Introduction
Often computers think they are smarter than humans, but since it is the human whom programs the computer code to perform a repetitive task, we know there are times additional tweaking can be beneficial for a successful outcome of a given workflow. XML data structures with namespaces is no exception.
If you have not started your XML quest off by reading the blog, XML Data Structures - Characteristics and Limitations, written by RJ Sunderman, I highly recommend starting there. It provides a solid foundation for working with XML data structures. What we will explore in this blog is XML data structures that include the use of namespaces, in particular, that of a Web Feature Server (WFS) service. The first question here might be,what exactly is a "namespace?" The namespace refers to the pre-fix of the XML element, for example, <wfs:WFS_Capabilities>. When working with XML data that includes namespaces there will be an XML <schema> element with one or more attributes containing URLs describing the XML structure and all namespaces used in the document. This schema declaration often looks something like:

The xmlns:wfs="http ://www.opengis.net/wfs/2.0" attribute in the illustration above indicates the elements and data types used in the schema come from the "http://www.w3.org/2001/XMLSchema" namespace. The same attribute also specifies the elements and data types that come from the "http://www.w3.org/2001/XMLSchema" namespace should be prefixed with wfs. For more information, see XSD - The <schema> Element.
At this point, it should be noted that WFS services in ArcGIS Server use Geography Markup Language (GML) to encode the feature data. In order to represent geographic information, GML is the means used for XML. The GML used in ArcGIS Server WFS services is the Simple Features profile. For more information, see the technical notes in Why use a WFS service?.
Explore a WFS service
To begin our adventure, you will need an existing WFS service published that ArcGIS GeoEvent Server can ingest. You might not be aware, but ArcMap provides sample data that can be accessed, by default, in the following location: C:\Program Files (x86)\ArcGIS\Desktop<version>\TemplateData\TemplateData.gdb. Keep in mind, you are working with the actual features, therefore, the feature class must reside in a registered enterprise geodatabase before proceeding, see Data sources for ArcGIS Server for more information. For this blog, I have added the USA Cities feature class to ArcMap (ArcGIS Pro works too!) and published it as a service to ArcGIS Server.
NOTE: Avoid using special characters in the layer name represented in the Table of Contents in ArcMap or ArcGIS Pro.
During the publishing process the following capabilities were enabled in ArcMap.
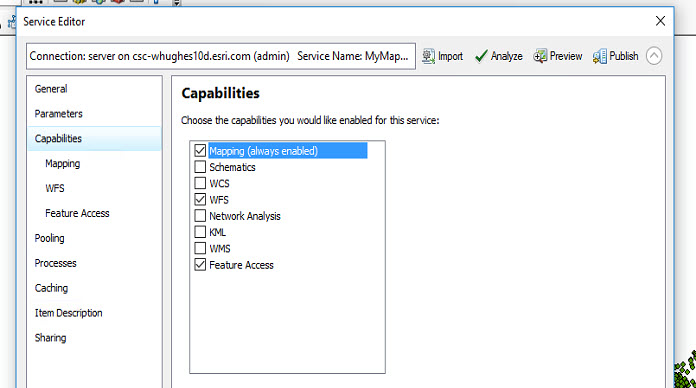
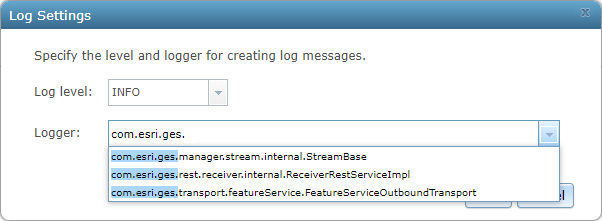
If you are working with an existing service, you can use ArcGIS Server Manager to ensure you have the appropriate capabilities enabled on the service.
 Select and configure capabilities page of published service from within ArcGIS Server
Select and configure capabilities page of published service from within ArcGIS Server
Once the service is finished publishing the service should be shared with Everyone if your ArcGIS environment is a federated ArcGIS Enterprise deployment. Otherwise, continuing with the workflow below might not work as expected. In the ArcGIS REST Services Directory, browse to the endpoint for the published service and click the WFS link, which then performs a GetCapabilities of the WFS service:
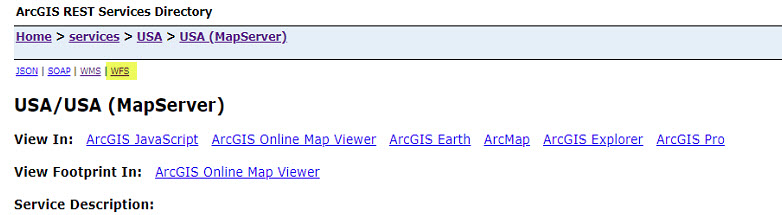
Okay, so far so good, but you will need to work with the features of the WFS service which requires sending the GetFeature request query parameter. To accomplish this, you need to know the name of the feature element. You can use the DescribeFeatureType parameter that describes the field information about one or more features from the WFS service. In this case, you are working with Cities which is returned from this request.
The request resembles:

And returns the following XML information:

For additional assistance on this and other parameters, see Communicating with a WFS service in a web browser. Now that you have all of the parameters for the WFS services, you can go ahead and request those features.
Your request will look something like:

And the features returned will look like the following:

The above illustration shows one feature from the GetFeature request. Depending on how many features your service contains, the request might take anywhere from a few seconds to several minutes, the request may also flash a blob of unformatted text in the browser. Be patient and wait for the GetFeature request to perform its magic, all features will be returned as formatted XML. The sample data used here contains 3,159 cities within the USA dataset, this information is returned as part of the GetFeature request within the first XML element. Although it is not displayed here, just look for the XML attribute numberReturned="3159". Note that, since the XML data structure for the WFS service also contains GML data, there is the ever important X and Y location information listed under the <gml:pos> attribute, So, enough about WFS services, let’s get to the fun that is GeoEvent Server...
Working with XML namespaces in GeoEvent Server
The XML/GML namespace and hierarchy found in a WFS service can get in the way when using default values to configure a new “Poll an External Website for XML” Input Connector in GeoEvent server. For example, if the above GetFeatures URL for the WFS service query parameter is specified, leave the XML Object Name unspecified, and allow GeoEvent Server to auto-generate a GeoEvent Definition for us, below is the resulting GeoEvent Definition that is created:
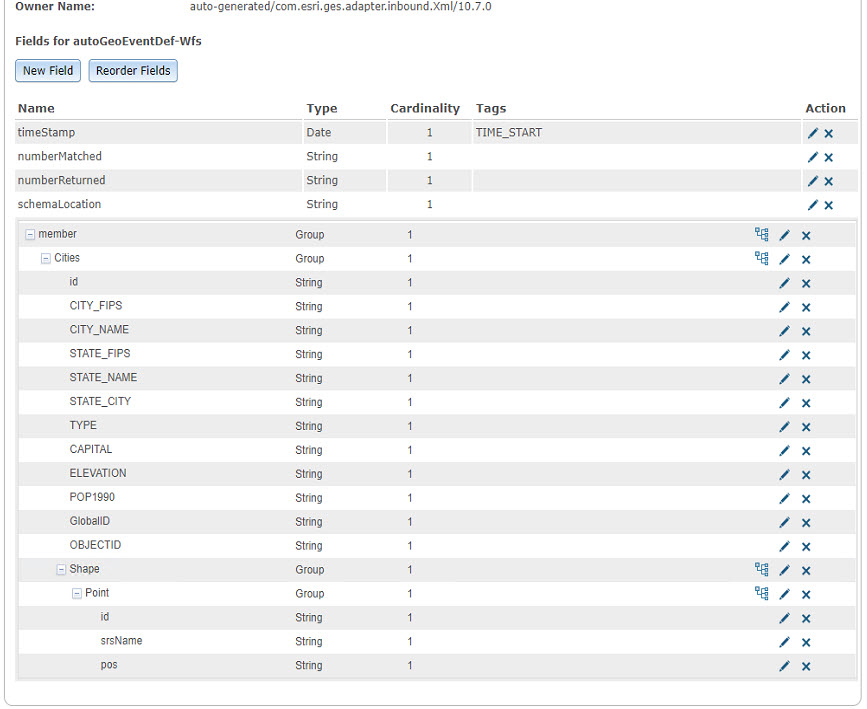
If we compare the GetFeatures request to the GeoEvent Definition they match up perfectly at first glance. However, notice that all the namespaces have been stripped of the attribute names. Upon further observation there is no need for the “metadata” above each “member” attribute (e.g. numberMatched, numberReturned, etc.) Also, we know that each “member” should be processed as a separate event record and therefore, a value for the input connector’s XML Object Name needs to be specified somehow. Looking back at the screenshot above of the GetFeatures request and the GeoEvent Definition, the logical choice in this workflow would be to use the wfs:member to tell the input connector to look in that list for individual event records.
