- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Blog
- :
- Split ... Sort .... Slice ... the Top X in Y
Split ... Sort .... Slice ... the Top X in Y
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
Task...
Identify the 2 highest elevation points in a series of polygons.
Purpose...
To win a bet amongst neighbors... to locate something like a tower... find observation points for visibility analysis... lots of reasons
Conceptualization...
- Intersect the points with the polygons, retaining all attributes... output type... point
- Add an X and Y field to the result so you have the point coordinates for later use (if you don't have them)
- Delete any 'fluff' fields that you don't need, but keep the ID, KEY, OBJECTID fields from each. They will have a unique name for identification.
- Split the result into groupings using the key fields associated with the polygons (see code)
- Sort the groupings on a numeric field, like elevation (ascending/descending) (code)
- Slice the number that you need from each grouping. (code)
- Send it back out to a featureclass if you need it. (code)
For Picture People...
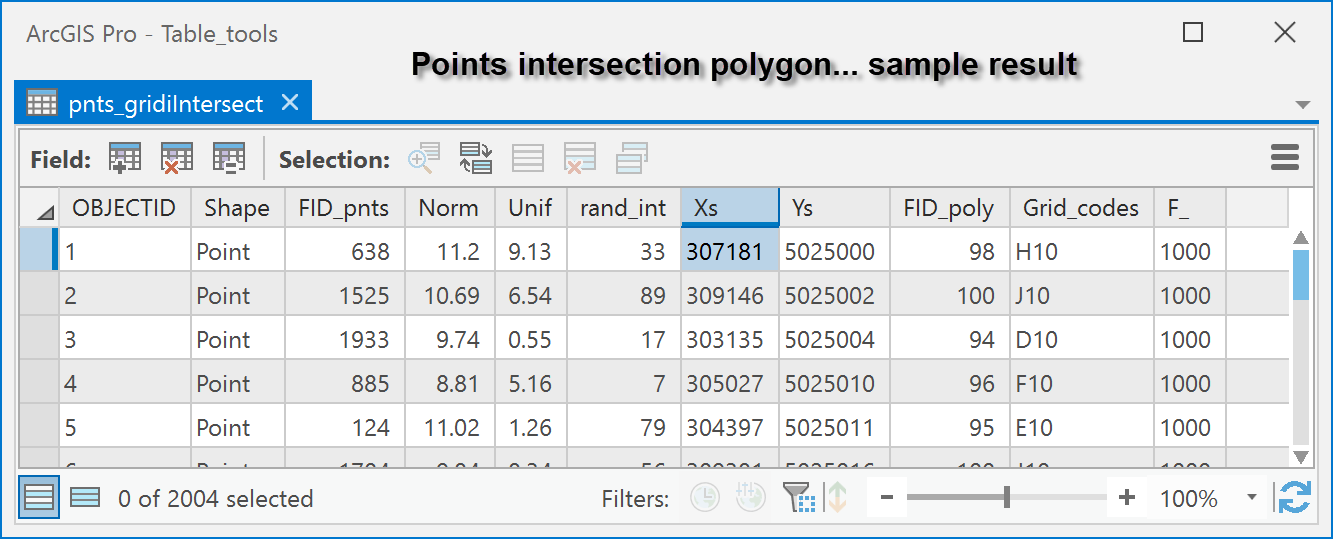
A sample table resulting from the intersection of points with polygons.
