- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Spatial Analyst
- :
- ArcGIS Spatial Analyst Questions
- :
- How to interpret the results of the Corridor tool
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to interpret the results of the Corridor tool
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello everyone,
sorry, I feel like I'm flooding this forum with questions lately, but I am always getting such excellent help, which is great!
My question now concerns the output of the Corridor tool (see picture below). It is created using two inputs of the Cost Distance tool for two different sources - in this case habitat for giant pandas North of Highway 303 and habitat South of the highway. Now I was wondering:
1.) Why do I get so many NoData cells? Is that because the cost there to connect the two sources would be too great? (but too great compared to what? The maximum dispersal limit that I specified when using Cost Distance?) --> I am actually quite happy that there is so much NoData, because IF it really means travel for pandas is too "costly" there, then I have the area for possible corridor establishment narrowed down pretty neatly. I just want to make sure I am not drawing incorrect conclusions.
2.) The higher the value of a cell the higher the cost for a panda to travel through this cell from one habitat to the next. Is that correct?
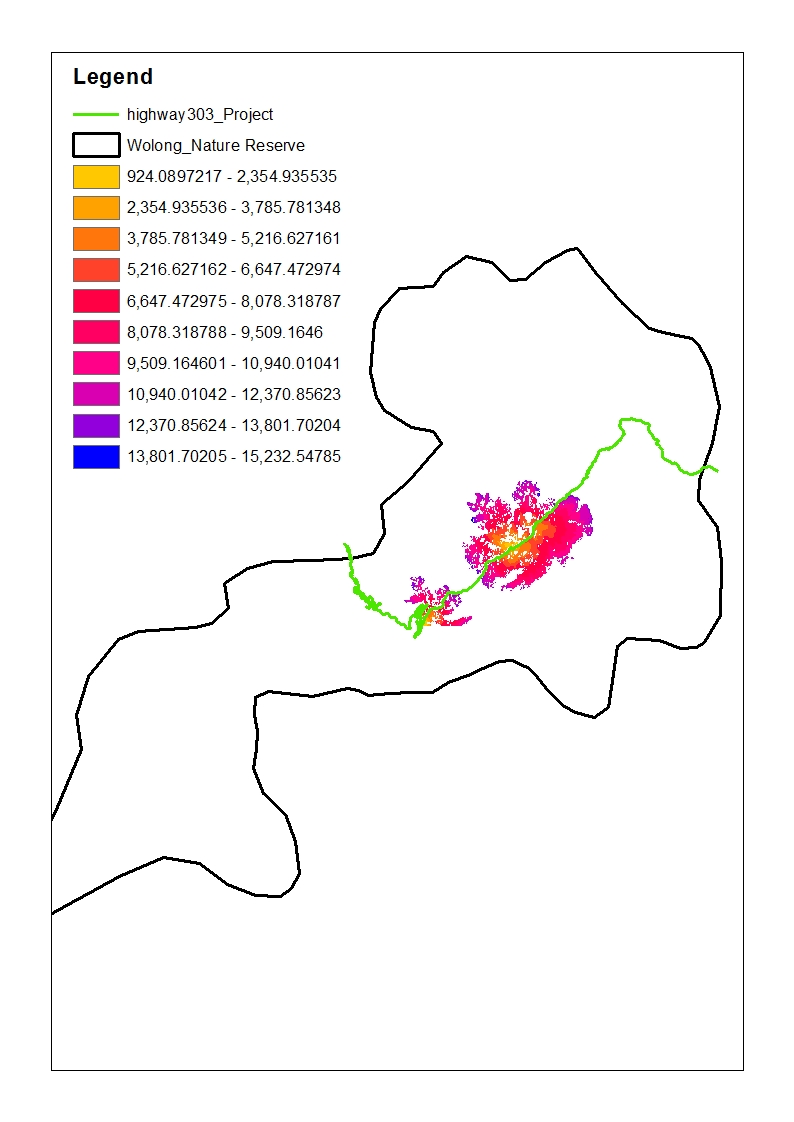
Many thanks in advance!
Carina
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Let's tackle the second question first.
2.) The higher the value of a cell the higher the cost for a panda to travel through this cell from one habitat to the next. Is that correct?
A cost distance raster is a raster where each cell contain the accumulated cost to get there from the origen using the most optimized route (lowest cost). So yes, the higher the value the more difficult it is for a panda to reach that cell.
