- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Update features with multiple values, Spatial Join...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Update features with multiple values, Spatial Join or Select by Location Or Dictionaries
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a hard time with field mapping and the only form I seem to understand is the following but it also seems to not work, maybe I doing it wrong but here is what I found. Using a code like below
PIN "PIN" true true false 13 Text 0 0 ,First,#, {0}, PIN,-1,-1;
ACRES "ACRES" true true false 4 Double 0 0 ,First,#, {0}, ACRES,-1,-1;
PARCEL "PARCEL" true true false 50 Text 0 0 ,First,"#",{0}, PARCEL,-1,-1;
PARCELS "PARCELS" true true false 200 Text 0 0 ,Join,",", {1}, PARCEL,-1,-1
arcpy.SpatialJoin_analysis(Par, Par1, "BlahTest", "JOIN_ONE_TO_ONE", "KEEP_ALL",Layers1(Par1), "INTERSECT")
I found that the output had 19 parcels inside the "PARCELS" field and it looked incorrect. So I opened up Arcmap and used select by location with the same spatial selection method "intersect" and selected 25. So I would like to use spatial join with Dictionaries or Select By Location if possible but my problem is how to use the merge rule and delimiter to update the fields. How would I apply the code I am using to use Dictionaries or Select By Location?
Outcome of field PARCELS should be something like the following.
PIN12345,PIN12346,PIN12347, PIN12348, etc.
arcpy.SpatialJoin_analysis(updateFC, Par, sj, "JOIN_ONE_TO_ONE", "KEEP_ALL")
# define the field list from the spatial join
sourceFieldsList = ["TARGET_FID", "Parcel_1"]
# define the field list to the original Parcels
updateFieldsList = ["OID@", "PARCELS"]
# populate the dictionary from the polygon
valueDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sj, sourceFieldsList)}
with arcpy.da.UpdateCursor(updateFC, updateFieldsList) as updateRows:
for updateRow in updateRows:
keyValue = updateRow[0]
if keyValue in valueDict:
for n in range (1,len(sourceFieldsList)):
updateRow[n] = valueDict[keyValue][n-1] #How do update the field to include multi values from the selection by location?
updateRows.updateRow(updateRow)
del valueDicttargetLayer = "In_memory\tempTarget"
arcpy.MakeFeatureLayer_management(target, targetLayer)
MergetLayer = "In_memory\tempMerge"
arcpy.MakeFeatureLayer_management(Merge2,MergetLayer)
with arcpy.da.SearchCursor(Merge2,["SHAPE@", "PARCEL"]) as cursorSearch:
for row in cursorSearch:
arcpy.SelectLayerByLocation_management (targetLayer, "INTERSECT", row[0])
with arcpy.da.UpdateCursor(targetLayer,["SHAPE@", "PARCELS"]) as cursorUpdate:
for row2 in cursorUpdate:
row2[1] = row[1] #How do update the field to include multi values from the selection by location?
cursorUpdate.updateRow(row2)Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Randy,
Thank you for sharing your code and trying to help me out.
I get two different results, I first tried it your code in a stand alone script and I got something totally different than you. The first pic below is the script I ran Arcmap 10.6.1 python window . The second pic is the results I got when I ran it through it in 3.6.8 python, stand alone script. When I run the stand alone I noticed that the 'PAR_COUNT' doesn't get populated correctly it's OID 374 over and over.? I was able to put a print statement to print out the OID and Count but like I said it's the same count over and over. I am also confused as to why I get two different results.

