- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- Re: ArcGIS Server Directories on EFS in AWS
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi All,
This question has been asked before, but I thought I would get a refresh of current thinking.
The Esri supplied Cloudformation template for an HA AGS server site with multiple AGS machines utilises an EC2 instance in Autorecovery mode acting as a file share for use by the AGS site for the Server Directories. (with S3 & DynamoDB for configuration)
Like this
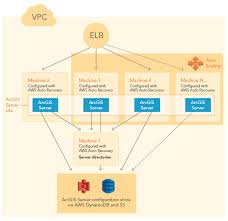
But Autorecover only works in a single Availability Zone and if the entire AZ is lost – theoretically your site will die and only be recoverable from any snapshot backups you have configured for the EBS volumes attached to the File Server.
The ESRi Australia Managed Cloud Services team Is using ObjectiveFS across two Linux EC2 (in different AZ) to provide a Samba share that can be used for the Server Directories, but this seems like a lot of config overhead.
There is another Esri supplied pattern illustrated when using AGS in Docker (experimental at 10.5.1 and not recommended for Production) that uses EFS as the storage for Server directories (and config)
https://s3.amazonaws.com/arcgisstore1051/7333/docs/ReadmeECS.html
Like this
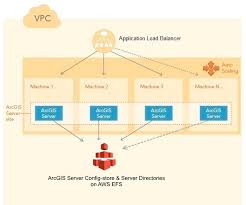
My question – and I am asked by clients fairly regularly, is – why don’t we recommend EFS as the HA File Store for Server directories?
I am aware that the Esri recommendation is to have a file store that provides low latency high volume read/write performance.
Is EFS not fast enough? (that is what I have been telling people up till now). Are there any benchmarks that give some performance comparisons?
Why is it OK to provide an EC2 instance with Autorecover as an alternative HA option when this would fail in the event of an AWS availability zone outage?
And, as a bonus question,
What is the equivalent answer for Azure?
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi David,
Thank you for sharing this information. We are now in the test phase of migrating our current Production ArcGIS Enterprise architecture into High available ArcGIS Server + Portal using FSx as ArcGIS Server directory store. So far all seems to be going well. However, We are yet to test high volume of request with this configuration. There are plans to have a couple of Flood Analysis layers to be posted to Living Atlas. Have you ever encountered any such configurations with layers being shared to Living Atlas?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
EFS has now been blessed by professional services.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
can you elaborate and/or provide some links?
I presume this would be for Linux deployments only.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
We have a solution at the government agency I work for that needed to move to both HA and DR configurations (that San Antonio data center lightning strike caused a 15 hour outage). We were avoiding the same single point of failure you mentioned that stems from the file share. Auto-recover doesn't work when the data center is down. We deploy multi-AZ primary and multi-AZ dr environments so if a single data center gets the cooling systems shocked to death, or whatever, the other AZ is still humming along. If the whole region goes down then the ip forwards to the DR environment on the other side of the country.
At the time we began that project EFS could not handle the volume of small, fast locks required by arcgis, and thus it was an unsupported configuration. So we moved to test using SoftNAS which works well. Because we need to stay on supported configurations (what's the point of premier support if you don't) we engaged with ESRI professional services to get SoftNAS 'blessed' and also noted that since the time of that docker instance that you mentioned EFS has been improved by AWS. The improvements that were made to EFS allow for the many short and fast locks that ArcGIS needs and the professional services team blessed it for use in prod. e.g. it is a supported option for the file share now. Professional services tested and both SoftNAS and EFS meet the need now. Since we deploy primarily to gov cloud on aws we opted to go with EFS.
Cheers!
Frankie
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As far as Linux-only I'm not sure on that. We only deploy on the RHEL hardened gov provided images. Basically terraform them into existence and then ansible them into their role (portal, host server, geoevent, etc). Since I am the GIS guy, not the dev/ops or infrastructure guy, I really don't have an answer for you. But if you can mount an EFS to Windows I can't imagine why it would be any different. Again, not my swim lane...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sadly for us,
From: https://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/AmazonEFS.html
- Important
Amazon EFS is not supported on Windows instances.
and from: https://docs.aws.amazon.com/efs/latest/ug/mounting-fs.html
- Note
Amazon EFS does not support mounting from Amazon EC2 Windows instances.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Has anyone had any success using FSx for OpenZFS as a shared file store? Our environment runs on Windows (ruling out EFS) and is not domain joined (ruling out FSx for Windows File Server).