1.) Why do I get so many NoData cells? Is that because the cost there to connect the two sources would be too great? (but too great compared to what? The maximum dispersal limit that I specified when using Cost Distance?) --> I am actually quite happy that there is so much NoData, because IF it really means travel for pandas is too "costly" there, then I have the area for possible corridor establishment narrowed down pretty neatly. I just want to make sure I am not drawing incorrect conclusions.
If you have two origins and generated a cost distance from each point separately, you should process each separately and apply a threshold to define what the potential habitat from that origin is. Once you have the areas you can combine them. I notice that according to the analysis pandas from the southern habitat can reach the northern part of the highway and vice versa. Is that true? In case it is not, the highway should be configured and a part that cannot be crossed and the habitat should be restricted to the same side of the highway. The end will be two habitats, one for each group of pandas.
In case pandas can pass from one side to the other, then the individual results are correct. I don't think it makes sense, based on what I'm understanding, to determine the maximum of the two rasters. You should look at the minimum value, since this represents the cost of the panda that can reach that part with the least "cost".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Carina, it might help to show some of the smaller focused intermediate maps prior to the final corridor result to facilitate discussion. I presume you have seen this Creating a least cost corridor—Help | ArcGIS for Desktop and are familiar with it. PS, many of your threads remain open, you might want to address those and close them with either the accepted answer if there is one or convert it to a discussion, or assumed answered. In that way, people will know that there is some closure on the topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dan Patterson, sorry. Yes, I have seen this link. So, here are the two Cost Distance layers for my corridor. The first one is for the Northern habitat and the second one for the Southern habitat:
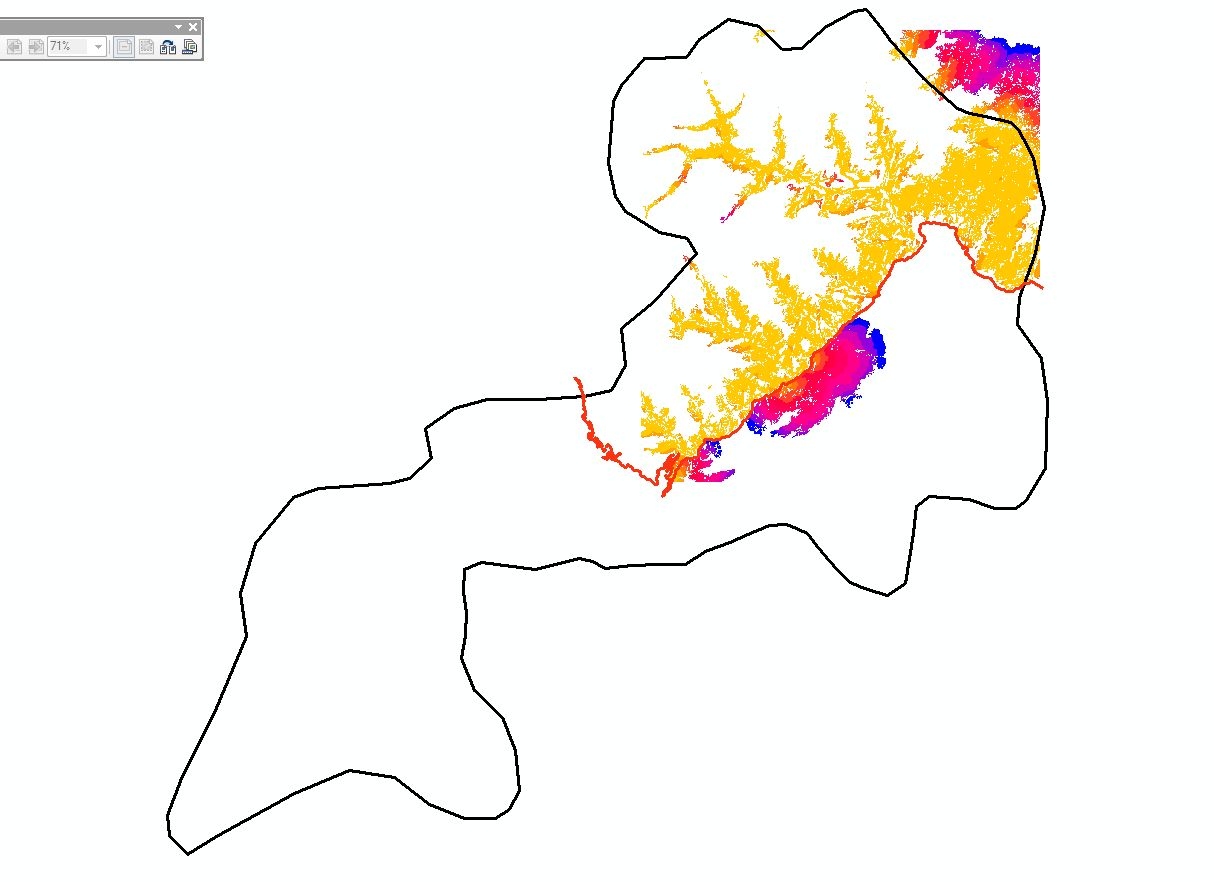
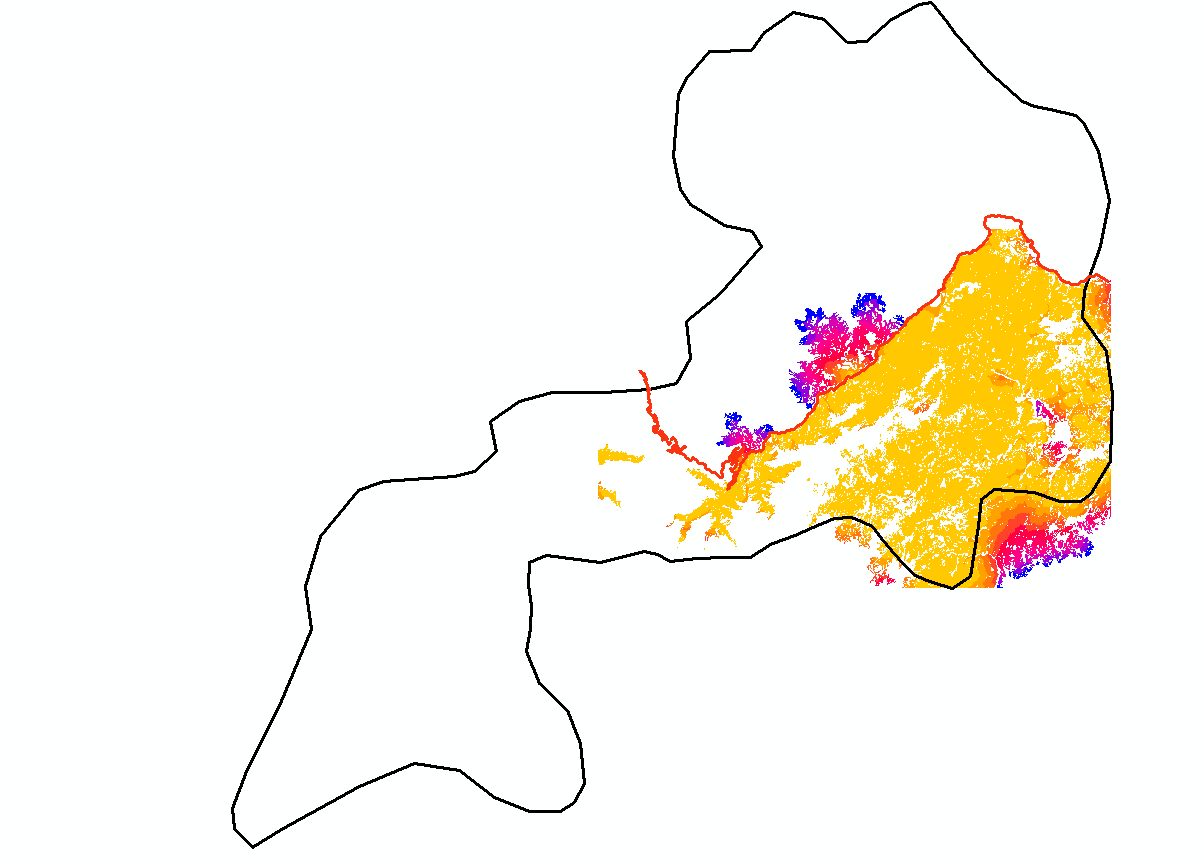
And this is from the table of contents:
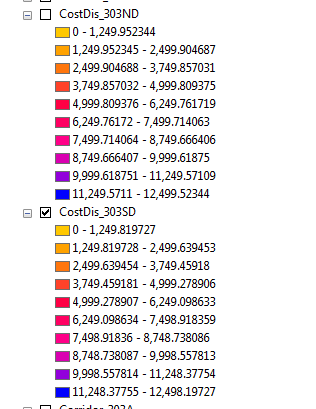
Does that help?
