- Home
- :
- All Communities
- :
- User Groups
- :
- Addressing
- :
- Questions
- :
- Re: Including the state in input address fields si...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Including the state in input address fields significantly slows down performance when batch geocoding with the Geocode Addresses tool
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have published a geocode service from a composite locator which was created via the create locator tool in ArcGIS Pro 2.6.1. The Locator covers the entire state of New Jersey so it includes nearly 4 million address points along with road centerlines. With that being said maximizing performance has been a big issue. I have a table of address that I batch geocode in ArcGIS Pro as part of the performance testing. This table takes me 4 minutes and 30 seconds to complete. I noticed however, that when I leave out the state from my inputs the table takes 56 seconds to complete. The state values are all NJ in the input data used to create the locator and they are all NJ in the table I am batch geocoding. I am curious why there is such a big difference in performance and how I can assure that faster performance is achieved by our users. I could leave the state values out of my input data or provide guidance to users to not enter a state, but neither of these are ideal.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Stephanie,
See the following doc topic all the way at the bottom.
Fundamentals of alternate name tables—ArcGIS Pro | Documentation
The image at the bottom shows a fully normalized reference dataset where all cities are in the alternate city name table but the logic still applies. You can keep the city in the primary featureClass but have all alternate city names for the primary city in the alternate city name table with the same CityID value. You also wouldn't need a "Primary Name Indicator" fields either because the value from the primary featureClass is used as the primary.
At a basic level it would look something like this (obviously the Primary table would have many more fields).
Primary reference data:
City | City JoinID
My City | 1
My City 2 | 2
Alt Name Table:
Alt City | Alt City JoinID
My City Alt1 | 1
My City Alt2 | 1
My City Alt3 | 1
My City 2 Alt1 | 2
My City 2 Alt2 | 2
My City 2 Alt3 | 2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sorry let me rephrase the question, that was if multiple features have the same alternate look up names. Based on the example at the bottom of the doc you sent. If two of my streets are in the same city ( Mills St and Center St in this example) rather than having a unique city id for each street to link to the alternates, I should be able to use the same one for the same alternates shown below where cityid 2170 is removed and replaced with 658 correct?

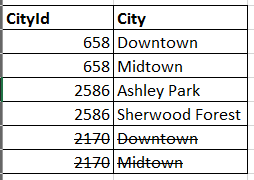
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Stephanie,
Yes, that is correct. Instead of having a bunch of duplicated IDs for streets, you can use the same ID for each street in that city.
Brad
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink




Stephanie
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Brad, I can get this to work with a many to one relationship i.e. multiple roads in a city use the same city id to relate to one alternate city name. When I have multiple alternate city names however and am trying to relate these to multiple roads within the same city via the same city id, this is where I run into issues. Do you have any suggestions? I don't want to make separate entries in the alternate name tables for each feature as it is killing performance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Stephanie,
Sorry, I have been super busy.
What issue are you having when using multiple alternate city names?
Each alternate city name for a specific city (ex North Redlands, South Redlands) should have the same JoinID (ex 12345) in the alternate city names table. If you primary reference data (the one with geometry) already has a city name (ex Redlands), this will be the primary city name. All streets in the data that are in Redlands should have a city JoinID (ex. 12345). This allows you to link in multiple alternate city names for Redlands.
If you use a fully normalized dataset where city isn't in the primary reference data, then the primary city name can be in the alternate city name table but with an extra field that indicates which city is the primary (determined by the "Primary Name Indicator" field in the alternate name table field mapping).
Hope this helps but let me know if you have any additional questions or issues.
Brad
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »