- Home
- :
- All Communities
- :
- Products
- :
- Spatial Data Science
- :
- Spatial Data Science Questions
- :
- Summarize points in communities with buffer zone
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Summarize points in communities with buffer zone
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi there.
I would like to summarize the value of points within communities. My layer consists of about 500 communities and about 1 million points. I would like to summarize the points per community plus a buffer zone of about 100m arround the community. So there is the possibility that community A has points within their boundaries and also points in the buffer zone (actually within the boundaries of another community B). Now I would like to sum up the points for the community A. The points within the boundary should be fully weighted but the buffer points which community A shares with community B should only be weighted half. If there are three, four, five etc. communities with the same points in their bufferzone, the points should only be weighted on third, one fourth, one fifth etc...
Hmm, do you guys understand what I would like to do?  I was thinking of the weighted average tool but I didnt succeed how to do this...
I was thinking of the weighted average tool but I didnt succeed how to do this...
Thanks!
karlmay
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here's one rough idea of how you could go about it, if I understand the problem completely:
First do a spatial join (Analysis/Overlay/Spatial Join) using your points as target features and your buffered communities as the join features; for the join operation, select "JOIN_ONE_TO_MANY", and keep the other defaults as is. This will give you a potentially large point layer - you might need to divide up your areas, depending on how many community overlaps there are. For points in community overlap areas, the output FC will contain one point for every overlapping polygon.
You can then use the output attribute table to count up how many polygons (buffered communities) each point falls into - use the Frequency tool (Analysis/Statistics/Frequency) with frequency field "TARGET_FID" and no summary field. The output will be a table of point IDs (TARGET_ID) with the number of overlaps that each point falls within.
You can then join the frequency field (TARGET_FID to TARGET_FID) back to the point layer that's been spatially joined to the buffered communities. This will give you a table with the community IDs, point information, and the weights you'll want to use for each point (the reciprocal of frequency). I'd probably dump out the attribute table to Excel and run a pivot table for your final analysis, but that's just my preference. If you pivot on JOIN_FID (which will be the community ID) and SUM (1 / frequency) * (point attribute of interest), you should have your weighted sums by community.
Hopefully that will work. With a million points you might run into some size problems that you may need to work around...
Good luck,
Chris
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Chris,
Thank for your answer. I haven't thought about summarizing all point in a polygon to one point. I will try it out as soon as I will be able to get at one of these fast computers at university...
Best wishes..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK, this may require a considerable number of steps and when you have many features, this will take time to process. I just processed a much smaller number of polygons and points to see if it works and it does, so below the steps I used to obtain the result.
- Create a polygon featureclass with a polygon that contains all the 500 counties (let’s call it Dummy Area).
- Buffer the counties with the desired distance (will create overlapping polygons)
- Intersect the buffered polygons with the Dummy Area. This will create a polygon featureclass were every overlapping part will occur the number of times the polygon overlaps
- Create centroid points (Feature to Points tool) . This will create a point featureclass with overlapping points were the polygons overlapped.
- Add X and Y coordinates in fields to the points featureclass as long value and concatenate those values into a new text field (let's call this field DissolveID).
- Summarize the DissolveID field to generate a table with a count of overlapping points
- Join that count back to the overlapping points
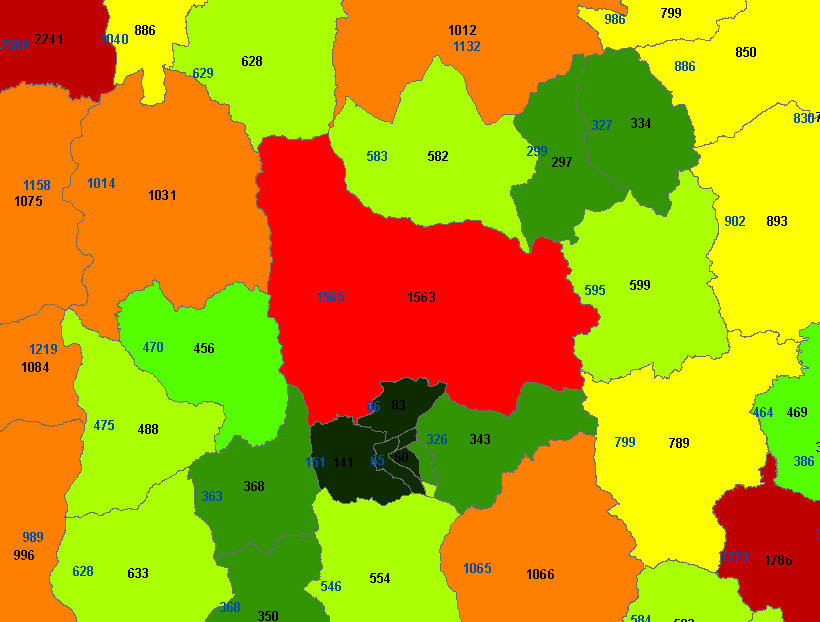
At this point you should have something like this:

Each point with label is indicating how many buffered polygons are overlapping at that location.
- Use the OID to join the number of points and the DissolveID from the centroid points to the intersected buffers.
- Dissolve the intersected polygons based on the DissolveID to merge the overlapping polygons into a single polygon
- Join the points to the dissolved polygons in such a way that you will get the count of the points in each polygon.
- Calculate the fraction of points by dividing the number of points in each polygon by the number of overlapping polygons at that location
- Dissolve the polygon on ORIG_OID and summarize the fraction of points to obtain the number you are looking for
- You can join these back to your original polygons
If I compare the results (blue labels) with a normal join of the points, the difference is not very big:
Any specific reason why you don't want to simply join the points to the polygons?