- Home
- :
- All Communities
- :
- Developers
- :
- ArcGIS API for Python
- :
- ArcGIS API for Python Questions
- :
- Field calculation with multi-row sub-queries?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Field calculation with multi-row sub-queries?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have two tables:
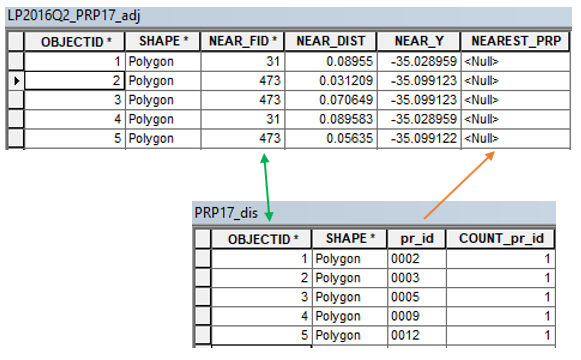
The top table LP2016Q2_PRP17_adj has the field NEAREST_PRP that needs to be updated with the values held in the pr_id field of PRP17_dis. The related fields here are PRP17_dis.OBJECTID = LP2016Q2_PRP_adj.NEAR_FID (green arrows).
A simple table join in ArcMap isn't working as there are multiple destination rows for NEAREST_PRP for every single pr_id row entry (orange arrow). For example, when PRP17_dis.pr_id = '0002' (one row), LP2106Q2_PRP17_adj.NEAR_FID = 1 has 9,422 corresponding rows that need the '0002' value.
I don't know how to approach this table update issue as it appears to require iterating through multi-row sub-queries. Given that the top table is large (6.13 million rows) I'd like to know if anyone can advise me on how to use arcpy or another approach to solve this? Any help would be most appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think you could use Richard Fairhurst's Turbo Charging Data Manipulation with Python Cursors and Dictionaries.
Basically, read data from PRP17_dis into a dictionary using OBJECTID as the key and pr_id as the value. Then loop through the rows in 2106Q2_PRP17_adj and, where NEAR_FID equals the dictionary key, place the value into NEAREST_PRP. For code, see Richard's blog, Example 1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This should be doable through a join and field calculation. What exactly have you tried for joining? Did you use the GUI or ArcPy? What parameters did you set for the join?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joshua,
Although I am grateful for Randy Burton pointing me to a great arcpy resource on cursors, I did manage to update the larger of the two tables using a join within the ArcMap GUI. I don't know why it didn't work previously - perhaps not enough available RAM at the time? - but once joined, the Field Calculator operation completed the update in about 90 minutes.
The join was based on LP2016Q2_PRP_adj.NEAR_FID = PRP17_dis.OBJECTID, then calculating LP2016Q2_PRP_adj.NEARPEST_PRP = PRP17_dis.pr_id.
I do think it's worth attempting the same update using the arcpy.da.cursor method, if only to see if it works faster than 90 minutes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
90 minutes seems absurdly long. What is the backend data store? An enterprise geodatabase? If so, what is your connection to the DBMS like? Are you using an edit session or not? If a file geodatabase, is it stored on a network file share?