- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS GeoEvent Server
- :
- ArcGIS GeoEvent Server Documents
- :
- Summarize Point Count within Polygons using GeoEve...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
Summarize Point Count within Polygons using GeoEvent
Summarize Point Count within Polygons using GeoEvent
This document will walk you through how to summarize point counts within polygons using GeoEvent. In this example, I will demonstrate how to summarize the number of crimes within each NYPD precinct. I have a feature service that is being updated with crimes, and another feature service of the NYPD precincts. The NYPD precincts feature service contains a field called crimecount that I wish to update with the number of crimes.
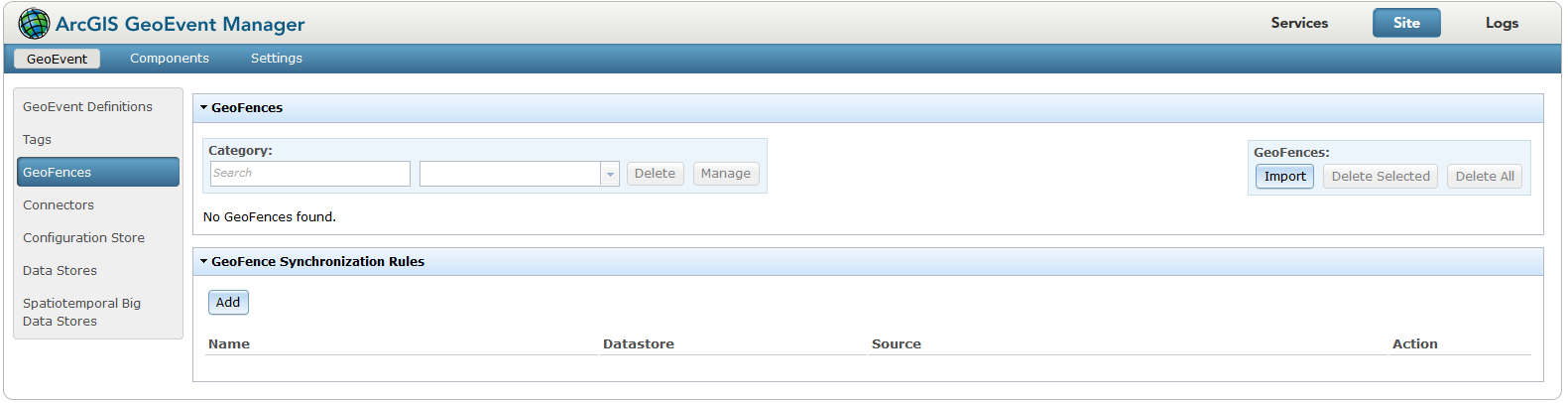
1. First I will want to add a GeoFence Synchronization Rule by going to GeoEvent Manager > Site > GeoFences > Add:
2. I will select the NYPD_Crimes feature service and set a refresh interval to update the geofences every 5 minutes. Geofences are stored in memory, so if there will be potentially several thousands of GeoFences, you may want to consider adding a Time Extent End. This will specify when a particular GeoFence is no longer in effect and will be subject to the GeoFence Purging settings in the Global Settings. In this example, I will not be setting one.