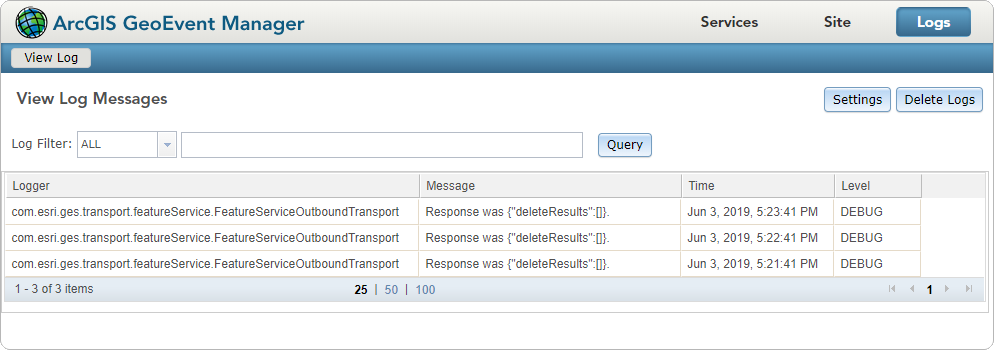
By doing so, whereby the wfs:member is entered as the input connector’s XML Object Name, the event count for the input connector does not increment. Even if the modified input connector attempts to create a new auto-generated GeoEvent Definition with XML Object name specified the count does not increment. Further, if you stop the input, update the properties again, save the input and then restart the input, an ERROR is logged from the com.esri.ges.adapter.xml.XmlInboundAdapter indicating us that it is Unable to parse input '' into spatial reference. This, is, more than likely, where the GML/XML namespaces are getting in the way.
There are two paths the GeoEvent Definition can take from here. If you are lucky, you might find your XML data structure is such that it does not contain a double nested hierarchy like the one above. In this instance the existing GeoEvent Definition can be modified to include the XML namespaces and then you can carry on. However, with a WFS service, manually creating the GeoEvent Definition is necessary. To do so, you will need to specify USA_USA:Cities as a "Group" element, specifically calling out each attribute and element beneath that group (pre-fixing the namespace designation) while taking care to also map the nested hierarchy for the shape element too, Once you create a GeoEvent Definition with these changes applied, you should be able to successfully ingest event data into GeoEvent Server.
Below is the GeoEvent Definition created to include attributes and the corresponding XML namespace. Take note of the USA_USA:Shape group, with its nested element gml:Point, which is also a group and contains an element gml:pos. Also notice that the feature dataTypes can be specified in the GeoEvent Definition, which can be obtained from the WFS Describe Feature Type results.
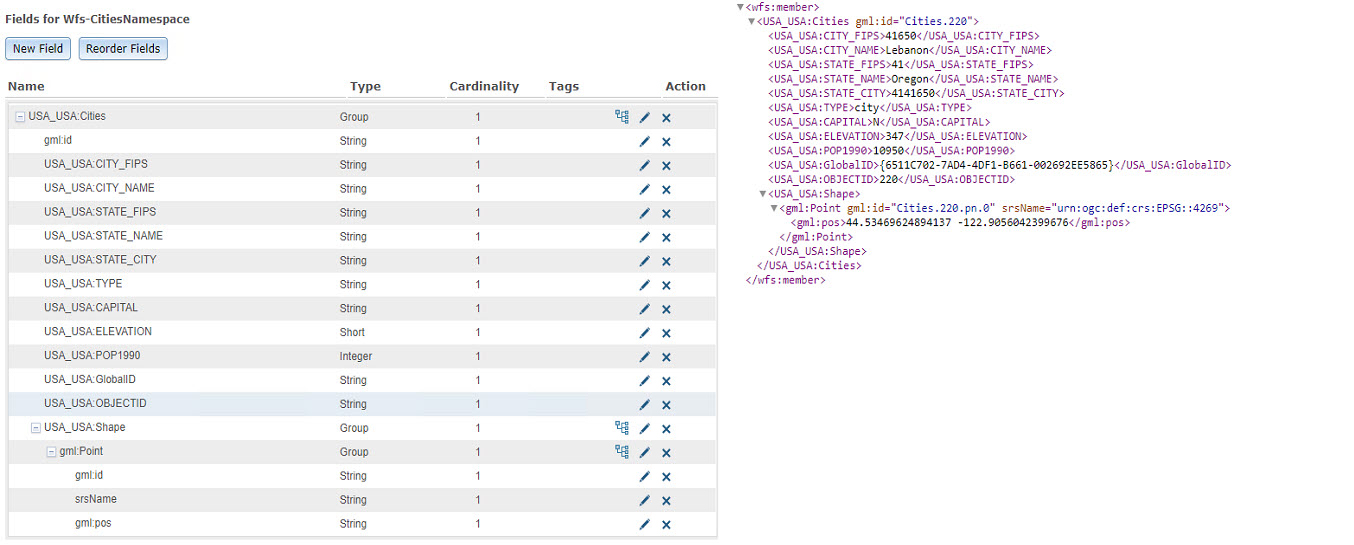
You may be thinking the namespace for this cities feature looks a little strange, let me explain. When this data was published to ArcGIS Server it was placed in a folder named "USA". So, just like the folder name is reflected in the REST URL it is also added to the XML namespace as USA_USA.