Cheers,
Carina
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jayanta Poddar maybe you can help? 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Carina:
1. The output corridor only has data where both accumulative cost surface inputs have data. You may still need to apply a threshold to that output if you're interested in a more refined estimate of the corridor.
2. Its tough for me to tell from the images, but you need to be careful to prevent 'leaky barriers' when using rasterized linear features as elements in your input cost surface. If such a linear feature gets rasterized into cells that are strictly corner connected, then the cost distance 'spreading function' will move through the other diagonal and effectively ignore the barrier. In the image below the grey cells represent the raster version of the barrier (or high cost area). That barrier is ignored because it is only corner connected. Accumulated cost can propagate diagonally across it.

One way to avoid this is to create an intermediate raster from your linear cost inputs and apply the focal statistics tool to 'thicken' the barrier. Focal statistics will spread whatever cell value you want from the rasterized linear feature to the adjacent cells. You then incorporate the thickened, rasterized, linear feature, into your final input cost surface.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you combine two rasters that have NoData values a Con statement, you will probably end up with many NoData cells (if one of the rasters has NoData, then the result will be NoData). To avoid this you could use the Cell Statistics—Help | ArcGIS for Desktop tool, using the Max as statistics function and the ignore no data option set to DATA (to ignore NoData values).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi thanks for the reply! I don't really mind the No Data actually as long as my assumptions from the first post above are correct. Do you happen to have any idea if that is the case?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Let's tackle the second question first.
2.) The higher the value of a cell the higher the cost for a panda to travel through this cell from one habitat to the next. Is that correct?
A cost distance raster is a raster where each cell contain the accumulated cost to get there from the origen using the most optimized route (lowest cost). So yes, the higher the value the more difficult it is for a panda to reach that cell.
1.) Why do I get so many NoData cells? Is that because the cost there to connect the two sources would be too great? (but too great compared to what? The maximum dispersal limit that I specified when using Cost Distance?) --> I am actually quite happy that there is so much NoData, because IF it really means travel for pandas is too "costly" there, then I have the area for possible corridor establishment narrowed down pretty neatly. I just want to make sure I am not drawing incorrect conclusions.
If you have two origins and generated a cost distance from each point separately, you should process each separately and apply a threshold to define what the potential habitat from that origin is. Once you have the areas you can combine them. I notice that according to the analysis pandas from the southern habitat can reach the northern part of the highway and vice versa. Is that true? In case it is not, the highway should be configured and a part that cannot be crossed and the habitat should be restricted to the same side of the highway. The end will be two habitats, one for each group of pandas.
In case pandas can pass from one side to the other, then the individual results are correct. I don't think it makes sense, based on what I'm understanding, to determine the maximum of the two rasters. You should look at the minimum value, since this represents the cost of the panda that can reach that part with the least "cost".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks so much again for the detailed reply. I guess in theory pandas could cross a highway and my conclusion from the Corridor tool would be that they can do so at the area that is coloured in the uppermost picture, right?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What I notice is that, according to your data, pandas can cross the highway but only at certain points:
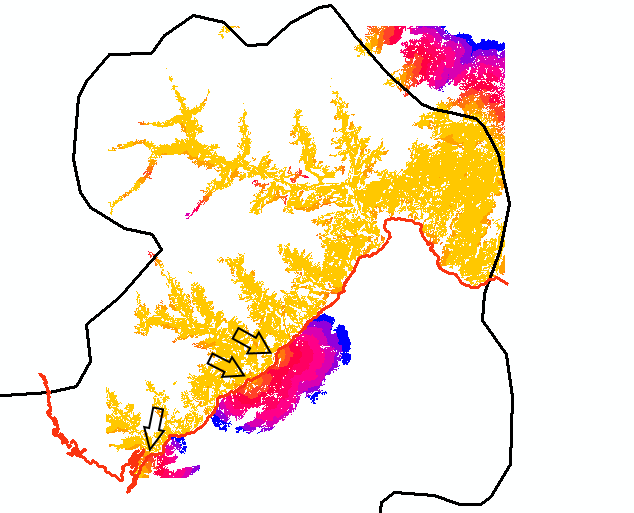
If this is true, than that's OK. If they can cross the highway at any given point, but crossing the highway is difficult for them, then the weight assigned to the highway should reflect that (should be high).