- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Sum Area Grouped By Attribute
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello everyone,
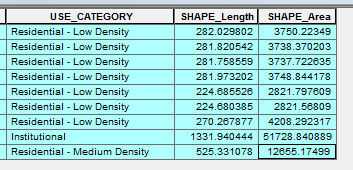
I have some data that looks like the attached pic. There's got to be an easy way to get a total area for each USE_CATEGORY and put the totals into a list or dictionary. Not sure if I need to maintain which total relates to which USE_CATEGORY. I don't need it for the current calculation I want to do, but may be worthwhile if I want to write it out to some external format later.
Thanks for any help/pointers.
Solved! Go to Solution.
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I agree with Dan, Summary Statistics is the first thing that comes to mind. Since you mentioned putting "the totals into a list or dictionary," you could use a defaultdict:
from collections import defaultdict
use_areas = defaultdict(float)
fc = # path to feature class
with arcpy.da.SearchCursor(fc, ["USE_CATEGORY","SHAPE_Area"]) as cur:
for use, area in cur:
use_areas[use] += area- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, summary statistics. I'm not sure why that didn't pop into my head as I've already used it previously. I think I was focused more on the list/dictionary. I'm working on using summary statistics now and trying to use in_memory tables. Once that's working I think I'll do it using the defaultdict, just for the learning. I'll update the thread as things progress.
Thanks all.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm surprised that Joshua didn't offer a pandas solution with its groupby function as well as a to_dict() --- the problem is with the limitations of FeatureClassToNumPyArray with some column types, but this may be something to consider. This gets close but I don't think it's exactly what you are looking for.
fc = r'H:\MyfeatureClass'
#Create array
nparr = arcpy.da.FeatureClassToNumPyArray(fc, ['USE_CATEGORY','Shape_Area'])
#get array as pandas dataframe and populate the repeating values column
df = pandas.DataFrame(nparr,columns=['USE_CATEGORY','Shape_Area'])
#summarize as desired on shape area
df = df.groupby(by='USE_CATEGORY', as_index=True)['Shape_Area'].sum()
#make it a dictionary
myDictionary = df.to_dict()- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
James... numpy... did a split and count of a featureclass of mostly equal polygons. The process is like df.groupby
The big difference is you call the da.SearchCursor as usual, the line 5 is the key, it is what the ArcGIS module uses extensively in its code as I posted in my last blog.
in_fc = r"C:\no_space\path\testdata.gdb\Carp_5x5" # full 25 polygons
sc = arcpy.da.SearchCursor(in_fc, ['OBJECTID', 'Shape', 'Class'], explode_to_points=True)
arr = sc._as_narray()
un, idx, cnts = np.unique(arr['Class'], return_index=True, return_counts=True)
un
array(['A01', 'A02', 'A03', ..., 'E03', 'E04', 'E05'],
dtype='<U5')
idx
array([ 0, 5, 10, ..., 109, 114, 119], dtype=int64)
cnts
array([5, 5, 5, ..., 5, 5, 5], dtype=int64)
result = np.asarray(list(zip(un, cnts)), dtype=[('Class', '<U5'), ('Counts', '<i4')])
result
array([('A01', 5), ('A02', 5), ('A03', 5), ..., ('E03', 5), ('E04', 5),
('E05', 5)],
dtype=[('Class', '<U5'), ('Counts', '<i4')])
result.tolist()
[('A01', 5),
('A02', 5),
('A03', 5),
('A04', 5),
('A05', 5),
('B01', 5),
('B02', 5),
('B03', 5),
('B04', 5),
('B05', 5),
('C01', 5),
('C02', 5),
('C03', 4),
('C03E', 4),
('C03N', 4),
('C03S', 4),
('C04', 5),
('C05', 5),
('D01', 5),
('D02', 5),
('D03', 5),
('D04', 5),
('D05', 5),
('E01', 5),
('E02', 5),
('E03', 5),
('E04', 5),
('E05', 5)]- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I like pandas, and especially like that it is now bundled with ArcGIS, but one rub I have with it is the poor documentation compared to other Python documentation. I find people new to Python struggle with the pandas documentation, unnecessarily so. I know I could put my something where my mouth is and contribute to the docs myself, but it isn't a big enough priority to fit into my schedule for the time being. In this case, a defaultdict works well and is a nice introduction to the extended data types in the collections module.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
What version of arcmap is pandas bundled?
I’m learning pandas right now and find the documentation tough. At least there’s stackexchange.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Esri originally announced it would be 10.3.1, but it got pushed back to 10.4: What's new in ArcMap 10.4
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've had no opportunity to date to look at doing this using dictionaries, but summary statistics is working great. So I think I'll just leave it at that.
Thanks everyone!