- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Online
- :
- ArcGIS Online Questions
- :
- Re: Clustering in web map
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Good morning,
we are using the cluster on a feature service in our web map.
Our points are more than 50.000, but it's ok for us to display (when the map is zoomed out) just 50.000 points in the cluster.
We expected that when the user zoom in the map in a zone where, for example, there are around 3000 points, the cluster would have shown all the points, but it doesn't. I think it's just showing the subset of the points that were integrated in the first 50.000.
Is this the expected behaviour? The cluster cache the points and just show these ones, independently from the zoom level?
Thank you,
Stefano
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
When clustering is used the web map requests 50,000 points and determines the clusters size and location based on its relationship to points at a specific zoom level. When the scale changes, the clusters are reorganized, but no new features are requested, leaving you with the 50,000 points that are initially retrieved when the service exceeds the 50,000 feature limit. There isn't a way to control which points are used.
We are working on some projects to support clustering for larger datasets but I don't have a specific timeline to share currently.
Consider using specific zoom levels and other visualization techniques to display large sets of data.
Check out this blog for some additional ideas:
Strategies to Effectively Display Large Amounts of Data in Web Apps - ArcGIS Blog
Thanks,
Kelly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I would expect that the clustering since it is dynamic, extracts those features in the display windows and applies the clustering, but I notice that it does not.
What is did was:
- I created a featureclass with 75K random points and random values (to use in the cluster)
- I appended next to it another 75K random points, to make sure that when the first 50K feature are extracted this will be noted.
- The featureclass was published to AGOL and clustering was applied
- on a copy of the layer no cluster was applied for visual reference of point locations
When zoomed out, the expected behavior is visible, only the first 50K feature are used to create the clusters:

When I zoom to an area to the middle where no clustering is applied to part of the area, I notice that it does not read out the features within the extent to apply the clustering, but it still uses the same first 50K features.
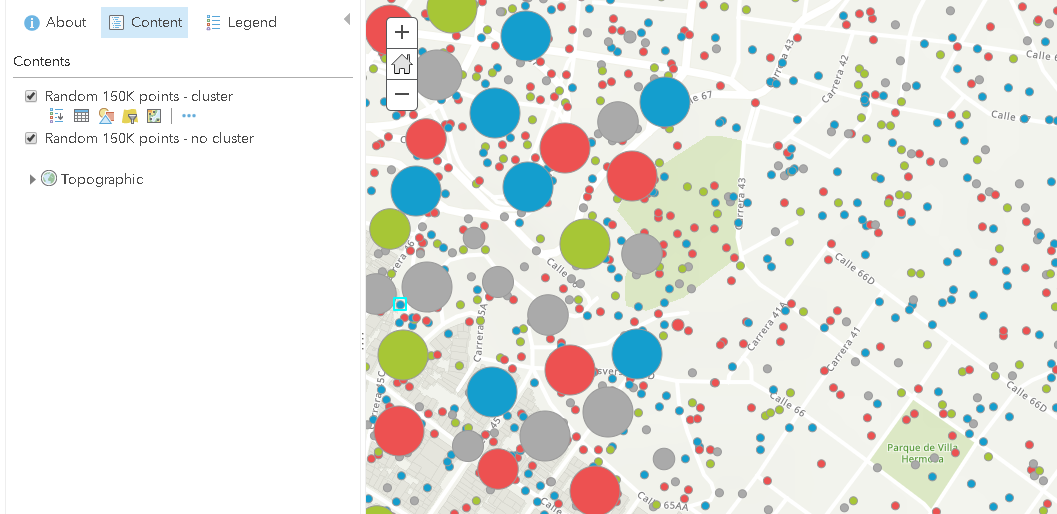
Maybe this is due to performance, but I can't classify this as desired behavior. I will CC KGerrow-esristaff to see if she can explain what is happening here.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
When clustering is used the web map requests 50,000 points and determines the clusters size and location based on its relationship to points at a specific zoom level. When the scale changes, the clusters are reorganized, but no new features are requested, leaving you with the 50,000 points that are initially retrieved when the service exceeds the 50,000 feature limit. There isn't a way to control which points are used.
We are working on some projects to support clustering for larger datasets but I don't have a specific timeline to share currently.
Consider using specific zoom levels and other visualization techniques to display large sets of data.
Check out this blog for some additional ideas:
Strategies to Effectively Display Large Amounts of Data in Web Apps - ArcGIS Blog
Thanks,
Kelly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you Kelly for the explanation.
We are looking forward to the support for large dataset!
Thanks,
Stefano
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sorry to reopen an old post.
I see @KellyGerrow referred to a blog post where it mentioned about aggregating features in hexagon bin. I think that would work fine with large datasets with hundreds of thousands or even million of features (depending on the backend database).
I was wondering why you would prefer cluster approach over aggregated-in-hexagon-bins? I'd appreciate your thoughts on this.
Tanu