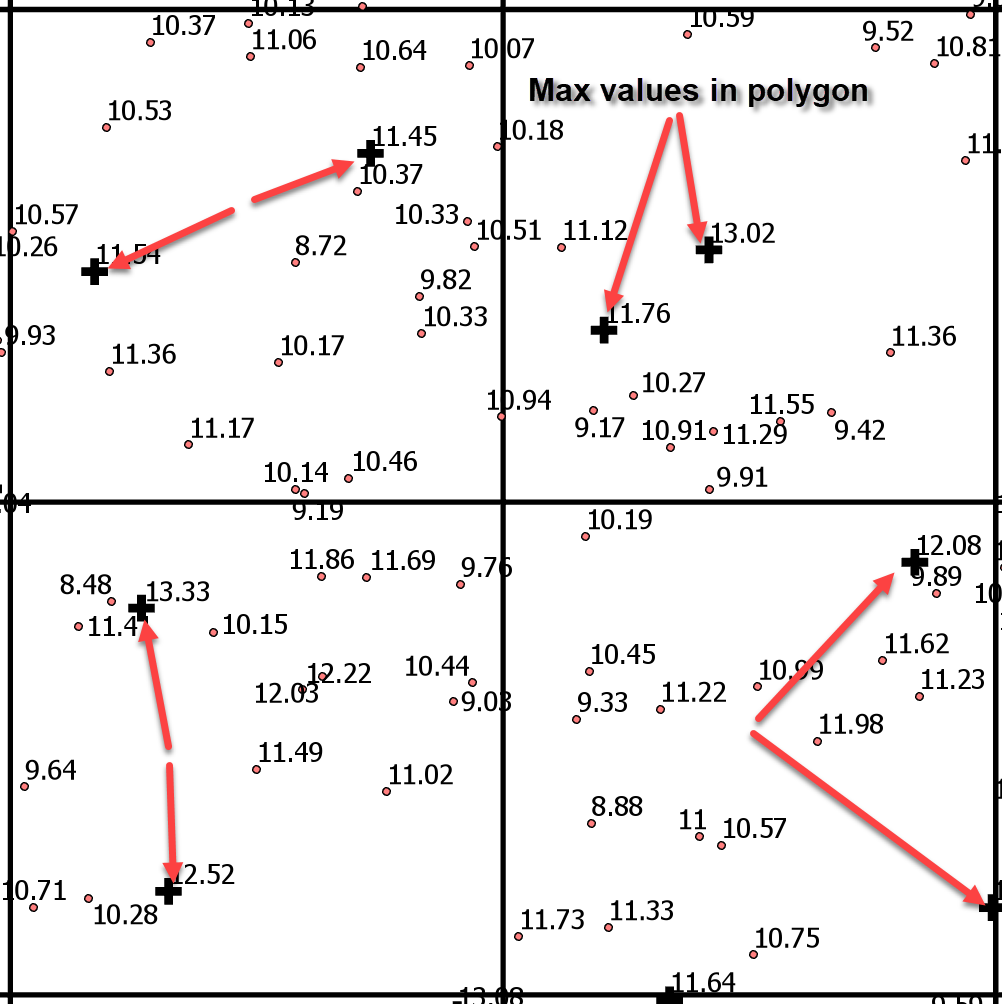
The points (in red) and the polygons (a grid pattern) with the two points with the highest 'Norm' value in each polygon

An upclose look of the result
For the Pythonistas....
Fire up Spyder or your favorite python IDE
>>> a = arcpy.da.TableToNumPy("path to the featureclass or table", field_names="*") # you now have an array
with me so far? now you have an array
Make a script... call it something (splitter.py for example)
The work code...
import numpy as np
import arcpy
def split_sort_slice(a, split_fld=None, val_fld=None, ascend=True, num=1):
"""Does stuff [email protected] 2019-01-28
"""
def _split_(a, fld):
"""split unsorted array"""
out = []
uni, idx = np.unique(a[fld], True)
for _, j in enumerate(uni):
key = (a[fld] == j)
out.append(a[key])
return out
#
err_0 = "The split_field {} isn't present in the array"
if split_fld not in a.dtype.names:
print(err_0.format(split_fld))
return a
subs = _split_(a, split_fld)
ordered = []
for i, sub in enumerate(subs):
r = sub[np.argsort(sub, order=val_fld)]
if not ascend:
r = r[::-1]
num = min(num, r.size)
ordered.extend(r[:num])
out = np.asarray(ordered)
return out
# ---- Do this ----
in_fc = r"C:\path_to_your\Geodatabase.gdb\intersect_featureclass_name"
a = arcpy.da.TableToNumPyArray(in_fc, "*")
out = split_sort_slice(fn, split_fld='Grid_codes', val_fld='Norm', ascend=False, num=2)
out_fc = r"C:\path_to_your\Geodatabase.gdb\output_featureclass_name"
arcpy.da.NumPyArrayToFeatureClass(out, out_fc, ['Xs', 'Ys'], '2951')Lines 40 - 42
NumPyArrayToFeatureClass—Data Access module | ArcGIS Desktop
Open ArcGIS Pro, refresh your database and add the result to your map.
I will put this or a variant into...
So that you can click away, for those that don't like to type.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.