- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Pro
- :
- ArcGIS Pro Questions
- :
- Re: Python routine to calculate MODIS NDVI anomaly
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Python routine to calculate MODIS NDVI anomaly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Python script to calculate NDVI anomalies
https://geonet.esri.com/people/xander_bakker
I´d like to automate all my workflow, from downloaded original raster datasets to anomaly calculator:
3 years data and folder structure can be downloaded here.
Question 1: What is the best option: to run separated scripts or create a unique code?
Question 2: How to translate the model builder to python script (Python script 2)?
Question 3: If the best option is to run separated, how to make it in a logical sequence (script 1 -> script 2 -> script 3)
Summary workflow:
- Select and download NDVI filtered raster datasets;
- Store downloaded original raster datasets at X:\Modis250\Originais\
- Organizing files and folders: (Python script 1)
- Rename original raster datasets (MODIS.ndvi.YYYYjjj.yL6000.BOKU.tif) to filename standard “ndvi_YYYY_dec_dd.tif”, where “YYYY” is the year, “jjj” is the Julian day and “dd” is the decade (ten days period).
- Transfer renamed files from X:\Modis250\Originais to X:\Modis250\NDVI10dias
- Pre-processing raster datasets: (Python script 2)
- Project renamed raster datasets ("ndvi_YYYY_dec_dd.tif") from Lat/Lon WGS 1984 to Lat/Lon SIRGAS2000 using "SAD_1969_To_WGS_1984_14 + SAD_1969_To_SIRGAS_2000_1" geographic transformation.
- Overwrite spurious data values: NDVI = Con("%NDVI%"<1,0,Con("%NDVI%">9998,9999,"%NDVI%"))
- Standardize raster datasets: NDVI = (NDVI – Mean(NDVI))/Std(NDVI)
- Scale raster datasets to 0 – 100: NDVI = ((NDVI-Min(NDVI))/(Max(NDVI)-Min(NDVI)) * 100
- Mask standardized raster datasets by the area of interest (X:\Modis250\SRTM\mde_sc_90.tif) and output to X:\Modis250\NDVI_10dias_norm
- Processing data (Python script 3)
- Calculate NDVI mean for each decadal: mean_dec_dd.tif = MEAN (ndvi_YYY1_dec_dd.tif, ndvi_YYY2_dec_dd.tif, ndvi_YYY3_dec_dd.tif,…)
- Calculate NDVI anomaly for each year by decade: anom_yyyy_dec_dd.tif = ndvi_YYYY_dec_dd.tif - mean_dec_dd.tif
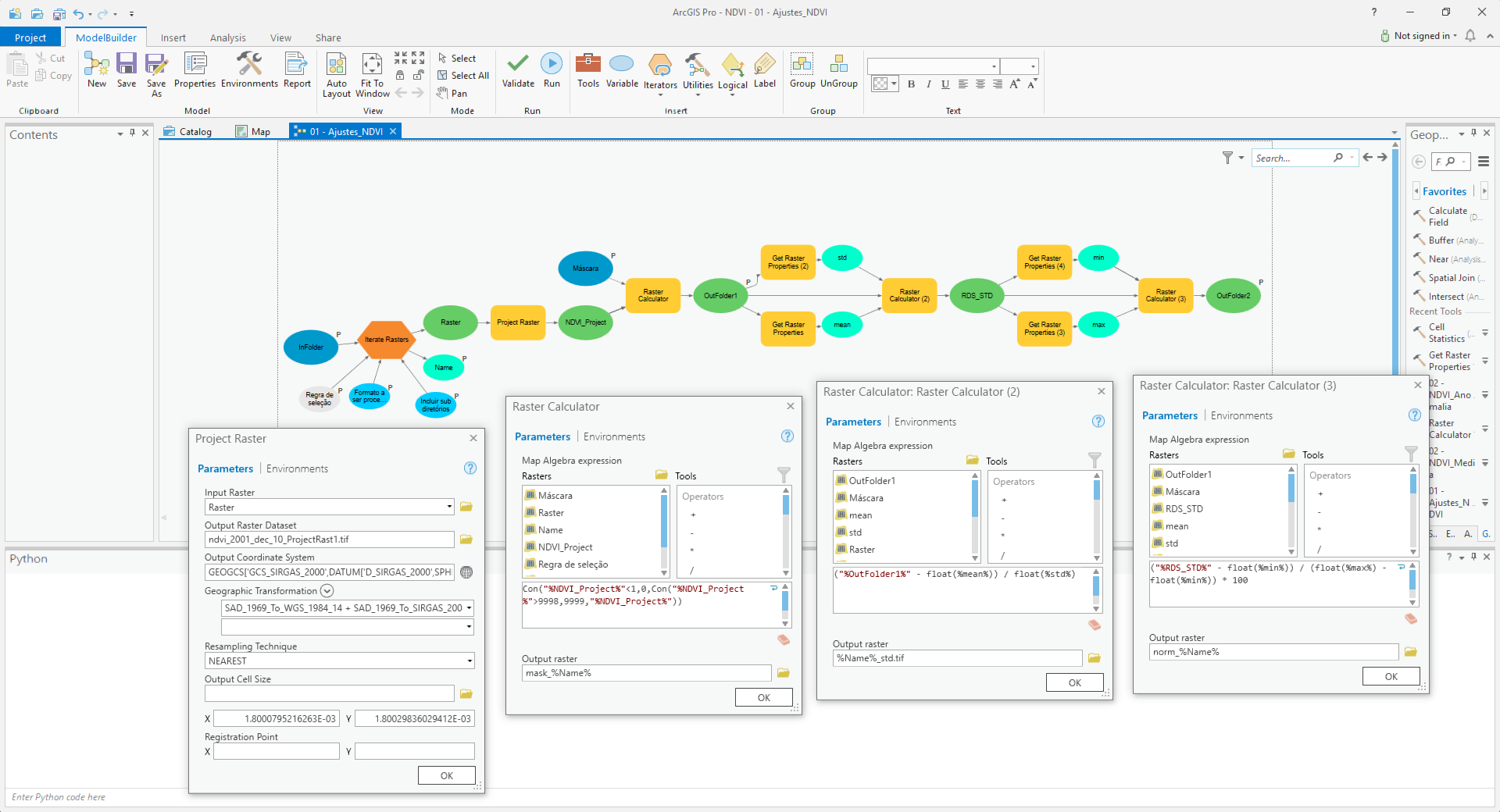
Python scripts 1 and 3 are working. The scrip 2 (Pre-processing) is a model in a toolbox.
Python script 1: written by myself, maybe need to be improved!
#Rename original files
import arcpy, datetime, glob, os
arcpy.env.overwriteOutput = True
arcpy.env.workspace=r'O:\Modis250\Originais'
infolder='O:\Modis250\Originals'
outfolder='O:\Modis250\NDVI_10dias'
list1=arcpy.ListRasters("*.tif")
list1.sort()
for raster in list1:
source_path = os.path.join(infolder, raster)
oldFilename=raster
dd = int(oldFilename[15:18])
if dd < 11: dd = 1
elif dd < 21: dd = 2
elif dd < 31: dd = 3
elif dd < 41: dd = 4
elif dd < 51: dd = 5
elif dd < 61: dd = 6
elif dd < 71: dd = 7
elif dd < 81: dd = 8
elif dd < 91: dd = 9
elif dd < 101: dd = 10
elif dd < 111: dd = 11
elif dd < 121: dd = 12
elif dd < 131: dd = 13
elif dd < 141: dd = 14
elif dd < 151: dd = 15
elif dd < 161: dd = 16
elif dd < 171: dd = 17
elif dd < 181: dd = 18
elif dd < 191: dd = 19
elif dd < 201: dd = 20
