- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Pro
- :
- ArcGIS Pro Ideas
- :
- Add Find Input fields to Primary Locator Role Find...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Follow this Idea
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
For the new primary locator roles it would be really helpful to get the input search field values in the response. This way it can be checked to matched candidate.
We are trying to use the new PointAddress and Streets Roles but getting invalid matches which did not occur in the SubAddress locator in 10.x. Due to these mismatches it would helpful to see what the input search address was so it can be compared to the result.
In this example below, we are entering and a single line input: 4791 PELL DR STE 1, SACRAMENTO, 95837
However the match comes back without the STE which is not correct and should not have the 100% match score.
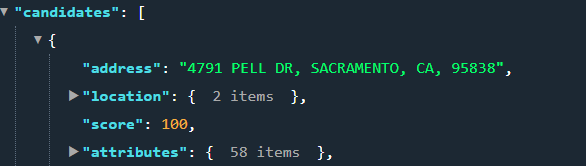
The 10.x SubAddress locator returned no matches which is a better result but realistically there should be a candidate match with a lower score than 100.
If the search input was in the result we would easily be able to compare the search string with the match string to weed thru these mismatches.
I think you need to put a hash tag in front of your STE 1 for it to work:
4791 PELL DR #STE 1
Of course provided your address points have that data.
See :
https://community.esri.com/thread/237690-address-point-role-with-units &
Thanks for the reference links and suggestion. This candidate does not exist yet so in this situation introducing the #STE did not work. We are expecting a no match like the SubAddress 10.x locator or the match without the unit with a score less than 100. This is one way we detect if an address exists or not. If addresses coming back with 100% score but do not match the input address this is a concern and should show up in the component scores but those don't appear to be available yet in the new locator roles.
For us to inject # before the unit type into the single line input string will be challenging from our enterprise system if not nearly impossible. That does not seem like a reasonable solution.
@RonnieRichards Is this still a problem with input addresses that contain subunits if you have recreated the locator in a newer release of ArcGIS Pro and publish the service? Does the data to create the locator include 'STE' as a unit type or as part of the value in the unit field that was mapped when building the locator? If the value in the unit field that was mapped when the locator was built is "STE 1", then you will need to include '#STE 1' as part of the input address. If the value in the unit field mapped when the locator was built was '1', then to get the best results you should include a unit indicator like # or STE, but you do not have to include one with locators created in Pro 2.7 or later.
Hello @ShanaBritt ,
Sorry for the delay, this has been on our list to test and staff have just completed a big round of testing. We have created locators using 2.9.3 and still seeing the same results where the INPUT ADDRESS is not returned in the response and getting unit returns when they really dont exist. But when the units do exist in source data, the hit rate has increased significantly from our previous locators.
For this idea the original concept has not been applied yet:
This input candidate still gets the same match and response as reported in 10.6.1. Ideally we want to see the input address line back in the response so we can compare it to the match, especially for purposes such as this when the input DOES NOT MATCH the match, especially with a 100% match score.
This is important if the new locators are going to return erroneous results with 100% match score for an address which does not exist in the source.
It would be much easier to report on these if the component scores were included but those still do not seem available yet.
@RonnieRichards Looking back at your original post, I would say that you should include at least 'addr_type' to be returned from the request so that you can understand the match level of the returned candidate. What is returned in the example is a PointAddress candidate and not a Subaddress candidate. If a feature that represents this subaddress does not exist in the reference data, then locator is going to return a match at the next precise match level, which is PointAddress in this case, which is less precise than Subaddress. If you are just searching for subaddress addresses, then I would suggest adjusting the Categories setting in the locator to only search for/return Subaddress by just checking Subaddress. Do you get the same result for search when testing the same locator in Pro Locate pane? Do you see any suggestions for the subaddress as you type the address that includes the subaddress element?
@ShanaBritt thank you for alerting me to the differences between the Subaddress and PointAddress results. The way this is topic is heading is much different than the original submitted idea so if there is a better location to explain this please let me know.
However I am still seeing the same match score results which is confusing. To be specific when using the PointAddress type we do get a hit on the address string: 4791 PELL DR STE 1, SACRAMENTO, CA 95838 but with a 100% score. Shouldn't the extra string elements detected as a unit type and unit number reduce scoring? Are the locator output fields documented anywhere?
It seemed to do so in the legacy locators with a match of 96.2 and a it shows in the scoring component return but using the "Locality" attribute:
Comp_score: ;House=100; prefix=100; pretype=100; StName=100; suftype=100; suffix=100; LocalityPreDir=100; LocalityPreType=100; Locality=85.63; LocalitySufType=100; Admin=100; Postal=100
Its seems like PointAddress scoring is only reduced when other elements are not perfect like the street name or postal city, so could extra the unit information be considered in the overall match score? As illustrated it did in the legacy locators and helpful to know the input string was not an identical match to the candidate. The scoring components are also very valuable as well and hopefully they will be incorporated soon.
@RonnieRichards The scoring for the new locators is different from the classic 10.x locators and the output component score fields are not part of the new locators. The scoring algorithm of the new locators is not something that is documented. The output fields that are returned in the output are discussed in the following topic, https://pro.arcgis.com/en/pro-app/latest/help/data/geocoding/what-is-included-in-the-geocoded-result....
If you wanted to see what the original input address was you could add the full address in a single field, then set that field as a custom output field. When you search for the address the custom output field is included in the result returned. Step 9 mentions the optional custom output fields, https://pro.arcgis.com/en/pro-app/2.9/help/data/geocoding/create-a-locator.htm.
In order to better understand what is happening with the input address and what is being returned I would need a sample of the data used to build the locator and the locator you have created. Or at a minimum see the locator properties that show the reference data field mapping and geocoding options or a screen shot of the reference data that includes the feature fore the input address and the one that is returned. If a feature exists for the base address (4791 PELL DR , SACRAMENTO, CA 95838) and not for the subaddress (4791 PELL DR STE 1)
@ShanaBritt Thanks for all the information related the PointAddress and the catagories over the years. We are having some success over here but only when we separate the PointAddress locator into 2 (one for each category). Then configure both PointAddress.subaddress & PointAddress.PointAddress into a composite locator.
The strangeness is when these categories are combined which is the default nature of create address locator, we still see 100% match for some addresses with units which do not exist in reference data. This is confusing as a default option and would assume most users would not want 100% match for a candidate which did not exist. As we tweaked the input we did get some scoring to diminish but not with the same scoring as when they are combined into a composite.
Default Result = Address inputs candidates with units which do not exist in reference are getting 100% match to PointAddress.

Individual - If the same locator is broken apart by category (subaddress vs PointAddress). Then result from PointAddress has a reduced match score (as expected it does not exist in reference).


Example: 4791 PELL DR STE 1
Should these results be the same regardless of the categories chosen?


I think our agency can move forward with this configuration we have fallen into but this seems confusing especially when differing results are returned when combined at the categorical level vs composite.
To the idea team, this idea can be closed as submitted. @ShanaBritt has provided work arounds for getting the input candidate address in the results array.
@RonnieRichards , Thanks for the additional info, however, I still do not know what the reference data used to build the locator looks like and it seems like I am missing some other details about the composite locator. Based on the info you have provided the address "4791 PELL DR STE 1" does not exist in your reference data, so the next best match is to the base address of "4791 PELL DR", where 'Ste 1' is ignored and may possibly show in the ExInfo output field as a part of the string that was not used or could not be matched to any part of the address. Since "4791 PELL DR" exists in the data the input address matches every other part of the address when 'Ste 1' is ignored. This is expected behavior. If you set the Out Fields parameter to all (asterisk) in the findAddressCanidates REST request you will get all of the output fields from the locator, which includes the ExInfo field.
Does the composite contain the same locators that references the same data with just Subaddress category disabled or enabled? What is the Result Order used by the composite? Does your data contain any subaddress features? If not, any input address with a subaddress will get matched to the base address if it exists in the reference data.
What version of ArcGIS Pro and Enterprise are you currently using?
-Shana
Everything you have captured is correct, the suite in this example does not exist. The matched record against pointaddress category does indicate the Exinfo = STE 1. This is being described as expected behavior and understand getting an appropriate match. But with these results I am more concerned about the scoring, specifically a 100% against subaddress/point address categories but lower scores when incorporated into a composite.
The composite is using the same locators, except just singular categories enabled in each. The result order in the composite is subaddress, pointaddress and then street range.
Yes some of the reference data does contain sub address features
Pro 3.1.2, Enterprise 11.1 - However these results are clearly exposed in Pro and have reference data/locators available if you need to test this further to understand.
Using the pointaddress role with both categories enables returns a 100% match but no ExInfo

Using the pointaddress role with one category enabled and the second category enabled and then stacked into the composite returns the same match candidate but the score is reduced as expected. This does contain the Exinfo as you explained.

You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.