The ArcGIS setup process failed when trying to use FSx for OpenZFS and since we were under time constraints, we abandoned this approach and were forced to use an EC2 instance as a file share.
Unfortunately, this EC2 instance and the fact that we would need to restart our installation when patching is a weak point in our installation that we would like to fix. Has anyone else encountered this issue with FSx for OpenZFS?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello Paul,
I don't have any experience with FSx for OpenZFS but I would have thought if it looks like a SMB mountable file share then it theoretically may work. The question would be does it perform for lots of small writes & reads with read after write consistency to allow the multiple ArcGIS Servers to each see the same changes effectively concurrently?
To help you move forward, have you considered deploying initially using the "standard" fileserver and then moving the Server Directories to the location that is actually FSx for OpenZFS ?
Or is your problem that even though you can mount the FSx file share and access with a UNC path, the ArcGIS Server installation won't allow you to use that path for Server directories?
Have you ensured that the Windows Service account you are using for the ArcGIS Server has permissions to read/write in the FSx share?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
My first post in this conversation but I've been monitoring it for a while.
I'm currently using AWS EC2 Image Builder to produce a new AMI each week that contains a stand-alone installation of ArcGIS Enterprise Server (currently 10.9 on Windows 2022), a variety of Map Documents and some embedded FGDB files.
After the AMI is produced, we use CloudFormation to spawn a new AutoScalingGroup & ApplicationLoadBalancer and after the new cluster has passed the automated tests we cut-over to it by modifying the DNS record. Several hours later we terminate the old cluster.
This has served us well for more than 12 months across 7 different clusters of ArcGIS Enterprise Server in 4 different AWS accounts; but each server is essentially its own ArcGIS Site.
I'm now in the process of incorporating FSx into the mix and I'm hoping to use this same immutable infrastructure pattern in conjunction with webgisdr to allow us to operate an instance of Portal in AWS that essentially jumps to a new FSx sub-directory and new EC2 cluster each week.
So far I've automated the process of provisioning a new AD User Account using CloudFormation (AWS do not provide this functionality I had to DIY). The newly provisioned AD account has permission to access its own home directory on a long lived FSx share and I've just completed a unit of work to allow a single node ArcGIS cluster to move its' local ArcGIS Site to the FSx share during bootstrap (moving both the config-store and arcgis directories for now but I'll look into DynamoDB for the config-store soon).
My next unit of work is to use a network lockfile to allow a multi-node cluster of EC2 instances to boot for the first time; have one of the nodes move it's local site to the network share and the remainder of the nodes will wait until the common ArcGIS site is ready and then they'll join it and erase their unused local site.
After that I'll move onto experimenting with webgisdr in the hopes that I can pre-emptively vertically scale the portal instances and/or FSx performance to speed up the backup and restore process as we transition the running portal to all new virtual hardware each week.
I mentioned that I baked some FGDB reference data into my AMI and I found that the latency was dreadful when accessing this data on a freshly created EC2 instance. So I split the drive over four EBS volumes using RAID0 to quadruple the number of IOPS available; then I wrote an application that sequentially reads every file on the drive on the first boot only to "Pre-Warm" the underlying blocks. This application uses ~60 threads to max out the IOPS. The four volumes are GP3 at 125MB/s throughput each but with RAID0 and maxing out the IOPS it doesn't take very long to pre-warm the volume and eradicate the high latency on the first interaction with each block. "Total Files: 2,266 of 2,266 (100.00%), Data: 77.21 GB of 77.21 GB (100.00%), In: 0:03:41, Avg: 357.71 MB/s"
Please share your experience on operating ESRI on immutable infrastructure in AWS; I'd love to hear what you've accomplished.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Ryan
as you are about to discover, ArcGIS Enterprise is quite a different beast to Standalone ArcGIS Server.
If you are thinking of using webgisdr - I presume you are aware that this backs up all the tiers (Portal, all Federated Servers and ArcGIS Data Stores), you may find you are getting a larger and slower backup than you anticipate.
Aside from that - very interesting method to speed up file access by pre-warm-up. You may find this is a good idea for FSx fileshares too.
Have you considered using a UNC path and DNS alias for Fileshare used for Server config and directories? This may allow easy change to a newly recreated FSx share without needing to worry about updating any existing service configurations that are linked to data paths.