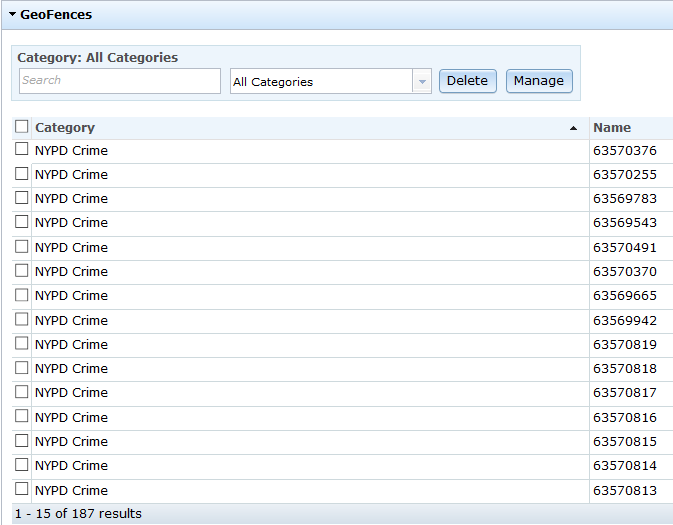
You will see the GeoFences after they are imported and will update automatically every 5 minutes:
3. Next, I will set up a Poll an ArcGIS Server for Features input connector to poll the NYPD Precincts feature service:

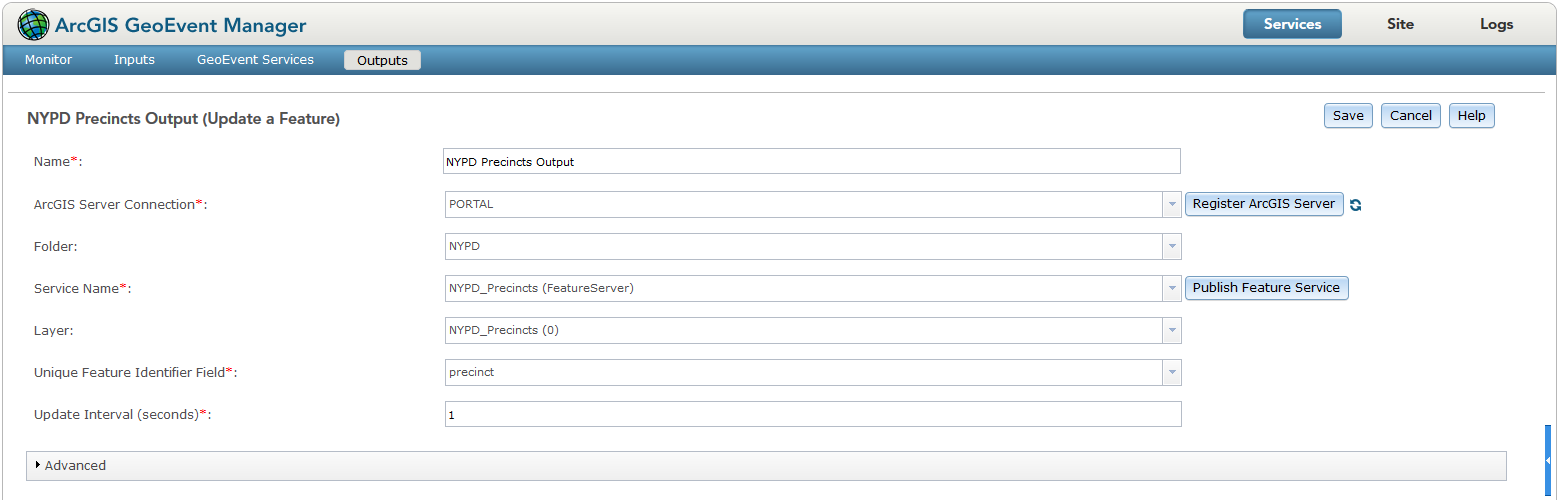
4. I will also set up an Update a Feature output connector on the same NYPD Precincts feature service:
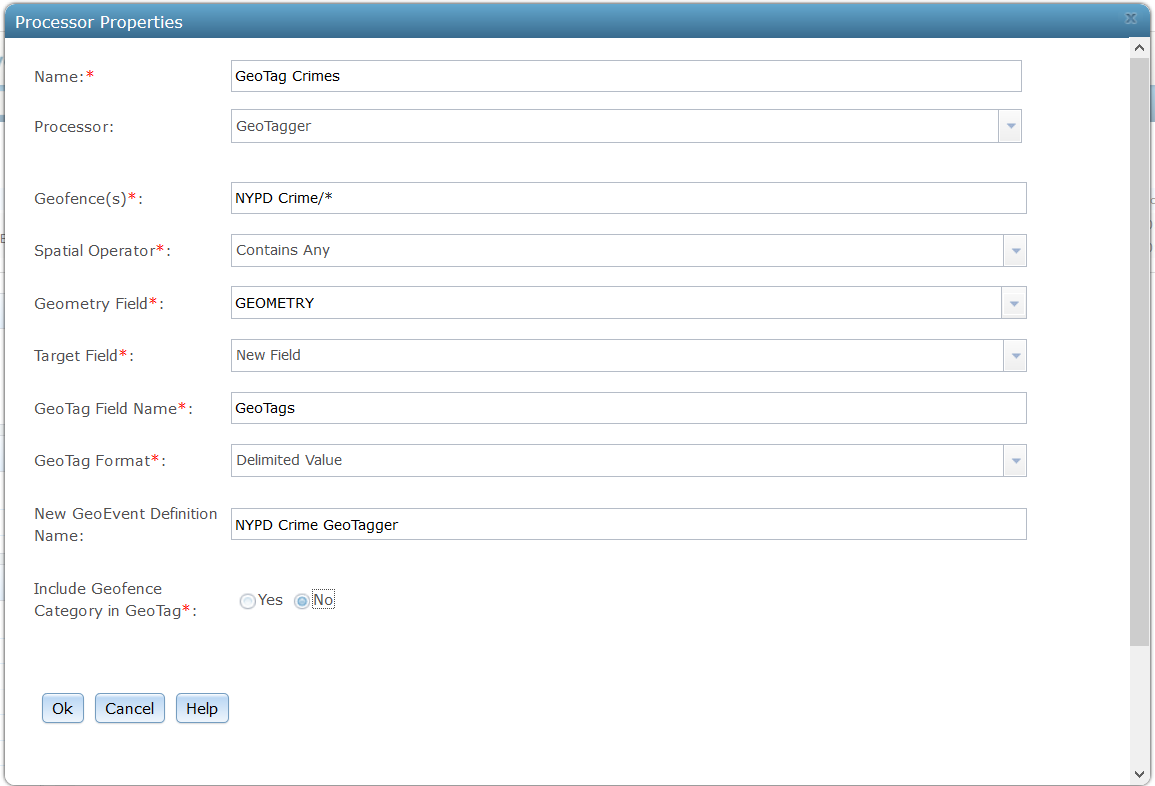
5. Next, I will create a GeoEvent Service and add the NYPD Precinct Input and a GeoTagger Processor. I specify the GeoFences I want to search for by the category name and a wildcard. The geotags are written to a new field called GeoTags and I choose the option not to include the category.
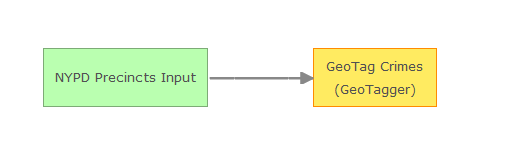
6. The GeoTags field will contain all the GeoFences that the precincts contain, separating them with a comma (i.e 63570376, 63570255). A Field Calculator (Regular Expression) processor is added to add all of the commas from the GeoTags field to a new String field, count, using the expression (,[^,]{0}).
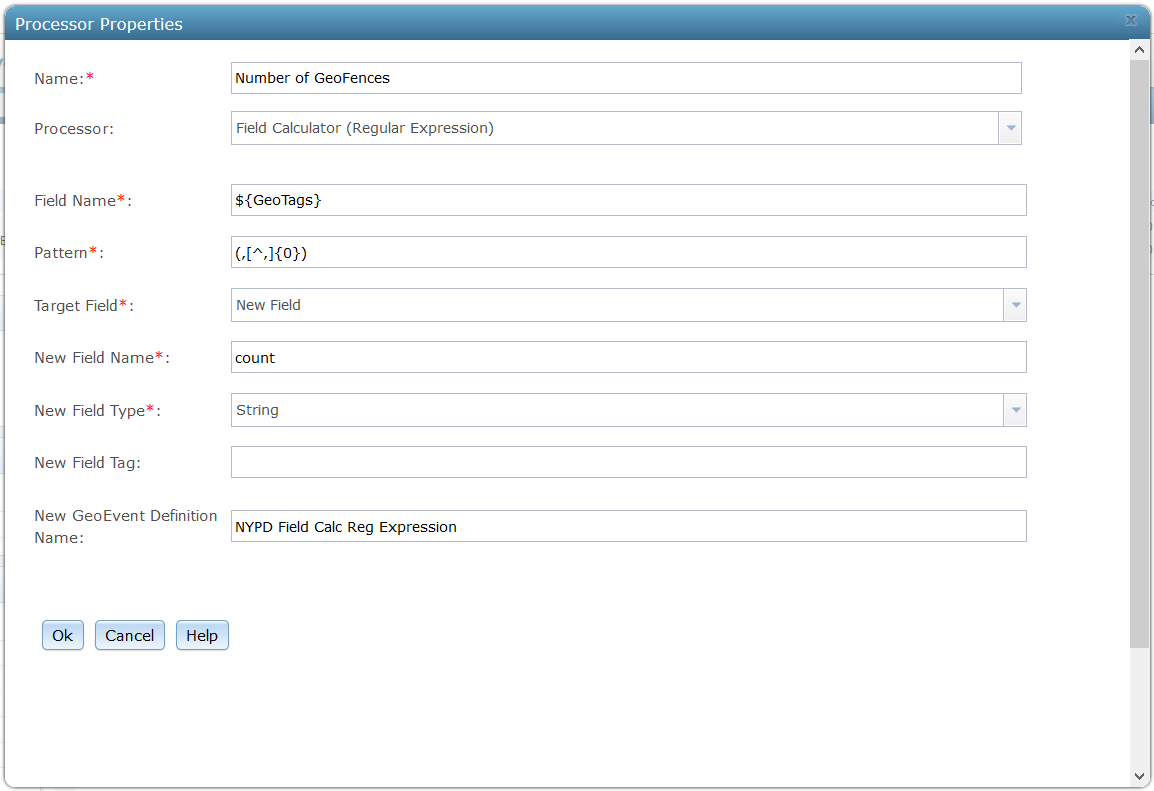

7. A Field Calculator processor is added to remove the spaces between the commas, and count the length of the String field (count). The value is written to a new field called crimes. The expression used is: length(replaceAll(count,' ',''))
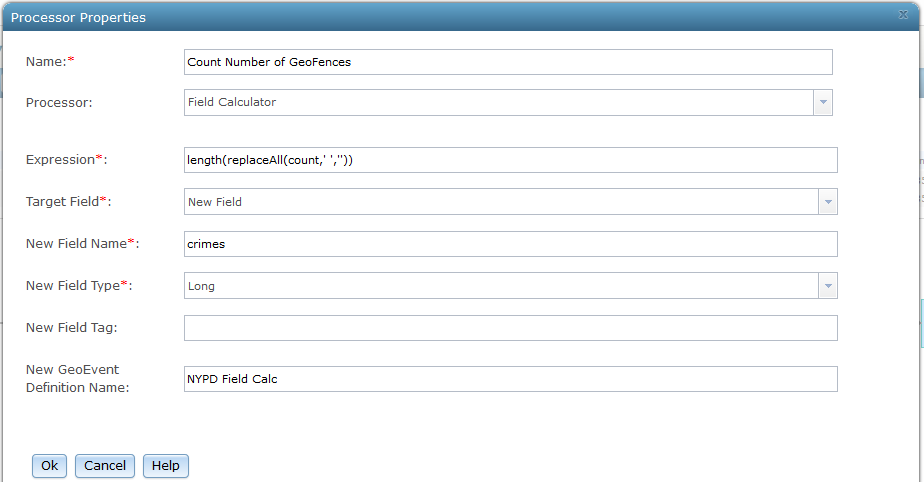

8. The previous Field Calculator won't give an accurate count. For example, if there were two crimes (i.e 63570376, 63570255) only 1 comma exists, so the crimes count would be 1 when it should be 2. So, we need to add one to the crimes field, but only when this field does not equal 0. We will add a Filter to only process crimes greater than 0:
