
- :
- Re: Using 'LEFT' function (or similar) to lookup c...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Using 'LEFT' function (or similar) to lookup corresponding choice list
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
I would like to use something similar to Excel expression, "LEFT" function, to refer to part of the Asset ID which will then automatically populate subsequent fields.
For example, as shown in the diagram below for Asset ID OBN51581A
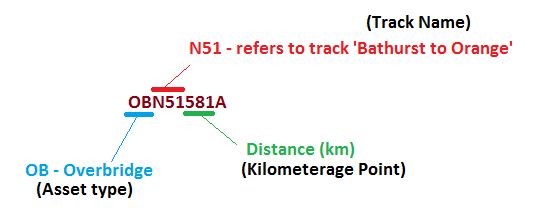
How can I structure the XLS form to get it to calculate or lookup the specific string from an Asset ID so that I can
and bring up the corresponding 'name' field listed in the choices tab?

So, my questions are:
- How do I write the query to look up parts of a string - the command line to extract/look up part of Asset ID
- And then get it to work with choice list and/or using choice_filter given it will be a one-to-one relationship?
An example of my choices sheet will be something like:
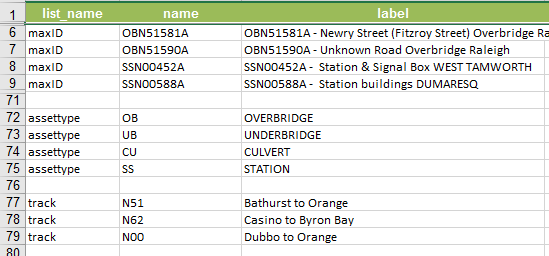
I know I can use pulldata to grab the same information, however, using the external CSV dataset is somewhat rigid and required the every asset information to be correctly entered in the CSV file.
Any suggestions will be greatly appreciated.
Thank you
SW
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Siew, I think what you need is the substr() function.
The substr operator will return only part of a string, defined by the numbers after it. The first character determines the starting point of the selection, while the second value determines the length (if no second value is present, it will continue until the end of the string).
In your case, you can use something like this in the calculation column:
substr(${AssetId}, 0, 2)
substr(${AssetId}, 2, 5)
substr(${AssetId}, 5, 😎
Bear in mind that the format must be consistent xxyyyzzz. I don't think passing this into a cascading select as a default answer is supported.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Siew, I think what you need is the substr() function.
The substr operator will return only part of a string, defined by the numbers after it. The first character determines the starting point of the selection, while the second value determines the length (if no second value is present, it will continue until the end of the string).
In your case, you can use something like this in the calculation column:
substr(${AssetId}, 0, 2)
substr(${AssetId}, 2, 5)
substr(${AssetId}, 5, 😎
Bear in mind that the format must be consistent xxyyyzzz. I don't think passing this into a cascading select as a default answer is supported.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Michael,
The substr() function works perfectly!
I have managed a work-around by combining the calculate on the substr() function followed by pulldata:
Even though the calculate rows do not return physical results on the form (ie row 8 & 9), field attributes are still created in the feature dataset layer. Which means, I would essentially have three attribute fields returning same/similar results and are therefore redundant. Is there a way to prevent field attributes to be created for row 8 and 9 above?
Thanks again.
SW
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Siew,
That's great to hear. There is indeed a way to prevent field attributes being created - see https://community.esri.com/groups/survey123/blog/2017/10/26/the-power-of-nothing?sr=search&searchId=... blog post for further details. All you have to do is specify the value of the bind::esri:fieldType column as null for the fields in question.
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Michael! It works! Cheers SW