- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Suggestions for an Algorithm for Assigning Values ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Suggestions for an Algorithm for Assigning Values Based on Spatial Proximity
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am trying to come up with an algorithm that can handle the problem of assigning the values of an attribute of a set of polygon features in one feature class to the set of polygon features in another feature class based on proximity. I can conceive of several ways to approach this problem using Python and/or Geoprocessing tools, but I need to optimize the final algorithm for performance. I am hoping for python coding or geoprocessing suggestions that could accomplish each step in the best order to achieve the greatest overall efficiency and speed. The suggestions do not have to tackle the whole problem and can be focused on any part, but I am laying out the complete problem so each step can be seen in light of the overall goal of the algorithm.
Assume I have two polygon feature classes named FC_A and FC_B which have two attribute fields called Case_Field and Value_Field in both feature classes. The following conditions must be met for the algorithm to reach a solution:
1. All conditions listed below should only consider and compare the set of features that have a common Case_Field value in both FC_A and FC_B and if the set of features is not limited to a single Case_Field value then the number of overlapping features in both feature classes is massive.
2. A solution is only reached when every unique value in the Value_Field of FC_A has been be assigned to at least one feature in FC_B and all of the features in FC_B have been assigned a value in the Value_Field from the set of unique values in FC_A.
3. The total number of unique values in Value_Field in FC_A must be equal to or less than the number of features in FC_B to be analyzed by this algorithm, otherwise the set of features associated with that Case_Field value will be ignored.
4. If a feature in FC_A does not overlap any of the features in FC_B the value in Value_Field of FC_A must be assigned to the closest feature in FC_B, provided that the FC_B feature has not previously been assigned a value from FC_A to satisfy this condition.
5. Any feature in FC_B that is overlapped partially or completely by only one feature in FC_A will be assigned the value from the FC_A feature that overlaps it, provided that the FC_B feature has not already been assigned a value to satisfy condition 4 above.
6. Any feature in FC_B that has portions overlapped by two or more features in FC_A will be assigned the value from the FC_A feature that overlaps its centroid or that is closest to its centroid if the centroid is not overlapped, provided that the FC_B feature has not already been assigned a value to satisfy condition 4 above.
An illustration of the problem is shown below for one of the sets of features in FC_A and FC_B that all share a common Case_Field value. The polygons with a grey fill and a colored outline are in FC_A and are labeled with the value stored in the Value_Field. The polygons that are colored light purple are in FC_B and have Null in the Value_Field. (Note: some of the values in the Value_Field of FC_A are actually associated with many polygons, but they should all be treated as a single dissolved polygon for the purposes of this algorithm.)
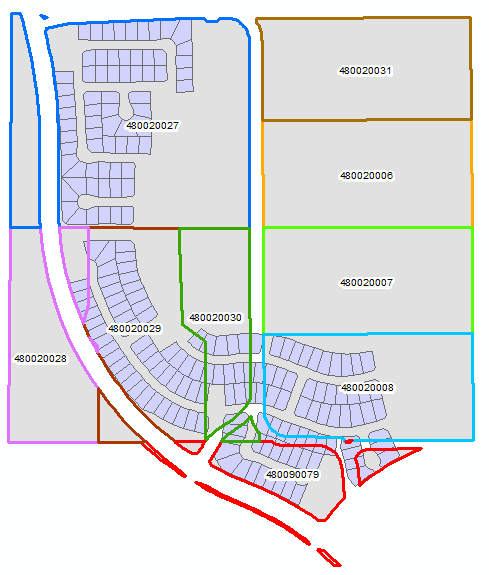
The solution should look something like the output below. The FC_B fill and the FC_A outline have been assigned the same color for each value in the Value_Field
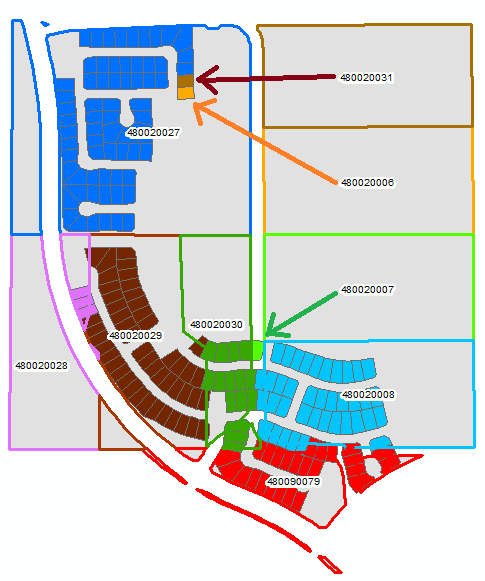
Notice that values from the polygons in FC_A that do not overlap any of the polygons in FC_B have still been assigned to one of the FC_B polygons. I did this manually, so I may not have chosen the closest polygon to satisfy condition 4, but I would expect the algorithm to chose the closest polygon.