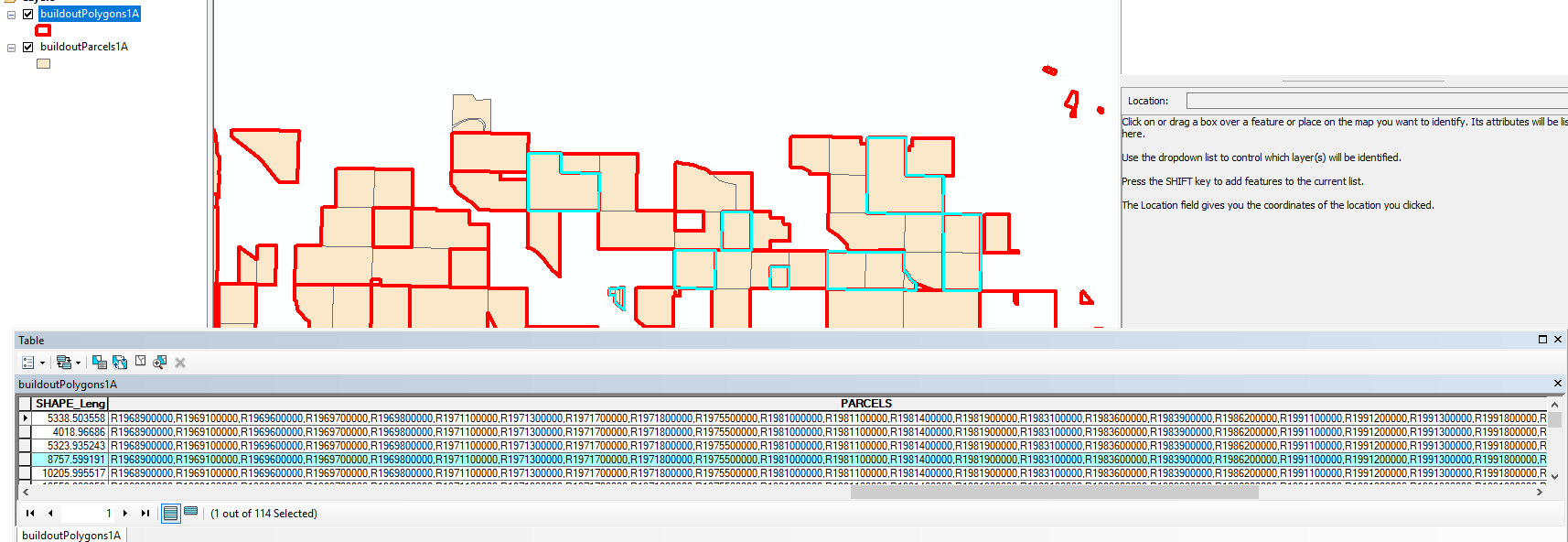
polygons = 'buildoutPolygons1"
parcels = 'buildoutParcels1A"
# clear all selected features
arcpy.SelectLayerByAttribute_management(polygons, "CLEAR_SELECTION")
arcpy.SelectLayerByAttribute_management(parcels, "CLEAR_SELECTION")
with arcpy.da.UpdateCursor(polygons, ['SHAPE@', 'OID@', 'PAR_COUNT', 'PARCELS']) as cursor:
for row in cursor:
arcpy.management.SelectLayerByLocation(parcels, "HAVE_THEIR_CENTER_IN", row[0], "", "NEW_SELECTION")
par_count = int(arcpy.GetCount_management(parcels)[0]) # parcel count
# get list of parcel id numbers
pins = []
with arcpy.da.SearchCursor(parcels, ['PARCEL']) as parcelsCursor:
for parcelRow in parcelsCursor:
pins.append(parcelRow[0]) # save PIN in pins list
# print for testing
print ("OID {}, Count{}".format(row[1],par_count))#print (row[1], par_count) # OID@ and count
#print (','.join(pins)) # parcel ids in polygon
#print
# update row
row[2] = par_count
#row[3] = ','.join(pins) # not updated as some results longer than field width
#cursor.updateRow(row)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I feel dumb, I had to make the layers "Feature Layers" to work in the stand alone script.
Thanks for all you help Randy.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've had that feeling, too. Glad to help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
How do I get this to loop through all the features in a stand alone script?
should the arcpy.da.SearchCursor allow it to loop through all the features?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As you asked about using a dicitonary as part of the solution, here is an approach similar to the one suggested by Nicholas Klein-Baer. I used the collections dictionary which simplifies things when the values are lists.
One issue that may be contributing to the problem is that when 2 features using the same field names are joined, the joined feature's fiields will be renamed, usually by appending "_1". You should check the join to verify that you are using the proper field names.
