- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Pro
- :
- ArcGIS Pro Ideas
- :
- Human/GIT Readable APRX & STYLX formats
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Follow this Idea
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Although not necessarily the most human readable, the MAPX (exported map) and LYRX (layer file) are all human readable, essentially being JSON by nature. Although not its main purpose, editing these files is nice, but what's even nicer, is the fact that versioning systems such as GIT (such as in use in our company in the form of Azure DevOps) really really play well with these files: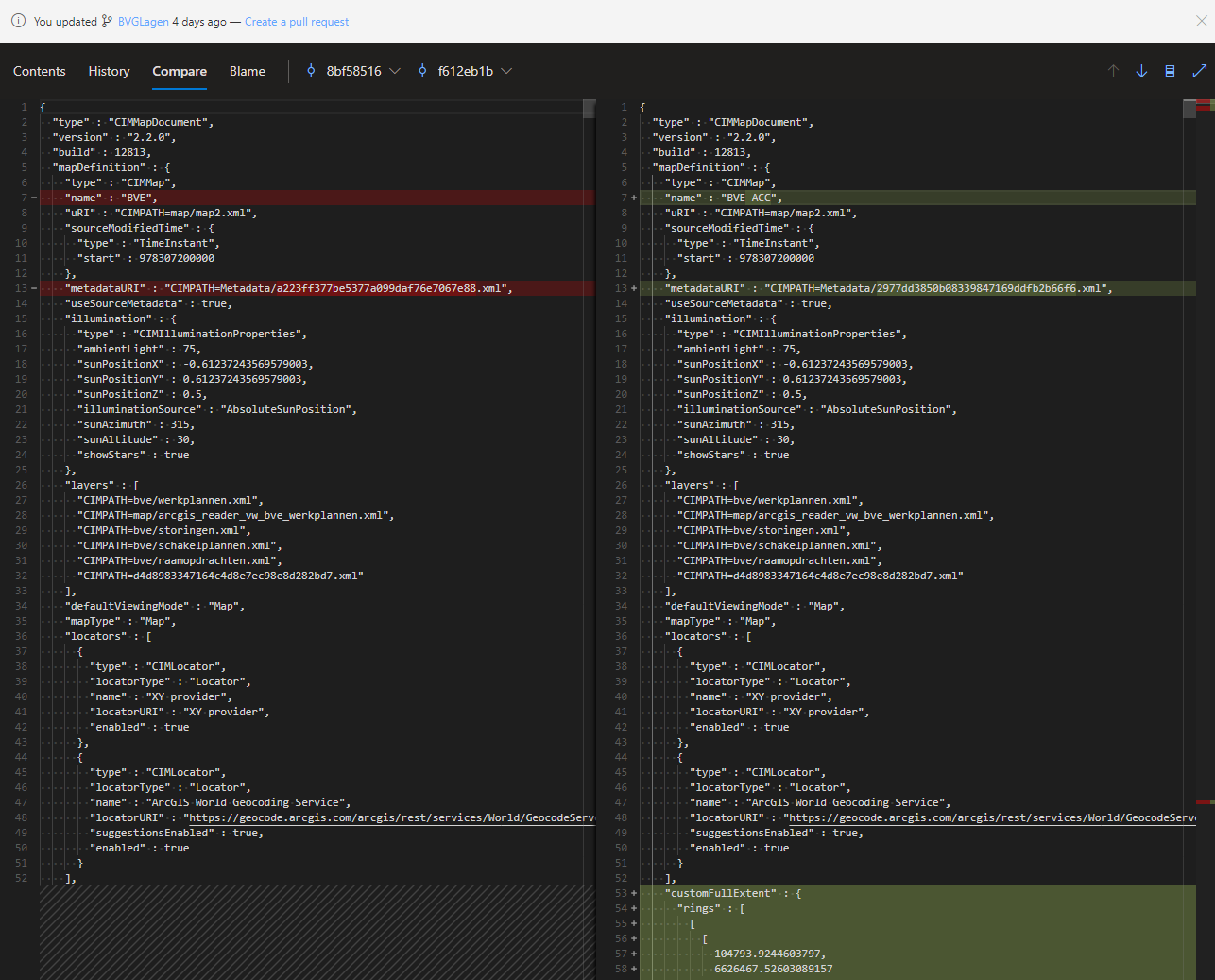
For some inexplicable reason, however, the APRX (project) and STYLX (style... especially styles...) are very much still:

Binary.
This is troublesome, especially for a system such as a style, where many people could be working on one style... a GIT Merge would be awesome for this potentially... but also for APRX this would be nice.
I would love to just... commit, push, merge to my hearts' desire... at the moment the workflow's slowly turning into "export mapfiles, export layers, make own copy of style, commit, push"
Make ArcGIT real! Make our files version-tracked 
APRX files are zip archives. STYLX are SQLite databases. At this point there are no plans to change this.
That actually helped me to at least build a model to change-track APRX files. SQLite Stylx is another issue though... i'd be great for them to have some history/tracking/multi-user/centered-ness in them. We hook a lot of them up in portal, so our users can re-use them as well, but the act of actually changing them involves a re-upload, and that's frankly a hassle. Not to mention the awkward merges if they change up in GIT...
Hey Craig,
It would be REALLY sweet if you released the xsd document for the various xml files found in the unzipped APRX. Any chance of that?
Nathan Warmerdam
We've been focusing on documenting the JSON variation of this spec (see https://github.com/Esri/cim-spec). We've had requests to have a JSON schema version of this which we're considering, but no plans to do an XML schema at this point.
mapx, lyrx, pagx, and items in styles all use the JSON spec.
Hey Craig,
Thanks for getting back to me. I'd actually be happy with either the JSON or XML schemas for the CIM. There are tools that can get you a long way from sample xml/json files but I know that I'll never be able to provide a fully complete sample to these tools and thus never have full confidence in what comes out the other side.
Nathan
Projects (aprx files) will be stored as JSON starting in ArcGIS Pro 3.0 expected to be available in June 2022. See https://www.esri.com/arcgis-blog/products/arcgis-pro/announcements/get-ready-for-arcgis-pro-3-0/
Hey have there been any updates on this? I would like to know if anyone have been able to open the aprx as a JSON file yet, and how did you manage to do it,
Thanks,
Certainly as of ArcGIS Pro 3.4, files within the .aprx file are JSON, though, somewhat annoyingly, the .aprx and .atbx files are compressed archives (.zip). If you have 7-Zip (or another archiving tool) installed, you're able to open a .aprx file to see (and extract) its contents.
Because .aprx and .atbx files are still compressed archives it's still a bit more difficult and annoying to version control them, whilst still being able to compare diffs on the internal JSON objects, etc. Of course it's easy to version control the binary .aprx and .atbx files directly, though you lose the diff/merge capabilities of git.
That said, thinking-outside-the-box, git has the concept of hooks which allows git to run scripts before git actions (commit, push, archive, etc.) so it's possible to unpack the .aprx and .atbx files before committing them to a git repo. Indeed there's an entire (Python-based) framework for managing this functionality, which can be found here: https://pre-commit.com/
I haven't experimented with this yet, though it's possible. I just have to work out how to re-create the .aprx and .atbx files transparently, or detecting changes when the project is saved in ArcGIS Pro but before the atomic JSON files within are extracted.
Doing a little more digging, it's possible to just generate a diff (or log) between two .aprx or .atbx files without having to extract them, by telling git that certain file types need to be extracted on-the-fly first, returning the result to stdout (in effect, printing to the command line):
(relevant git documentation: https://git-scm.com/docs/gitattributes#_performing_text_diffs_of_binary_files)
- Open (or create) a .gitconfig (note the . before gitconfig) in the following directory. This file is your git configuration file:
C:\Users\<username>\ - Add the following lines to your git configuration file (.gitconfig), then save and close it:
[diff "zip"]
textconv = unzip -c -a[log "zip"]
textconv = unzip -c -a - Create a .gitattributes file in the git version controlled directory the .aprx file is in (denoted by a .git folder):
- Add the following lines to the new .gitattributes file. Save and close it:
*.aprx diff=zip
*.aprx log=zip
*.atbx diff=zip
*.atbx log=zip - Using the the git client (other software that utilises git may also be able to do this, if they don't use their in-built git client), you can now view text representations of .aprx and .atbx files:




You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.