Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Cancel
- Home
- :
- All Communities
- :
- Products
- :
- Spatial Statistics
- :
- Spatial Statistics Questions
- :
- Count common unique attribute values of points in ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Count common unique attribute values of points in >1 polygon
Subscribe
4225
0
10-14-2014 09:17 PM
10-14-2014
09:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- I have a point Feature Class and a polygon Feature Class. For the purpose of this discussion let's assume THOUSANDS of points and TWO polygons. The points have a unique identifier, and any number of points can have the same unique identifier.
- Counting the number of points within the polygons is not what I'm after. I want to count the number of points with a unique ID (like barcode for example) in Polygon 1 that are also found within Polygon 2 (and also the inverse, unique detection in Polygon 1 not in 2 and unique detections in 2 not 1).
- This applies to animal tracking. An animal tracklog is detected in area A and also detected in area B, based on the barcode in an attribute field.
- What I first did was a spatial join, whereby the point Feature Class was the target layer and the polygon layer the join layer. This gives a column in the point Feature Class with the Polygon_ID.
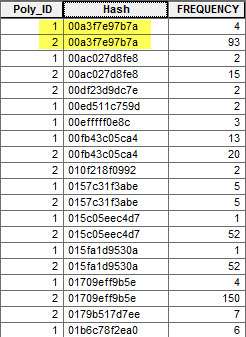
- I then used Summary Statistics to produce an output table that gives me Polygon_ID, barcode and count (using PolyID as the CASE). This is great because for each unique barcode I now have a maximum of two rows, one for Polygon 1 and one for Polygon 2 (the count is largely irrelevant for my purposes).
- However, using this summary table I now want to somehow count the number of unique barcodes that are assigned Polygon ID 1 and Polygon ID 2. Any suggestions?
0 Replies