If it turns out that after fully optimizing the steps that evaluate spatial proximity those steps would take 5 or more minutes to reach the solution of the sample problem above, I would probably end up settling for a solution that only satisfies conditions 1 through 3 using the fastest python algorithm that can randomly distribute the values from FC_A into FC_B. However, I prefer a solution that takes the spatial relationship into account.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have come up with an algorithm that can meet all of my criteria. In 3 minutes and 13 seconds the code can find solutions for 27,542 records in FC_A and 64,985 records in FC_B that match up on a total of 2,773 unique case values, so the performance is excellent. The code currently only solves the problem without writing an output, but now that the problem is solved I can extend the code to output the results in a variety of different ways, depending on my needs.
A portion of the code could be used to replace the Spatial Join tool when features need to be matched based on a shared case value to avoid unwanted joins due to feature overlap. Additionally, the Spatial Join component of the code is similar to using the One To One option with a case field and the first option on another field in the summary options, but it is enhanced so that it will favor exact attribute matches on the second field over any spatial relationship and otherwise favor overlap of the FC_B centroid with the FC_A polygon over merely being the first FC_A feature to touch the FC_B feature.
Beyond the spatial join, the code has additional logic for matching all unique values in the second field between FC_A and FC_B based on the closest feature when no exact attribute match or feature overlap exists, as I required. So solving problems like this can be done very efficiently with arcpy.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
What is the reason for the spatial assignment?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The particular set of data I am currently working with could disregard the spatial component, but the value assignment makes much more sense as shown than using a random assignment. However, I have other problems I would love to tackle that I have never attempted, because they are only worth tackling through this kind of spatial algorithm. The data in my example is current and historic parcels and the output I am trying to create mimics parcel history. I do not have access to parcel history data from my Assessor and if I did it would only complicate the problem by adding another many to many relationship I would have to manage.
If the spatial problem was removed I would still be open to suggestions on how to approach the non-spatial portion of the problem, especially if they involved modules beyond native python and arcpy. I have avoided learning numpy up to now, but could be persuaded to learn it if it has application to solving problems like this.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have come up with an algorithm that can meet all of my criteria. In 3 minutes and 13 seconds the code can find solutions for 27,542 records in FC_A and 64,985 records in FC_B that match up on a total of 2,773 unique case values, so the performance is excellent. The code currently only solves the problem without writing an output, but now that the problem is solved I can extend the code to output the results in a variety of different ways, depending on my needs.
A portion of the code could be used to replace the Spatial Join tool when features need to be matched based on a shared case value to avoid unwanted joins due to feature overlap. Additionally, the Spatial Join component of the code is similar to using the One To One option with a case field and the first option on another field in the summary options, but it is enhanced so that it will favor exact attribute matches on the second field over any spatial relationship and otherwise favor overlap of the FC_B centroid with the FC_A polygon over merely being the first FC_A feature to touch the FC_B feature.
Beyond the spatial join, the code has additional logic for matching all unique values in the second field between FC_A and FC_B based on the closest feature when no exact attribute match or feature overlap exists, as I required. So solving problems like this can be done very efficiently with arcpy.