elif dd < 211: dd = 21
elif dd < 221: dd = 22
elif dd < 231: dd = 23
elif dd < 241: dd = 24
elif dd < 251: dd = 25
elif dd < 261: dd = 26
elif dd < 271: dd = 27
elif dd < 281: dd = 28
elif dd < 291: dd = 29
elif dd < 301: dd = 30
elif dd < 311: dd = 31
elif dd < 321: dd = 32
elif dd < 331: dd = 33
elif dd < 341: dd = 34
elif dd < 351: dd = 35
else: dd = 36
dd = str(dd)
newFilename="ndvi_" + oldFilename[11:15] + "_dec_" + dd + ".tif"
destination_path=os.path.join(outfolder, newFilename)
os.rename(source_path, destination_path)Model Builder -> Python script 2
Python script 3: Python script to calculate NDVI anomalies
def main():
import arcpy
import os
arcpy.env.overwriteOutput = True
# Check out SA license
arcpy.CheckOutExtension("spatial")
# settings
ws_norm = r'D:\Modis250\NDVI_10dias_norm'
ws_mean = r'D:\Modis250\NDVI_10dias_mean'
ws_anom = r'D:\Modis250\NDVI_10dias_anom'
# create a list of all raster in norm folder
arcpy.env.workspace = ws_norm
lst_ndvi_ras = arcpy.ListRasters()
lst_ndvi_ras.sort()
print ("lst_ndvi_ras: {}".format(lst_ndvi_ras))
# get list of years
decades = GetListOfDecades(lst_ndvi_ras)
decades.sort()
print ("decades: {}".format(decades))
# loop through each year
for decade in decades:
# Get rasters for given year
lst_ndvi_decade = GetListOfRasterForGivenDecade(lst_ndvi_ras, decade)
print("lst_ndvi_decade: {}".format(lst_ndvi_decade))
# calculate mean raster for decade
lst_ndvi_decade_paths = [os.path.join(ws_norm, r) for r in lst_ndvi_decade]
print("lst_ndvi_decade_paths: {}".format(lst_ndvi_decade_paths))
mean_ras = arcpy.sa.CellStatistics(lst_ndvi_decade_paths, "MEAN", "DATA")
# store mean ras for decade
# mean_dec_d_.tif
out_name_mean = "mean_dec_{}.tif".format(decade) ###
out_name_path_mean = os.path.join(ws_mean, out_name_mean)
print ("out_name_path_mean: {}".format(out_name_path_mean))
mean_ras.save(out_name_path_mean)
# loop through each raster in decade
for ndvi_ras in lst_ndvi_decade:
# calculate anom for each raster in decade
# anom_2002_dec_1.tif = norm_ndvi_2002_dec_1.tif - mean_dec_1_.tif;
print ("ndvi_ras: {}".format(ndvi_ras))
# minus_ras = arcpy.sa.Minus(ndvi_ras, out_name_path_mean)
out_name_path_norm = os.path.join(ws_norm, ndvi_ras)
minus_ras = arcpy.Raster(out_name_path_mean) - arcpy.Raster(out_name_path_norm)
# store anom raster
out_name_anom = ndvi_ras.replace("norm_ndvi", "anom")
out_name_path_anom = os.path.join(ws_anom, out_name_anom)
minus_ras.save(out_name_path_anom)
print ("out_name_path_anom: {}".format(out_name_path_anom))
# return SA license
arcpy.CheckInExtension("spatial")
def GetListOfDecades(lst):
# norm_ndvi_yyyy_dec_d.tif
lst1 = list(set([r.split("_")[4] for r in lst]))
return [r.split('.')[0] for r in lst1]
def GetListOfRasterForGivenDecade(lst, decade):
lst1 = []
search = "_{}.tif".format(decade)
for r in lst:
if search in r.lower():
lst1.append(r)
return lst1
if __name__ == '__main__':
main()Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
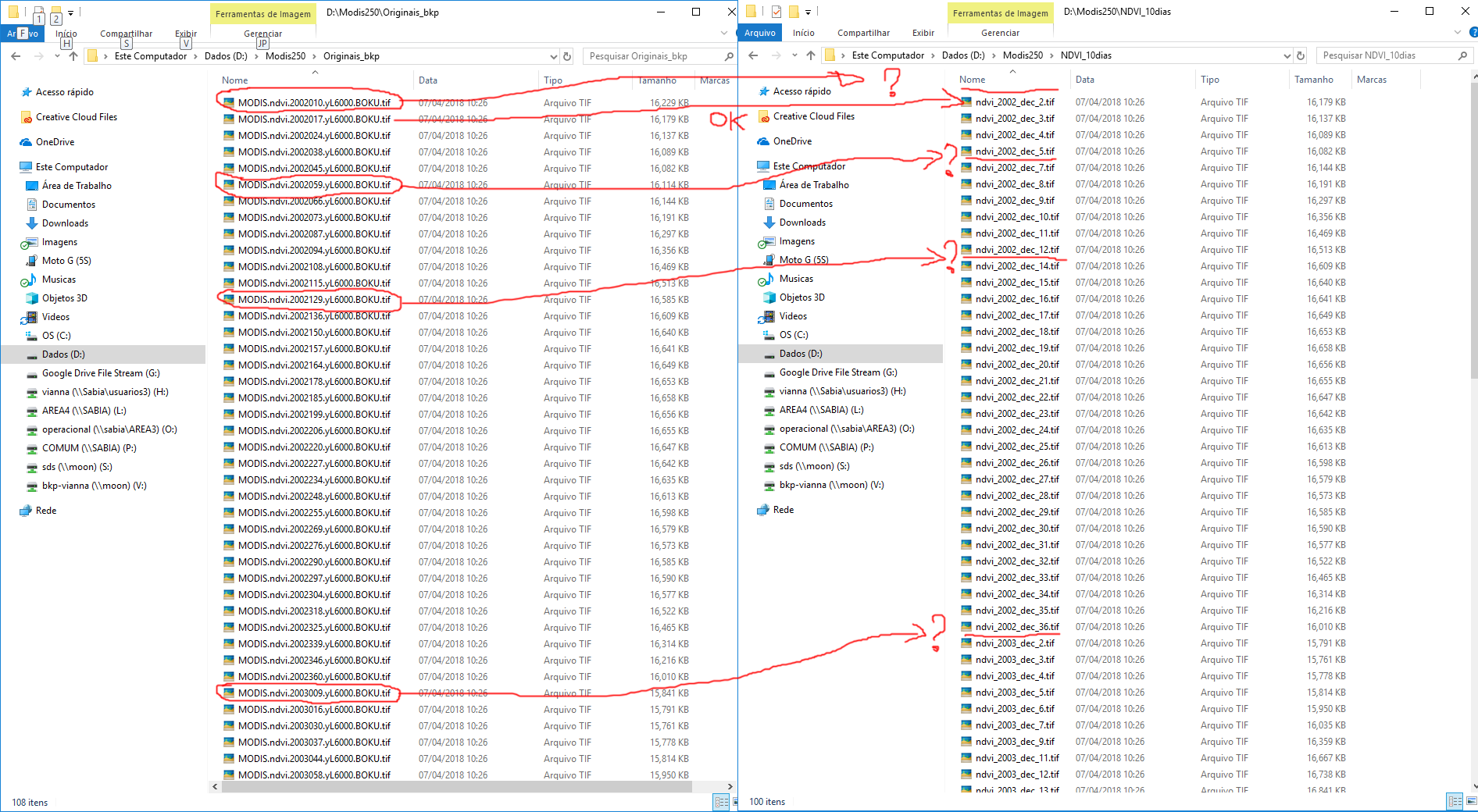
So why are some files missing? Are the julian days from files before and after the missing files influencing it?
If two or more files are inside the same decade, the higuer julian day would prevalece.
Missing files are those from:
MODIS.ndvi.2002010.yL6000.BOKU.tif to ndvi_2002_dec_1.tif
MODIS.ndvi.2002059.yL6000.BOKU.tif to ndvi_2002_dec_6.tif
MODIS.ndvi.2002129.yL6000.BOKU.tif to ndvi_2002_dec_13.tif
MODIS.ndvi.2003009.yL6000.BOKU.tif to ndvi_2003_dec_1.tif
MODIS.ndvi.2003079.yL6000.BOKU.tif to ndvi_2003_dec_8.tif
MODIS.ndvi.2003100.yL6000.BOKU.tif to ndvi_2003_dec_10.tif
MODIS.ndvi.2003170.yL6000.BOKU.tif to ndvi_2003_dec_17.tif
MODIS.ndvi.2004050.yL6000.BOKU.tif to ndvi_2004_dec_5.tif
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
MODIS.ndvi.2017090.yL6000.BOKU.tif
- y: 2017
- j: 90
- d: 10 - This should be decade 9
- out_named: ndvi_2017_dec_10.tif
MODIS.ndvi.2016090.yL6000.BOKU.tif
- y: 2016
- j: 90
- d: 9 - This is ok
- out_named: ndvi_2016_dec_9.tif
MODIS.ndvi.2002010.yL6000.BOKU.tif
- y: 2002
- j: 10
- d: 2 - This should be decade 1
- out_named: ndvi_2002_dec_2.tif
MODIS.ndvi.2002059.yL6000.BOKU.tif
- y: 2002
- j: 59
- d: 7 - This should be decade 6
- out_named: ndvi_2002_dec_7.tif
MODIS.ndvi.2003079.yL6000.BOKU.tif
- y: 2003
- j: 79
- d: 9 - This should be decade 8
- out_named: ndvi_2003_dec_9.tif
MODIS.ndvi.2003100.yL6000.BOKU.tif
- y: 2003
- j: 100
- d: 11 - This should be decade 10
- out_named: ndvi_2003_dec_11.tif- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
At least 1 was OK... 
I will look into the formula. Most likely this is causing the wrong result and missing decades.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
yep, I made a small change in the function. Just to be sure the Julian date is not zero based right?
In that case it should be like this:
def GetDecadeFromJulian(year, j):
import datetime
date = datetime.datetime(year-1, 12, 31) + datetime.timedelta(j)
m = (date.month - 1) * 3
if date.day <= 10:
d = 1
elif date.day <= 20:
d = 2
else:
d = 3
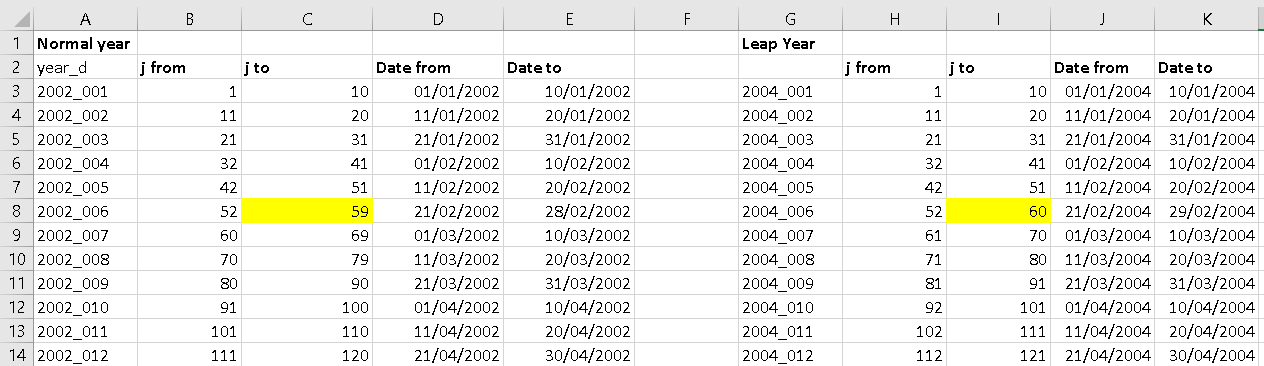
return m + dI tested it with this code using year 2002 (normal) and 2004 (leap):
def main():
dct = {}
y = 2004
for j in range(1, 367):
d, date = GetDecadeFromJulian(int(y), j)
yd = "{}_{}".format(date.year, "%03d" % (d, ))
if yd in dct:
# j min, j max, date min, date max
data = dct[yd]
if j < data[0]:
data[0] = j
data[2] = date
if j > data[1]:
data[1] = j
data[3] = date
else:
data = [j, j, date, date]
dct[yd] = data
for yd, data in sorted(dct.items()):
print "{}\t".format(yd) + "\t".join([str(d) for d in data])
def GetDecadeFromJulian(year, j):
import datetime
date = datetime.datetime(year-1, 12, 31) + datetime.timedelta(j)
m = (date.month - 1) * 3
if date.day <= 10:
d = 1
elif date.day <= 20:
d = 2
else:
d = 3
return m + d, date
if __name__ == '__main__':
main()
Resulting in:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I overwrited the "GetDecadeFromJulian" and tested the new code:
def main():
import arcpy
import os
import shutil
arcpy.env.overwriteOutput = True
ws_in = r'D:\Modis250\Originais'
ws_out = r'D:\Modis250\NDVI_10dias'
arcpy.env.workspace = ws_in
lst_ras = arcpy.ListRasters("*.tif")
for ras_name in sorted(lst_ras):
# MODIS.ndvi.YYYYjjj.yL6000.BOKU.tif
in_name_path = os.path.join(ws_in, ras_name)
y = ras_name[11:15]
j = int(ras_name[15:18])
d = GetDecadeFromJulian(int(y), j)
out_name = "ndvi_{}_dec_{}.tif".format(y, d)
out_name_path = os.path.join(ws_out, out_name)
#os.rename(in_name_path, out_name_path)
shutil.move(in_name_path, out_name_path)
print (out_name + " renamed")
def GetDecadeFromJulian(year, j):
import datetime
date = datetime.datetime(year-1, 12, 31) + datetime.timedelta(j)
m = (date.month - 1) * 3
if date.day <= 10:
d = 1
elif date.day <= 20:
d = 2
else:
d = 3
return m + d, date
if __name__ == '__main__':
main()Resulting in:

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So it is working now?
Make sure to remove the part ", date" from line 35. This was for testing only.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you, Xander! It is working now!
Now let´s finish the script 2: How can we delete the Temp files at scratchworkspace?
def main():
import arcpy
import os
arcpy.CheckOutExtension("spatial")
arcpy.env.overwriteOutput = True
# Set Geoprocessing environments
ws_scr = r'D:\Modis250\Temp' #Scratch workspace
ws_in = r'D:\Modis250\NDVI_10dias' #Input workspace
ws_out = r'D:\Modis250\NDVI_10dias_norm' #Output workspace
mask = r'D:\Modis250\SRTM\mde_sc_90.tif' #Raster used as mask
arcpy.env.scratchWorkspace = ws_scr
arcpy.env.workspace = ws_in
lst_ras = arcpy.ListRasters("*.tif")
lst_ras.sort()
# Pre-processing original rasters
for raster1 in lst_ras:
print ("Processing: " + raster1)
#outRaster1= Original raster projected from CGS-WGS1964 to CGS-SIRGAS-2000
outRaster1 = os.path.join(ws_scr, "rep_{}".format(raster1)) # Temporary file
arcpy.ProjectRaster_management(raster1, outRaster1,"GEOGCS['GCS_SIRGAS_2000',DATUM['D_SIRGAS_2000',SPHEROID['GRS_1980',6378137.0,298.257222101]],PRIMEM['Greenwich',0.0],UNIT['Degree',0.0174532925199433]]", "NEAREST", "1.8000795216263E-03 1.80029836029412E-03", "'SAD_1969_To_WGS_1984_14 + SAD_1969_To_SIRGAS_2000_1'", "", "GEOGCS['GCS_WGS_1984',DATUM['D_WGS_1984',SPHEROID['WGS_1984',6378137.0,298.257223563]],PRIMEM['Greenwich',0.0],UNIT['Degree',0.0174532925199433]]")
print ("rep_{}".format(raster1) + " projected")
#outRaster2 = outRaster1 masked by Area of Interest (AOI)
outRaster2 = arcpy.sa.ExtractByMask(outRaster1, mask) # Temporary file
outRaster2.save(os.path.join(ws_scr, "mask_{}".format(raster1)))
print ("mask_{}".format(raster1) + " masked")
#outRaster3 = Overwrited spurious data values from outRaster2
outRaster3 = arcpy.sa.Con(outRaster2 < 1, 0, arcpy.sa.Con(outRaster2 > 9998, 9999, outRaster2)) # Temporary file
outRaster3.save(os.path.join(ws_scr, "aju_{}".format(raster1)))
print ("aju_{}".format(raster1) + " ajusted")
#outRaster4 = Standardized outRaster3
#ras_mean = arcpy.GetRasterProperties_management(outRaster3, "MEAN")
#ras_std = arcpy.GetRasterProperties_management(outRaster3, "STD")
ras_mean = float(arcpy.GetRasterProperties_management(outRaster3, "MEAN").getOutput(0))
ras_std = float(arcpy.GetRasterProperties_management(outRaster3, "STD").getOutput(0))
outRaster4 = ((outRaster3-ras_mean)/ras_std) # Temporary file
outRaster4.save(os.path.join(ws_scr, "ras_std_{}".format(raster1)))
print ("ras_std_{}".format(raster1) + " standardized")
#outRaster = Final raster scaled to 0 -100
#ras_max = arcpy.GetRasterProperties_management(outRaster4, "MAXIMUM")
#ras_min = arcpy.GetRasterProperties_management(outRaster4, "MINIMUM")
ras_max = float(arcpy.GetRasterProperties_management(outRaster4, "MAXIMUM").getOutput(0))
ras_min = ras_min = float(arcpy.GetRasterProperties_management(outRaster4, "MINIMUM").getOutput(0))
outRaster = ((outRaster4-ras_min)/(ras_max-ras_min) * 100) # Final result
outRaster.save(os.path.join(ws_out, "norm_{}".format(raster1)))
print ("norm_{}".format(raster1) + " processed")
arcpy.CheckInExtension("spatial")
if __name__ == '__main__':
main()- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just to be sure, which of the rasters need to removed after the process?
- rep*
- mask*
- aju*
- ras*
- norm*
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
rep*
mask*
aju*
ras_std*
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
What you could do is manage a list of tmp rasters and delete each item at the end like this:
def main():
import arcpy
import os
arcpy.CheckOutExtension("spatial")
arcpy.env.overwriteOutput = True
# Set Geoprocessing environments
ws_scr = r'D:\Modis250\Temp' #Scratch workspace
ws_in = r'D:\Modis250\NDVI_10dias' #Input workspace
ws_out = r'D:\Modis250\NDVI_10dias_norm' #Output workspace
mask = r'D:\Modis250\SRTM\mde_sc_90.tif' #Raster used as mask
arcpy.env.scratchWorkspace = ws_scr
arcpy.env.workspace = ws_in
lst_ras = arcpy.ListRasters("*.tif")
lst_ras.sort()
# Pre-processing original rasters
lst_tmp = []
for raster1 in lst_ras:
print ("Processing: " + raster1)
#outRaster1= Original raster projected from CGS-WGS1964 to CGS-SIRGAS-2000
outRaster1 = os.path.join(ws_scr, "rep_{}".format(raster1)) # Temporary file
arcpy.ProjectRaster_management(raster1, outRaster1,"GEOGCS['GCS_SIRGAS_2000',DATUM['D_SIRGAS_2000',SPHEROID['GRS_1980',6378137.0,298.257222101]],PRIMEM['Greenwich',0.0],UNIT['Degree',0.0174532925199433]]", "NEAREST", "1.8000795216263E-03 1.80029836029412E-03", "'SAD_1969_To_WGS_1984_14 + SAD_1969_To_SIRGAS_2000_1'", "", "GEOGCS['GCS_WGS_1984',DATUM['D_WGS_1984',SPHEROID['WGS_1984',6378137.0,298.257223563]],PRIMEM['Greenwich',0.0],UNIT['Degree',0.0174532925199433]]")
print ("rep_{}".format(raster1) + " projected")
lst_tmp.append(outRaster1)
#outRaster2 = outRaster1 masked by Area of Interest (AOI)
outRaster2 = arcpy.sa.ExtractByMask(outRaster1, mask) # Temporary file
outRaster2.save(os.path.join(ws_scr, "mask_{}".format(raster1)))
print ("mask_{}".format(raster1) + " masked")
lst_tmp.append(os.path.join(ws_scr, "mask_{}".format(raster1)))
#outRaster3 = Overwrited spurious data values from outRaster2
outRaster3 = arcpy.sa.Con(outRaster2 < 1, 0, arcpy.sa.Con(outRaster2 > 9998, 9999, outRaster2)) # Temporary file
outRaster3.save(os.path.join(ws_scr, "aju_{}".format(raster1)))
print ("aju_{}".format(raster1) + " ajusted")
lst_tmp.append(os.path.join(ws_scr, "aju_{}".format(raster1)))
#outRaster4 = Standardized outRaster3
#ras_mean = arcpy.GetRasterProperties_management(outRaster3, "MEAN")
#ras_std = arcpy.GetRasterProperties_management(outRaster3, "STD")
ras_mean = float(arcpy.GetRasterProperties_management(outRaster3, "MEAN").getOutput(0))
ras_std = float(arcpy.GetRasterProperties_management(outRaster3, "STD").getOutput(0))
outRaster4 = ((outRaster3-ras_mean)/ras_std) # Temporary file
outRaster4.save(os.path.join(ws_scr, "ras_std_{}".format(raster1)))
print ("ras_std_{}".format(raster1) + " standardized")
lst_tmp.append(os.path.join(ws_scr, "ras_std_{}".format(raster1)))
#outRaster = Final raster scaled to 0 -100
#ras_max = arcpy.GetRasterProperties_management(outRaster4, "MAXIMUM")
#ras_min = arcpy.GetRasterProperties_management(outRaster4, "MINIMUM")
ras_max = float(arcpy.GetRasterProperties_management(outRaster4, "MAXIMUM").getOutput(0))
ras_min = ras_min = float(arcpy.GetRasterProperties_management(outRaster4, "MINIMUM").getOutput(0))
outRaster = ((outRaster4-ras_min)/(ras_max-ras_min) * 100) # Final result
outRaster.save(os.path.join(ws_out, "norm_{}".format(raster1)))
print ("norm_{}".format(raster1) + " processed")
arcpy.CheckInExtension("spatial")
# delete tmp rasters
lst_err = []
for tmp_ras in lst_tmp:
try:
arcpy.Delete_management(tmp_ras)
except:
lst_err.append(tmp_ras)
# report rasters that could not be deleted
if len(lst_err) > 0:
print("\nThe following tmp rasters could not be deleted:")
for tmp_ras in lst_err:
print (" - {}".format(tmp_ras))
if __name__ == '__main__':
main()Have a look at the list called "lst_tmp". At lines 26, 32, 38 and 48 the raster name - path is added to a list. Each item is deleted in the block between line 61 and 67. If any item could not be deleted, this is reported in lines 69 to 73.
Beware, code is not tested and if any of the products is now configured for deletion when it should not be, comment that line out, so it does not get added to the list of items to be deleted.