- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Updating the rows in one table based on values in ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Updating the rows in one table based on values in another table or using nested cursors
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am finding it hard to articulate what I am trying to do, so here's what I have and here's where I'm going.
I have: 4 raster datasets. One is a set of drainage zones, one is the soil type, one is slope, and one is depth below surface. I also have a large table of stormwater practices and their associated physical constraints.
Desired outcome: For each drainage zone, I want a list of stormwater practices that can go on the site.
What I've done: For each drainage zone, I have found the median slope and median depth below surface using Zonal Statistics. I have combined the median slope, median depth, drainage zone, and soil type into a single raster dataset using the Combine function. I have used the Build Raster Attribute Table to have all of those values available to me in a single table without converting it back to a shapefile. I have a Cursor set up to duplicate the constraint table for each unique combination of drainage zone and soil type.
What I want to do: I want to compare the Combination table to the table of constraints and delete rows from the constraint table when certain conditions are met. For example, some stormwater practices only work on soil types A and B, so if the soil type in the constraint table is not found in the row for the combination table, I want the row in the constraint table to be deleted. Here is the code I have come up with to help you understand my goal.
# Combine rasters to give unique combinations combo = arcpy.sa.Combine([DAras, EffHSG, med_WT, med_slope]) combo.save(WorkPath + r"\combo") combo_table = arcpy.BuildRasterAttributeTable_management(combo) # Convert integer HSG code to string type arcpy.AddField_management(combo_table, "HSG", "TEXT", "", "", 6) with arcpy.da.UpdateCursor(combo_table, ["EFFECTIVEHSG", "HSG"]) as cursor: for row in cursor: if row[0] == 1: row[1] = "A" if row[0] == 2: row[1] = "B" if row[0] == 3: row[1] = "C" if row[0] == 4: row[1] = "D" cursor.updateRow(row) ### _____________COMPARE CRITERIA_____________________ ### print("Creating BMP output folder...") # Define location of constraint database and establish new output location CRIT = TabPath + "constraints.xlsx" BMPFold = ProjFolder + r"\BMP__Tables" if not os.path.exists(BMPFold): os.makedirs(BMPFold) print("Loading constraint database...") # Convert Excel constraint file to GIS table compare = arcpy.ExcelToTable_conversion(CRIT, ProjFolder + r"\constraints") fields = ["SOIL", "MAX_SLOPE", "MIN_CDA", "MAX_CDA", "WT_SEP", "WT_RELAX", "COAST_SEP", "MIN_DEPTH", "DEPTH_RELA", "COAST_MIN_"] # Create output table for each drainage area for row in arcpy.da.SearchCursor(combo_table, ["DARAS", "HSG", "MEDSLOPE", "MEDWT"]): arcpy.Copy_management(compare, BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1])) DAmask = arcpy.sa.SetNull(DAras, DAras, "VALUE <> " + str(row[0])) arcpy.env.mask = DAmask arcpy.env.snapRaster = DAmask arcpy.AddField_management(BMPFold + "\\" + "DA" + str(row[0]), "MOD", "TEXT", "", "", 14) for r in arcpy.da.UpdateCursor(BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1]), fields): if row[1] not in r[0]: del(row)
The problem: I get an error saying that "NameError: name 'row' is not defined" for line 41, "if row[1] not in r[0]:". Once the code enters the nested cursor, "row" gets wiped out and is no longer a valid parameter. What is a workaround for this?
EDIT: The python syntax converter works very poorly on my computer for some reason. Sorry. I tried to update it so the indentations are in the right place. If they do not appear in the correct spot, I promise they are correct in my actual code and that is not the problem.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The problem is that you cannot use del(row). You have to use cursor.deleteRow(row).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
this may just be an error when copying your Python to your question, but check (and modify in original post) your indentation, especially starting in row 5-13 and 36-37.
i'm not at a location that I can test the code,but that will be the first thing to check.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, thank you, I actually started correcting that before you even posted! It loses the indents when I copy it over and I always forget. I am trying to correct it but the last few indents don't want to stick for some reason.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
row is use in many part of your code. Which specific line is throwing the error?
Also, do not use nested cursors. They are horribly inefficient and in my opinion should never be used. Instead first use a cursor to load the entire source you want to match into a dictionary and then run an updatecursor on the data that needs to match it using the dictionary to compare the values. See my blog on the subject here for some ideas of how this can be set up.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The last part, the nested cursor, is throwing the error. I always use "row" in my code for cursors (except in this nested cursor case). Is that a bad thing?
for r in arcpy.da.UpdateCursor(BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1]), fields): if row[1] not in r[0]: del(row)
I thought it might be inefficient but I didn't have a better way to do it. I'll check out your blog post and see what I can do with a dictionary instead. Thank you. I will probably have some questions later on since I've never used a dictionary before.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Using row or r is fine. I think the problem is that the comparison continues after the row has been deleted. Once deleted, row would be undefined for the comparison to the next r[0] value. You would need to break out of the for loop once the del(row) operation takes place.
