- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- FGDB Compress Performance Impacts with LIKE query
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
FGDB Compress Performance Impacts with LIKE query
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
This thread is quite long with some gory details (below) so here is the bottom line...
A File Geodatabase (FGDB) that has been compressed has showed to perform better on almost all operations tested, except a query with the LIKE operator (using _).
The underlying field where the LIKE operator is applied to is indexed.
Does anyone have ideas how to increase query performance on a compressed geodatabase when using a LIKE operator?
--- GORY DETAILS ---
The dataset we are working with is ~27GB when stored uncompressed in a FGDB. The dataset is highly used (300-400K hits a day with 4-5K unique clients) so adequate performance is critical. Furthermore, this is a central dataset to our organization operations. This FGDB is hosted on a file system and published through arcgis server as a mapping/feature service. There is a 1K limit on query operations. Display performance is generally sub-second as we have scale dependencies applied for appropriate levels. May of the clients need raw data access to the underlying features (think map identify, table display, query, etc) and generally not problematic.
We have experienced clients that seem to 'scrape' data off the service by making ArcGIS Server query API calls like:
The example encoded 'where' clause is OBJECTID >277000 AND OBJECTID <=278000
What we observe is that some clients are making requests like this 1K record chunks at a time. Some of the clients are throwing upwards of 16 concurrent requests at the server and the server takes over 80 seconds to handle EACH request with the uncompressed database. This set of requests cause high CPU on the back-end arcgis server environments and if left unchecked, cause system unresponsiveness on this and many other services co-located here (the environment gets 5-6M hits a day with 60K+ unique clients). The back-end hardware is generally enough to handle daily operations (4 servers, each with 8 CPU, 32GB RAM), but when this scraping action occurs we experience instability. We have had to selectivly deny public IP addresses that exhibit this behavior. Often times they will come back, but scale back the concurrent requests (to like 😎 which the systems are able to handle, albeit a bit slow. Some of these are public anonymous users. Sadly, we do have the data available for download but cannot seem to prevent public users from scraping the data as a service.
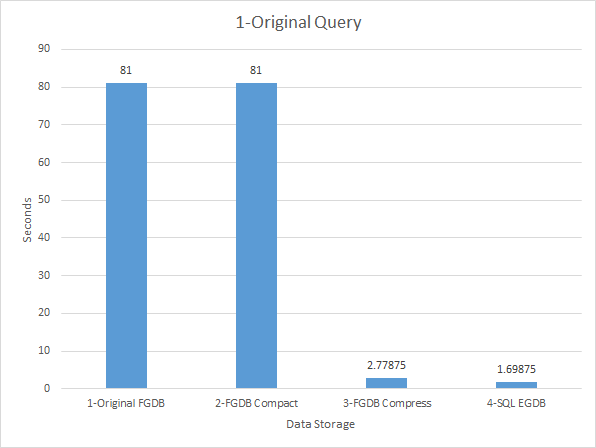
When we compress the FGDB (reduces to 3.5GB), the same request only takes 2.78 Seconds and a SQL Enterprise GDB takes even less at 1.7 seconds:
Naturally the SQL Server Enterprise Geodatabase (EGDB) hosting appears to be the best case to resolve this performance issue, however we have completed some extensive testing and the FGDB hosting beats out the EGDB hosting on many other operations:
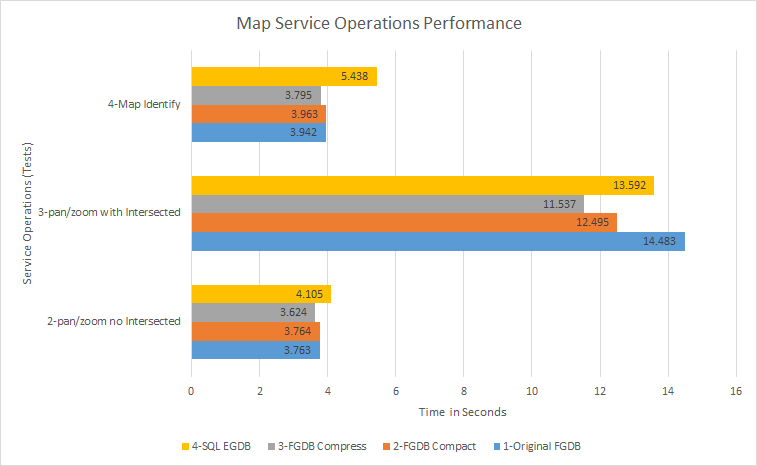
The tests noted above were doing simple operations within a web-map (and using fiddler to reissue the requests sequentially a few times to obtain the response times). As you can see, the SQL EGDB performs worse than the compressed FGDB (the FGDB is 13-43% faster depending on the operation). We have completed similar tests on other datasets and generally publish from a FGDB due to the performance gains. This back-end EGDB was fully compressed (state of 0) with no versioning. And the dataset is heavily indexed on both FGDB and EGDB.
So far, everything points to using a compressed FGDB for performance gains, however a query using the LIKE operation takes so long it times out:
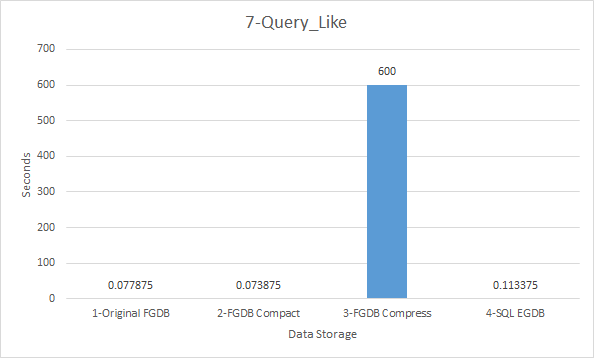
So... somewhat at a loss on best choice here.
In full disclosure, we do not notice query LIKE operations on the rest endpoint, but rather we have a custom written Server Object Extension (SOE) that is using the LIKE operator extensively. This SOE was developed a few years back and we really dont want to dive in to try and re-write some of the query operations. Even if we did, this would not prevent a rogue user issuing a query LIKE operation through the REST API /query operation.
I see a few options available (in order of best options IMO):
1) Post here and someone from the community can suggest something we have not throught about yet (please please please!) 
2) Move this to a SQL Server EGDB back-end. Overall performance may be slower, but could be the best of all operations combined
3) Host a compressed and uncompressed FGDB with 2 different services. The uncompressed would have the SOE (that generally responds in sub-second time). Essentially isolating the SOE operations to an uncompressed GDB, and using the compressed FGDB for standard mapping/feature access.
4) refactor the SOE to remove any LIKE queries. Establish alternative queries that could perform better.
Thoughts from the community? Thanks for any feedback you can provide.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I don't have time to dive into a full response, but I will say that pagination support was added to the ArcGIS REST API back in 10.3.x to address the scraping issue. Part of the problem is a client that executes dozens of simultaneous requests for offset Object IDs, which is a very greedy way of retrieving records from the service. Pagination is less greedy and more efficient for the back-end datastore, and hence the service itself. Most of Esri's platforms that call the REST API have been updated to utilize pagination when available, but that doesn't stop an outdated or simply lazy developer from ignoring pagination and hammering the datastore.
In terms of the performance you are seeing with LIKE, the first thing that comes to mind is your LIKE statement isn't fully utilizing an index. The structure of a LIKE statement can greatly impact how an index is used. If an index isn't being used, or used very much, a compressed file geodatabase would require the data to be uncompressed before comparing the data with the search criteria. The process of uncompressing the data could add significant time to queries.