Below is the configured “Poll an External Website for XML” Input connector along with an initial GeoEvent Service.
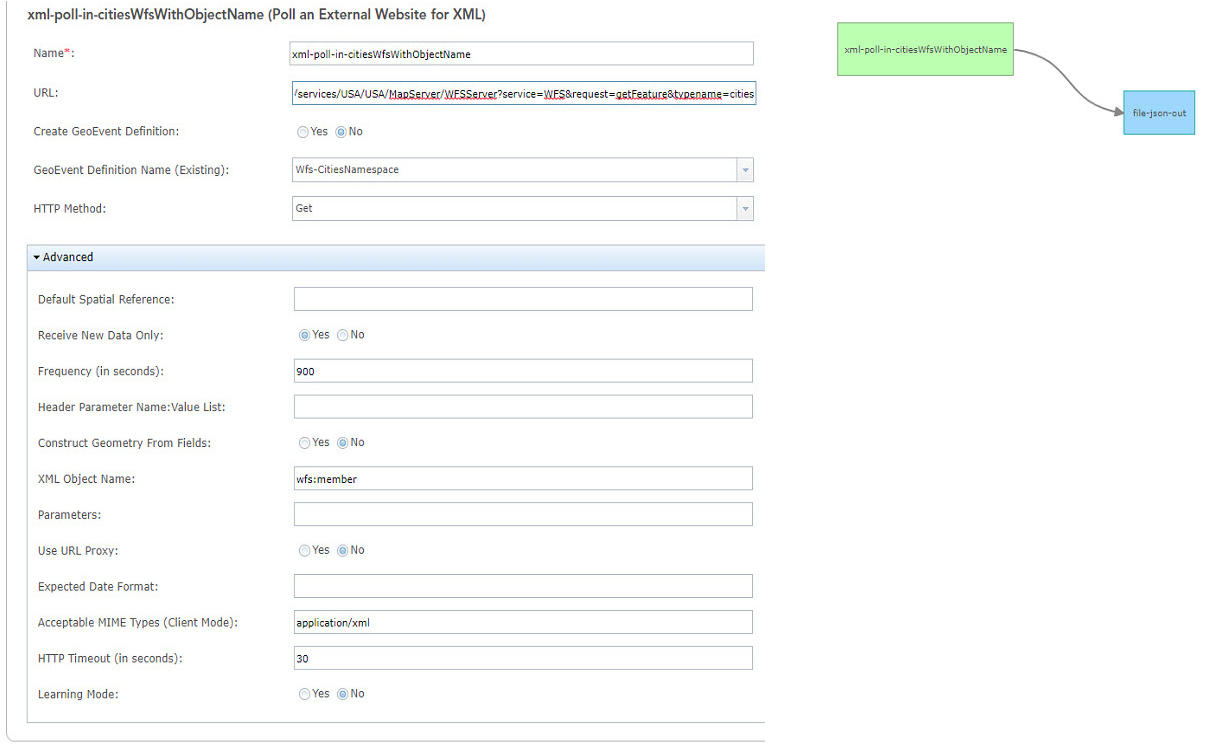
As a best practice, GeoEvent Definitions should be a flat representation of the data being ingested. Therefore, it is recommended you re-map those ingested event records. This magic is possible by using the Field Mapper Processor. To start, you will need to create an additional GeoEvent Definition without any of the group elements or namespaces as the new schema to which you want to map the received data. In addition to flattening the structure, this provides you an opportunity to rename all the attribute fields if you choose, I did not in this case. You will, however, want to remove the ":" and the unnecessary XML namespace pre-fixes, which in the example above is USA_USA and gml. The ":" will cause problems later in your GeoEvent Service if you do not remove them. Go ahead and create the flat definition at this point.
With the flat GeoEvent Definition created, you should now have the auto-generated GeoEvent Definition from the XML data structure of the WFS service, which was modified to include the attributes and XML namespaces. In addition, you should also have a second GeoEvent Definition that is flat and includes a Geometry field and structure illustrated below.
If you are wondering how we are going to get the Latitude and Longitude from that pos string field, read on.
Working with Geometry
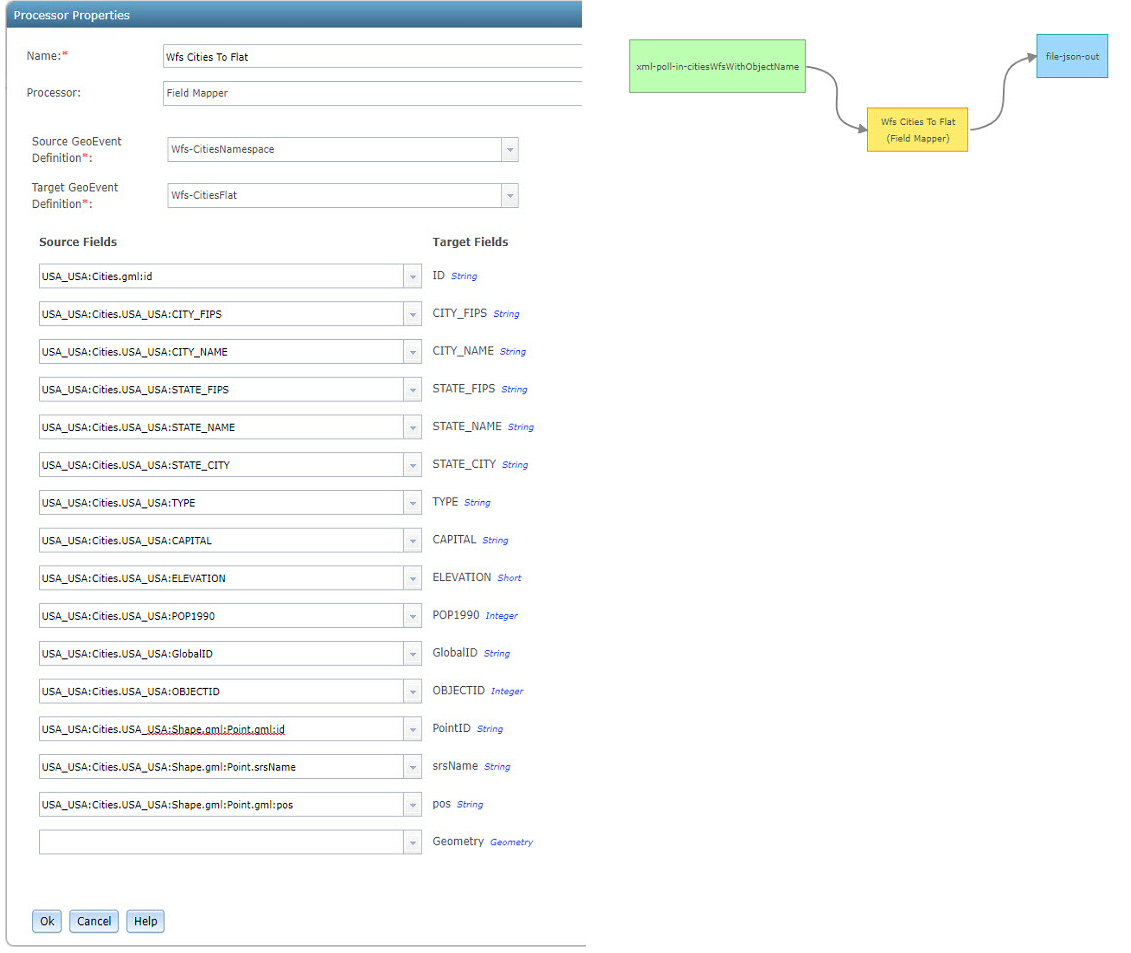
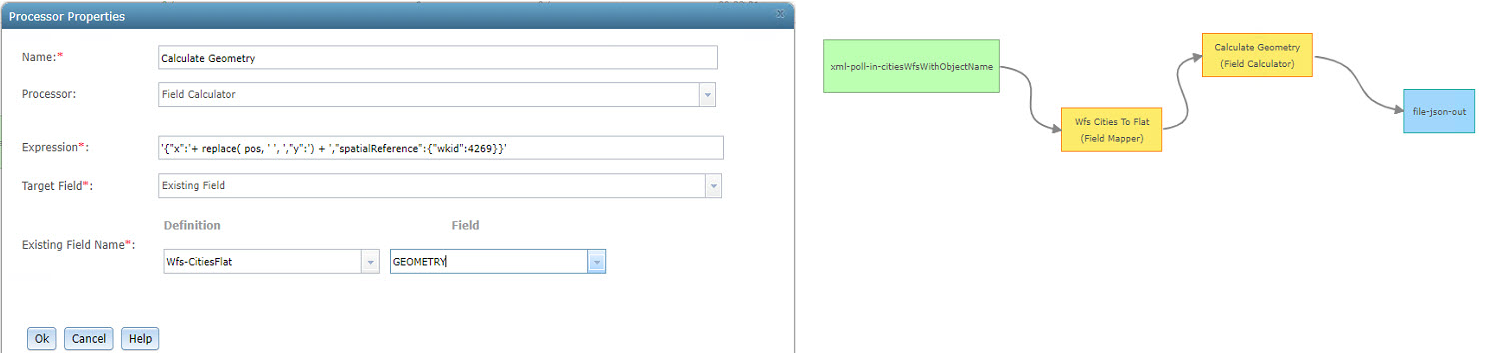
The finish line is close, we just have one more thing to address, but the coordinates in the pos attribute string field need to be converted into a point geometry. The key to this conversion is to recognize that pos is actually a single string containing two coordinate values separated by a space. In this case, the Field Calculator Processor can be used with the expression '{"x":'+ replace( pos, ' ', ',"y":') + ',"spatialReference":{"wkid":4269}}' to convert this string into a JSON string representation of an Esri point feature.
The above expression targets the literal space between the first coordinate and the second coordinate and replaces it with the literal string:, "y":. The expression also prepends the literal string {"x": and appends the literal string, "spatialReference":{"wkid":4269}} which completes the geometry string with a spatial reference. Remember, the spatialReference can be found in the srsName attribute field.
Now, let’s explore how this would look in a configured Field Calculator Processor along with the completed GeoEvent Service.
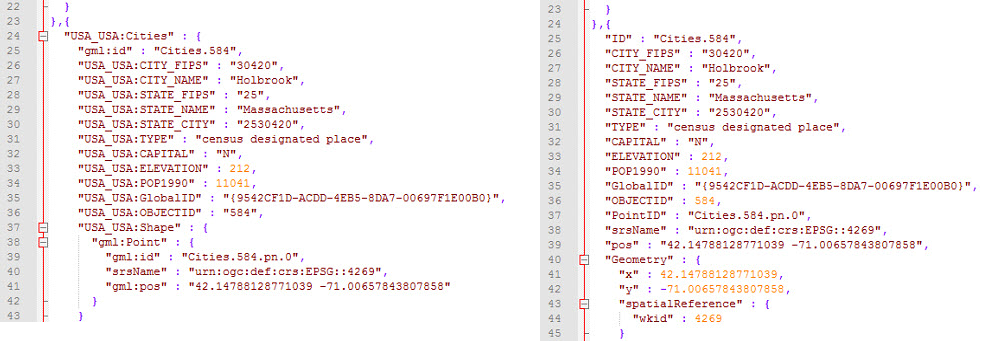
So far, the GeoEvent Service has been writing out to JSON files, to bring this full circle let’s compare the JSON output from the auto-generated GeoEvent Definition to the JSON file after the Field Mapper and Field Calculator Processors have processed the manually created GeoEvent Definition.
Conclusion and References
I hope the information presented above is useful and provides insight into working with WFS services in GeoEvent Server.
As you may have noticed, a lot of the work was related to XML data structures. An additional resource I find useful when working with XML data is the free program, Microsoft - XML Notepad 2007. For help with regular expressions try regex101.
You can read more about creating JSON string representations for Esri feature geometry in the How to switch positions on coordinates GeoNet post. There’s also a slightly different approach discussed in the Appendix of the Introduction to GeoEvent Server however you would have to slice the two coordinate values out of the string and save them as separate attribute values to use that approach.
I cannot finish this Blog without also mentioning another great Blog written by RJ, JSON Data Structures - Working with Hierarchy and Multicardinality. His discussion on hierarchy ties in nicely with the XML Data Structure.



.png)