That also raises the question about the comparison logic. If you do not query the table for any specific records, than I would expect many records to not match your row values, and the row would virtually always be deleted. A dictionary would help with this, since doing a if not row[0] in dict: compares to all the of dictionary keys you previously loaded from the entire table at once, not to just one row at a time in the comparison table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I added "break" to my code and now it loops through all the expected combinations of drainage zone and soil type and copies the constraint table for each! But, I found that it didn't delete the rows in the table.
row[1] = "HSG" from combo_table
r[0] = "SOIL" from table DA1HSGD
# Create output table for each drainage area for row in arcpy.da.SearchCursor(combo_table, ["DARAS", "HSG", "MEDSLOPE", "MEDWT"]): print("Saving constraint table for DA " + str(row[0]) + " and HSG " + str(row[1]) + "...") arcpy.Copy_management(compare, BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1])) # DAmask = arcpy.sa.SetNull(DAras, DAras, "VALUE <> " + str(row[0])) # arcpy.env.mask = DAmask # arcpy.env.snapRaster = DAmask arcpy.AddField_management(BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1]), "MOD", "TEXT", "", "", 14) # Check constraints against the site values and remove infeasible stormwater practices for r in arcpy.da.UpdateCursor(BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1]), fields): print("Removing incompatible soil types...") if row[1] not in r[0]: del(row) break
It saves the tables as all lowercase and I am calling an uppercase version. Could that be the problem? How do I convert row[1] into lowercase for the purpose of calling the correct table?
Here are my tables in case it helps to see them:
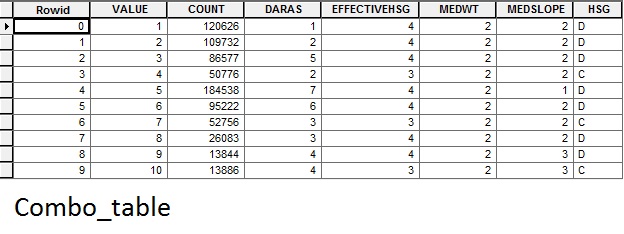
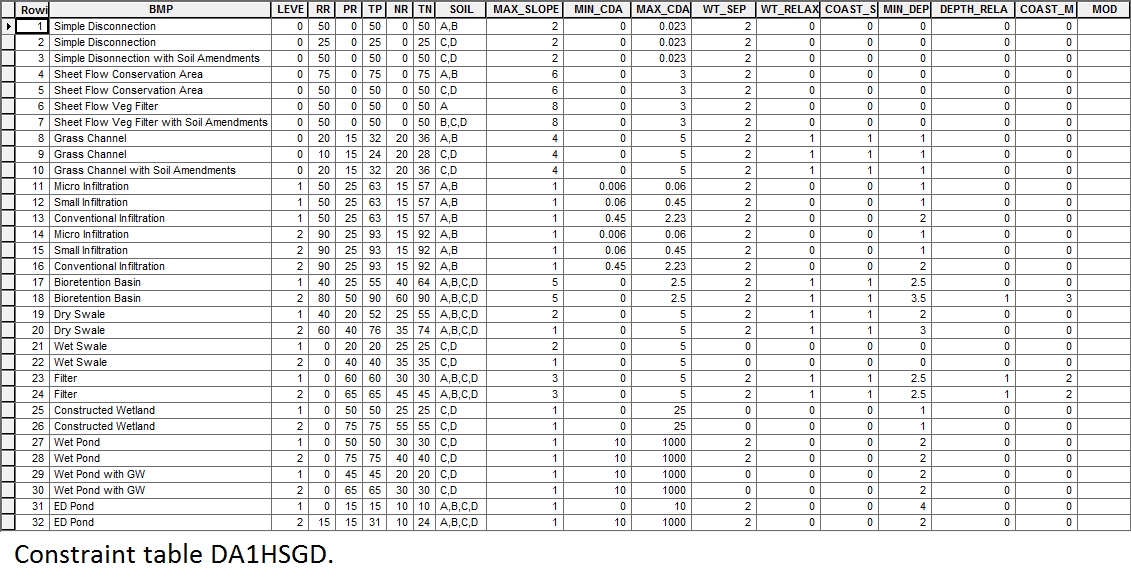
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The problem is that you cannot use del(row). You have to use cursor.deleteRow(row).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ah! I see. I got it to work with this code. Thank you!
# Create output table for each drainage area for row in arcpy.da.SearchCursor(combo_table, ["DARAS", "HSG", "MEDSLOPE", "MEDWT"]): print("Saving constraint table for DA " + str(row[0]) + " and HSG " + str(row[1]) + "...") arcpy.Copy_management(compare, BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1])) # DAmask = arcpy.sa.SetNull(DAras, DAras, "VALUE <> " + str(row[0])) # arcpy.env.mask = DAmask # arcpy.env.snapRaster = DAmask arcpy.AddField_management(BMPFold + "\\" + "DA" + str(row[0]) + "HSG" + str(row[1]), "MOD", "TEXT", "", "", 14) # Check constraints against the site values and remove infeasible stormwater practices with arcpy.da.UpdateCursor(BMPFold + "\\" + "da" + str(row[0]) + "hsg" + str(row[1]), fields) as cursor: for r in cursor: print("Checking for incompatible soil types...") if row[1] not in r[0]: print("Removing " + str(r[10]) + " based on soil type...") cursor.deleteRow()
So, I just now noticed the second part of your reply:
"That also raises the question about the comparison logic. If you do not query the table for any specific records, than I would expect many records to not match your row values, and the row would virtually always be deleted. A dictionary would help with this, since doing a if not row[0] in dict: compares to all the of dictionary keys you previously loaded from the entire table at once, not to just one row at a time in the comparison table."
Before I move on to trying to construct a dictionary, I want to be sure it's going to do what I want it to do. It sounds like you're saying that constructing a dictionary will compare all the rows in the constraint table to the combo_table dictionary all at once and remove rows from the constraint table in a group rather than row-by-row. Right? For each row in my Combo_Table, I have a separate constraint file that I want to be edited. Each constraint table should be checked against the values in just one row of the combo table, not all of them at once.