Here is my test code:
import collections
d = collections.defaultdict(list)
polygons = 'buildoutPolygons1' # outer polygons that border groups of parcels
parcels = 'buildoutParcels1'
joined = 'in_memory\\test_join' # this can be temporary
# join blocks to parcels
arcpy.SpatialJoin_analysis(
target_features = parcels,
join_features = polygons,
out_feature_class = joined,
join_operation = "JOIN_ONE_TO_ONE",
join_type = "KEEP_COMMON",
match_option = "HAVE_THEIR_CENTER_IN")
# NOTE: both polygons and parcels contain the fields: OBJECTID and PARCEL
# the join has appended "_1" to these fields from polygons
# *** verify this before continuing ***
fields2dict = ['PARCEL_1', 'PARCEL' ] # key is from polygons and value is from parcels
# an alternative is to use OBJECTID_1 in place of PARCEL_1
# search cursor processes joined feature into dictionary
with arcpy.da.SearchCursor(joined, fields2dict) as cursor:
for key, value in cursor:
d[key].append(value)
# print d
# dictionary will be in format { 'BLOCK_ID' : [ 'PIN_ID_1', 'PIN_ID_2', ... ], ... }
# examining the dictionary will help determine if length of
for k in d.keys():
print k, "parcels = {} : field length = {}".format(len(d),len(d)*12)
# the PARCEL field in polygons will be the key, PARCELS will be updated
updateFields = ['PARCEL','PARCELS'] # BLOCK matches dictionary key
# NOTE this will fail as field length needs to be about 800 characters wide
# shapefiles have a text field limit of 250 characters
# update cursor uses dictionary d to update PINS field
with arcpy.da.UpdateCursor(parcels, updateFields) as cursor:
for row in cursor:
row[1] = ','.join(d[row[0]]) # row[0] is key for dictionary, row[1] will be updated with list
cursor.updateRow(row)
arcpy.Delete_management(joined) # delete in_memory object
# refresh may be required to see changes As I mentioned in my previous post, some of the parcel id numbers concatenate into a string longer than the width of the field. Lines 31 an 32 will print an estimate of the required field width to store the concatenated string.
R3590700000 parcels = 66 : field length = 792
R3601400000 parcels = 7 : field length = 84
R3733600000 parcels = 3 : field length = 36
R3612900000 parcels = 4 : field length = 48
R3681301000 parcels = 4 : field length = 48
R3681100000 parcels = 2 : field length = 24
R3676401100 parcels = 5 : field length = 60
R3682300000 parcels = 1 : field length = 12
R3602300000 parcels = 2 : field length = 24
R3701400000 parcels = 1 : field length = 12
R3690600000 parcels = 2 : field length = 24
R36103010A0 parcels = 8 : field length = 96
R3675500000 parcels = 12 : field length = 144
R3610302000 parcels = 6 : field length = 72
R3691500000 parcels = 1 : field length = 12
R3613301000 parcels = 5 : field length = 60
R3608900000 parcels = 10 : field length = 120
R3608601000 parcels = 1 : field length = 12
R3602601000 parcels = 16 : field length = 192
R3610100000 parcels = 3 : field length = 36
R3663801000 parcels = 54 : field length = 648
R3729700000 parcels = 6 : field length = 72
R3675400000 parcels = 2 : field length = 24
R3613500000 parcels = 1 : field length = 12
R3710800000 parcels = 1 : field length = 12
R3613600000 parcels = 2 : field length = 24
R3701500000 parcels = 2 : field length = 24
R3666600000 parcels = 2 : field length = 24
R3612901100 parcels = 8 : field length = 96
R3703500000 parcels = 3 : field length = 36
R3678200000 parcels = 4 : field length = 48
R3702500000 parcels = 2 : field length = 24
R3672200000 parcels = 1 : field length = 12
R3677000000 parcels = 6 : field length = 72
R3671100000 parcels = 2 : field length = 24
R3703200000 parcels = 1 : field length = 12
R3676200000 parcels = 2 : field length = 24
R3672300000 parcels = 4 : field length = 48
R3682600000 parcels = 14 : field length = 168
R3610301000 parcels = 2 : field length = 24
R3608600000 parcels = 2 : field length = 24
R3600000000 parcels = 1 : field length = 12
R3710501200 parcels = 2 : field length = 24
R3665700000 parcels = 2 : field length = 24
R3592200000 parcels = 17 : field length = 204
R3612300000 parcels = 2 : field length = 24
R3679300000 parcels = 1 : field length = 12
R3677601000 parcels = 6 : field length = 72
R3733400000 parcels = 1 : field length = 12
R3602401100 parcels = 1 : field length = 12
R3667800000 parcels = 2 : field length = 24
R3678700000 parcels = 4 : field length = 48
R3663700000 parcels = 3 : field length = 36
R3612400000 parcels = 3 : field length = 36
R3679501000 parcels = 8 : field length = 96Two of the "buildoutPolygon" features have more parcel id's than will fit in a field width of 250 characters.
Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
import collections
d = collections.defaultdict(list)
with arcpy.da.SearchCursor(joined, fields2dict) as cursor:
for key, value in cursor:
d[key].append(value)import collections
Wow this is so much cleaner, I'll have to use this in the future. Never new about collections.defaultdict() before, thanks for sharing!
Also unpacking the row tuple in the for loop makes it way more readable than using row!
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »