- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Help with time series data by block groups automat...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Help with time series data by block groups automation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have data in a table that represents values over 3 different categories (Average Day, Weekday, Weekend) and 5 different time periods (All Day, Morning, Mid-Day, Afternoon, and Evening). The data is by block group and there is a one to many relationship (i.e. duplicate block group IDs in the table), so a simple join to my block group feature class is not the answer.
I created the model below to help me visualize the data in separate map layers. The model iterates through the unique combination of categories and times (e.g. "0: Average Day (M-Su), 0: All Day (12am-12am)", "0: Average Day (M-Su), 1: Morning (6am-10am)", etc.) and creates a table with unique block groups by day type and time that I can join to the main block group feature class and export each iteration into a new feature class. The %n% variable names the output feature class with a unique number. Normally, I would use %Value%, but the field data (shown above) is rather long and contains spaces, dashes, and parentheses that we would not want that in the feature class name. The model below works perfectly the first time that I run it, but when I give it a new input table (I have lots of tables to process), the iteration no longer gives me all of the output data. It looks like it is overwriting the data for each iteration and just giving me a single output feature class. Any ideas on how to fix this? It seems like it should be pretty simple and I have no idea why the iteration doesn't continue to work with the new input data.
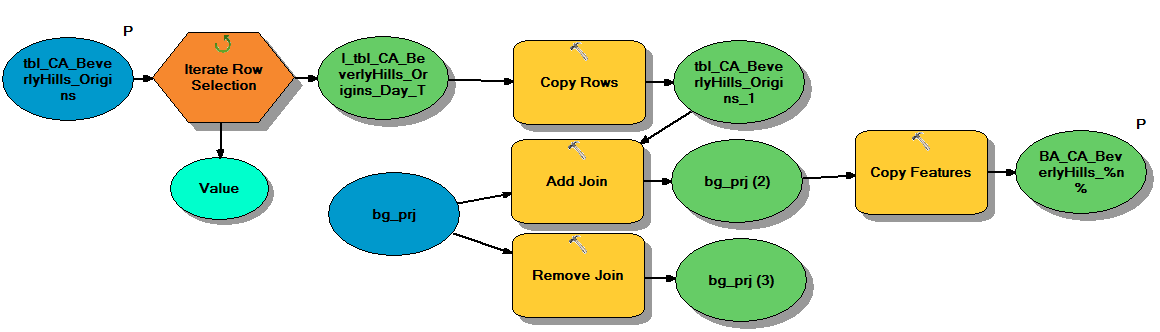
I also tried to convert this to Python code and I'm getting stuck on how to create a unique number for each string in the unique set of field values. (FYI - I am not a developer/programmer so my Python skills are minimal.)
# Import arcpy module
import arcpy
from arcpy import env
import os
# Load required toolboxes
arcpy.ImportToolbox("C:\\Program Files (x86)\\ArcGIS\Desktop10.3\\ArcToolbox\\Toolboxes\\Data Management Tools.tbx")
# Set up workspace environment
arcpy.env.workspace = "c:\\test\\TimeDatabyBG.gdb"
arcpy.env.overwriteOutput = True
# Script arguments
InTable = arcpy.GetParameterAsText(0)
InName = arcpy.GetParameterAsText(1)
Field = arcpy.GetParameterAsText(2)
OutTable = arcpy.GetParameterAsText(3)
OutWorkspace = arcpy.GetParameterAsText(4)
Blockgroups = arcpy.GetParameterAsText(5)
OutFC = arcpy.GetParameterAsText(6)
# InTable example = "c:\\test\\TimeDatabyBG.gdb\\tbl_CA_RanchoSanta_Origins"
# InName example = "CA_RanchoSanta"
# Field example = "Day_Type_Part"
# OutTable example = os.path.join(OutWorkspace, "InName")
# OutWorkspace example = "c:\\test\\TimeDatabyBG.gdb\\"
# Blockgroups example = "c:\\test\\TimeDatabyBG.gdb\\"bg_prj"
# OutFC example = os.path.join(OutWorkspace, "BG_" + InName + iterated number
# or "c:\\test\\TimeDatabyBG.gdb\\"BG_CA_RanchoSanta_1"
# Iteration
cursor = arcpy.da.SearchCursor(InTable, Field)
values = [row[0] for row in arcpy.da.SearchCursor(InTable, Field)]
uniqueValues = set(values)
print(uniqueValues)
#the script works up to this point in that it can print out a list of the unique values in the "Day_Type_Part" field, but I don't know how to translate this into a unique selection and value for the name of the output table in the line below.
# Process: Copy Rows
arcpy.CopyRows_management(InTable, OutTable)
# Process: Add Join
arcpy.AddJoin_management(Blockgroups, "ID", OutTable, "BG_ID", "KEEP_COMMON")
# Process: Copy Features
arcpy.CopyFeatures_management(Blockgroups, OutFC, "", "0", "0", "0")
# Process: Remove Join
arcpy.RemoveJoin_management(Blockgroups, "")
Any help will be greatly appreciated!
Thanks,
-Susan-
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello Susan,
I am glad that you were able to find a workaround.