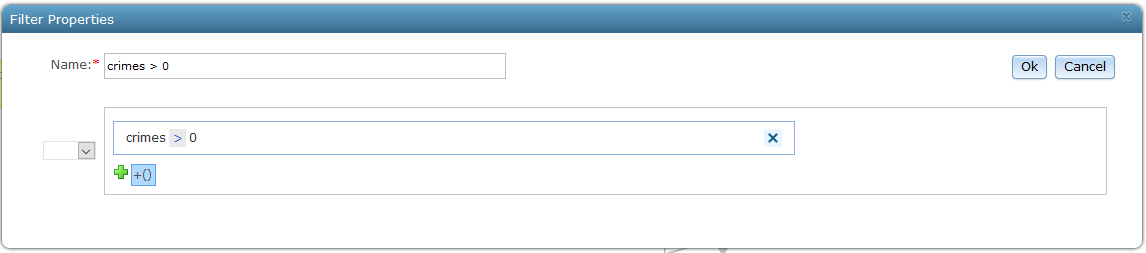

9. After the Filter, use the Field Calculator processor to add 1 to the crimes field:


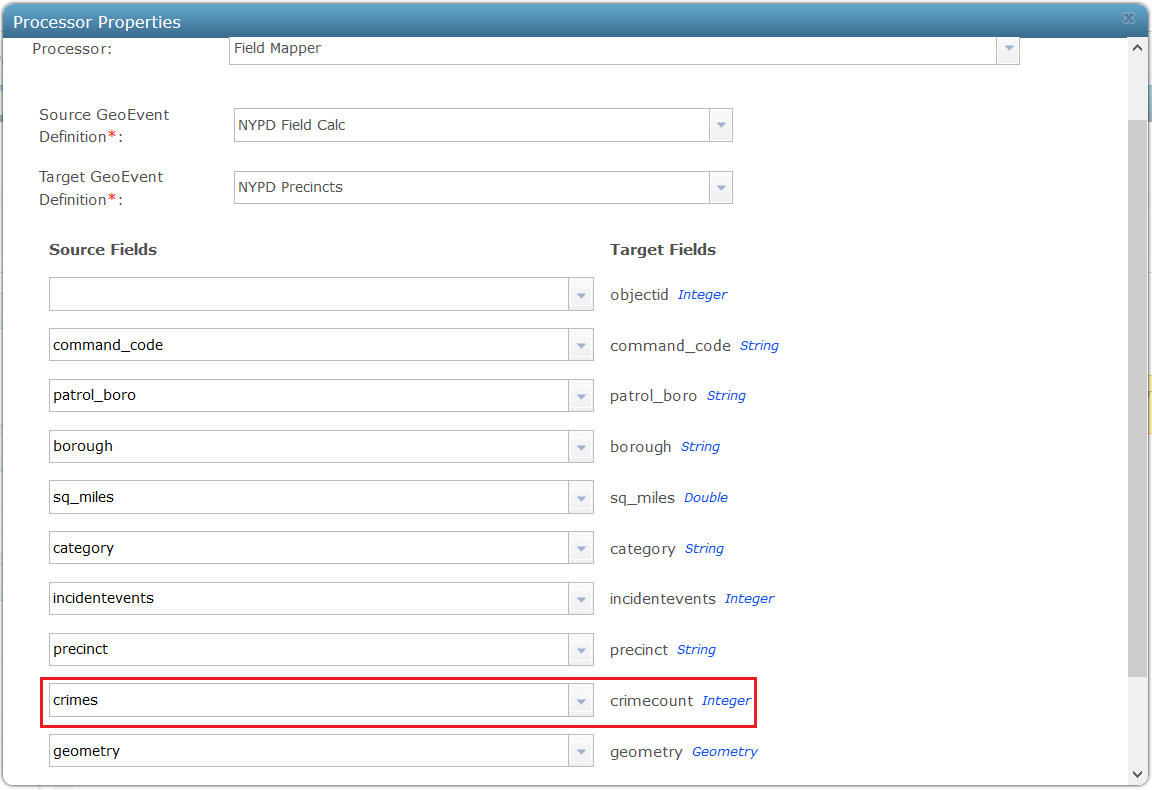
10. Finally a Field Mapper processor is used to map the crimes to the crimecount in the precinct feature service:

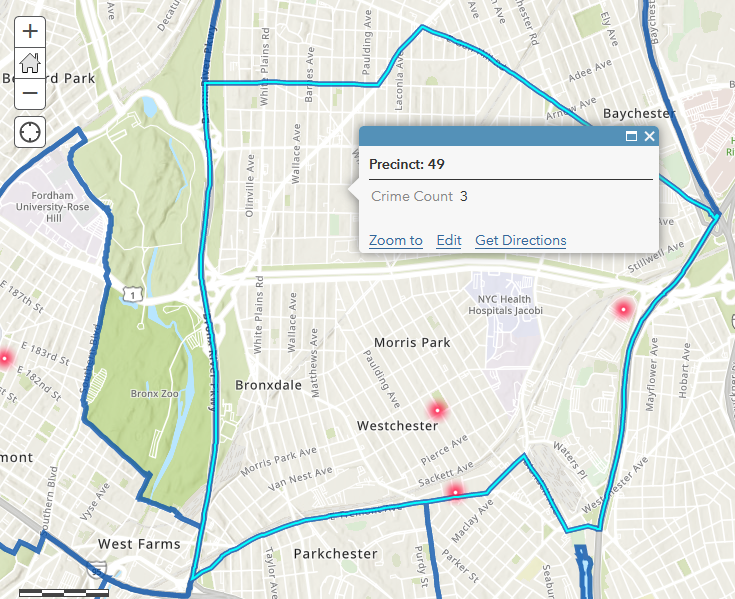
The precinct feature service should now show a count for all the crimes that occur within each precinct:
Very nicely presented Jake Skinner –
I like the RegEx you used in the Field Calculator (Regular Expression). Your pattern match – (,[^,]{0}) – is very tight and well crafted. I do not use that variant of field calculator as often as I use the "regular" Field Calculator with its replaceAll( ) function, which changes how I think about regular expression pattern matching. A regular Field Calculator also allows me to combine operations in a single expression. I tried combining the string replacement and length operations with a slightly different RegEx. I'm not sure that all of the Field Calculator's supported functions can be combined this way, but it appears to work in this case: length(replaceAll(DataString, '[0-9]{1,}[,]*', 'x'))
The above RegEx matches one-or-more digits (zero to nine) with a trailing comma (if one exists) and accepts a final numeric identifier without a comma as the last in the delimited list. Each identifier is replaced with a single literal 'x' so that the length( ) function can simply count the number of x characters. Seems to work for empty string (""), single identifier ("12345"), and multiple identifiers ("689102,0256,651,74290") ... returning lengths of 0, 1, and 4 respectively.
Null strings are a special case; tests I ran suggest that if GeoTagger found no points in a precinct's polygon and chose to assign a NULL value to the GeoTags field rather than an empty string (I can never remember which value it chooses), the combined expression will produce a NULL value, So your final filter – rather than checking count > 0 – could check NOT(count ISNULL) allowing you to also update districts with a count of zero. This might be important if a precinct was previously updated with n>0 crimes and things got quiet so the crimes count needed to be reduced back to zero.
Also, to cross-link to another topic/trick, if you do not want to carry the burden of mapping a bunch of fields whose values you do not intend to change (command_code, patrol_boro, sq_miles, category, etc.) you could use a Partial GeoEvent Definition with only two fields to update the count for each precinct feature record. Assuming precinct is your event record's TRACK_ID and unique feature identifier field, a GeoEvent Definition with only two fields (precinct and count) would protect against accidental changes to other fields by using precinct to identify which feature record to update and then only update the count for that precinct.
Thanks for the write-up –
RJ
Jake - Great post.
In steps 3 & 7 you create two new definitions, "NYPD Precincts" and "NYPD Field Calc" which you then utilize in Step 10 and as your Source and Target Definitions. When I try to do this I can't pick these new Source and Target definitions because they haven't been created yet. Did you create them ahead of your GeoEvent Service or is there something I need to change within my settings? I'm running 10.7.1
Gary Christensen, yes you will need these GeoEvent Definitions to be created. What I do is add an output to the GeoEvent service. You don't even have to attach the output to an input/processor, just add it in so you can successfully publish the GeoEvent service. Turn on the input so event(s) are pushed to the GeoEvent service, which should create the GeoEvent Definitions. Once these are created, you can add the Field Mapper processor.
@RJSunderman I'm following the expression you suggested length(replaceAll(DataString, '[0-9]{1,}[,]*', 'x')) which if I am understanding changes any length of numbers next to a comma into a single 'x' and adds an extra 'x' at the end. but what if I have an inconsistent mix of letters and numbers in the DataString? How can I search for that pattern? I want to use [0-9,a-z,A-Z] but that is not right.
Hey Russell --
The pattern match you propose [0-9,a-z,A-Z] should work for a mix of letters and numbers. The pattern specifies any single character, lower-case or upper-case letter or digit. The repetition qualifier {1,} specifies one or more repetitions matching this pattern.
You could try using the \w metacharacter which specifies "Any Alphanumeric character". But your pattern is essentially the same thing.
I use the online utility https://regex101.com to develop and test my regular expression patterns. Another good site offering a RegEx tutorial is https://regexone.com
There are different flavors of RegEx, so to be careful I would select 'Java 8' in the regex101.com web tool's left-hand options frame. That site is nice in that it explains why the pattern match is matching the way it does. All you need to recognize then is that the function expression you configure your GeoEvent Server's Field Calculator with has three parameters: The data field, the pattern to match, and the replacement for every occurrence of that pattern (in this case a single literal character 'x').


@RJSunderman Wow, that was a complete guess on asking about [0-9,a-z,A-Z], I thought I was making up something wrong! 🙂
I used the \w metacharacter, but it didn't quite do the trick because there are also spaces. BUT, thanks to regex101.com link you sent I could quickly test and figure it out.
Here is the final code, note the space after /w
length(replaceAll(DateString, '[\w ]{1,}[,]*', 'x'))
also, I learned to watch for typos. Note the space between [\w ] and {1,}
length(replaceAll(DateString, '[\w ] {1,}[,]*', 'x'))
Good stuff, thanks for the help!