I tested your model and it works fine. The only problem is that the iterate row selection is failing to select the rows, since the field data has some characters such as :,-(, numbers, etc.
If you use for instance the field 'Minutes' as input, the model will run as expected, which shows that the issue is caused by the special characters.
I also copied several rows and eliminated characters such as (,:-numbers, and I was able to run the model successfully.
Regards,
Ciro
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In your iteration section change the values for something similar to below. You'll want to fill in the where clause with the proper field and field delimiters.
Make Table View—Help | ArcGIS for Desktop
num = 0
for row in arcpy.da.SearchCursor(InTable, Field):
value = row[0]
num = num + 1
arcpy.MakeTableView_management (in_table, out_view, {where_clause})
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks, Wes, but the code you provided is not quite what I'm trying to achieve (or perhaps I'm just not understanding it correctly). There is no "where" clause in this case since I don't want to manually specify the value that I'm looking for in the table. I want the code to select the first in the set (e.g. "0: Average Day (M-Su), 0: All Day (12am-12am)") and associate that with the number 1 and then when it creates the table in the arcpy.CopyRows_management(InTable, OutTable), I want the OutTable to be automatically named something like "tbl_1". At the end of the iteration, there should be many tables---tbl_1, tbl_2, tbl_3, etc. I can then use these tables to join to the block group feature class and export these as new feature classes where I can set the symbology for each new map layer. Does that make sense?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Are all the tables in the same workspace and do they all use the same field name.
You should be able to take your working model and put it in another model. Then use:
http://desktop.arcgis.com/en/arcmap/10.3/tools/modelbuilder-toolbox/iterate-tables.htm
Examples of using iterators in ModelBuilder—Help | ArcGIS for Desktop
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
All of the tables are in the same workspace and have the exactly the same fields. I've read all of the online help related to iterators and I've used them successfully in many other situations. The model that I created works perfectly when I run with the table that I use when creating the model. Of course, I can simply duplicate the first model in a new model to get it to run with the next table, but that defeats the purpose of automation. The model should work the same way when I enter a new input table since this is a parameter in the model, but unfortunately, it does not. It doesn't give me any error messages when I run the model a second time with the new input table and output feature class parameters. It does create an output feature class, but only one, when it should be creating 15. I tried using %n% and %i% as a way to get the iteration to have unique names when I run the model again, and neither results in the correct output, so I think this may be a limitation in the way that ModelBuilder works, which is why I tried to get this to work in Python.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Could you provide your model and some sample data. A demonstration may explain things better.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here's the result when I run the model first on the table named tbl_CA_AppleValley_Origins and then run it again with tbl_CA_RanchoSanta_Origins.
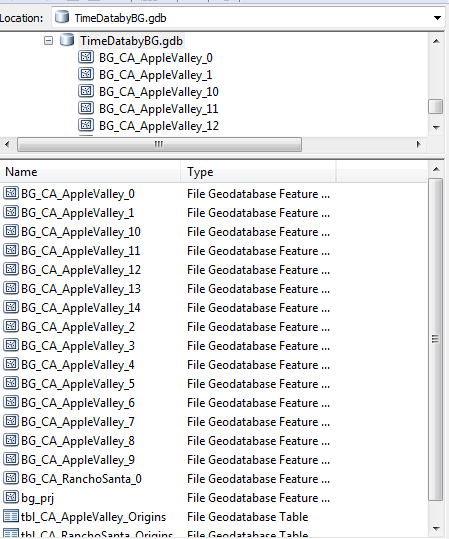
And here's what happens when I delete all of the output data and run the same model again:
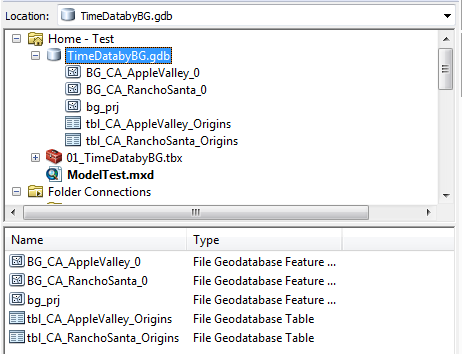
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I attached a zip file that contains the file geodatabase with some sample data, the toolbox with the model, and an MXD with the bg_prj map layer loaded. (The reason for this is that I've found that if I load the bg_prj into the model from the data source, the join will fail, but if I load the bg_prj from a layer in the Table of Contents, then the join works as expected.)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
While I would still like to know how to get my original model to work (or how to get this to work in python), I have found an alternative solution that works very well. See Canton Hall's post on LinkedIn: ArcMap 10.2 - One to Many Join | Canton Hall | LinkedIn
Note: Canton's solution works well with 10.3.1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello Susan,
I am glad that you were able to find a workaround.
I tested your model and it works fine. The only problem is that the iterate row selection is failing to select the rows, since the field data has some characters such as :,-(, numbers, etc.
If you use for instance the field 'Minutes' as input, the model will run as expected, which shows that the issue is caused by the special characters.
I also copied several rows and eliminated characters such as (,:-numbers, and I was able to run the model successfully.
Regards,
Ciro