- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Split values of a field
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello guys,
I want to split this values 12345/6789/ST/1 to 12345/ST/1, so i am looking to a formula in a field calculator which can do so.Also for the cases like this 12345/6789/st/1, 12345/6789/st1, 12345/6789/st 1, all this to become 12345/ST/1.
With thanks,
Kelvin.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ohhk...
If you could just resolve the "ST/1" related issues with FIND and REPLACE, as mentioned above
then follow the script given below in Python Parser of Field Calculator of a new field (TEST)
!name!.split("/")[0] + !name![::-1][0:5][::-1]
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear Kelvin
The Python syntax for the Calculate Field tool would be:
SPLIT1 = !ORIG_FIELD!.split(" ")[0] #0 being the 1st word
SPLIT1 = !ORIG_FIELD!.split(" ")[-1] #-1 being the last word
Kindly go through below steps also
For example, here is a field from some census data I downloaded:

Why did they add the text “Census Tract” to all of these? Seems to be a space waster right? All I really want is just the tract number. So what I will do is create a new field, then calc the value to the 3rd word, or tract number, from the other field.
First I create a new field named appropriately TRACTNUM. You simply do this using the attribute table window pulldown > Add field…

Next, I enter the field name, set the type to Text, and set the length to 10.

My tract numbers will not be longer than 10 characters. Press the OK button and the field will be added to the end of the attribute table.
Next, I scroll over to the new field name in the attribute table and right click on it to select the field calculator.

The field calculator appears. I am using ArcMap 10.1, so I select the Python parser, then double click on the NAMELSAD10 field that contains the tract numbers I want to extract, then set the type to String and click on the .split() function. Next in the expression area between () I enter a double quote, a space, and another double quote, then add [2] at the very end. The expression should look like the following:

What this will do is take the text from the NAMELSAD10 field, pass it to the split function which uses the space ” ” as the delimiter to separate the words and then extracts the third word for the TRACTNUM field calculation. In Python, position 0 would be the first word, position 1 the second word, and position 2 the third word, which we want. That is why I used [2].
With everything set in the field calculator, click the OK button. Once the calculation is complete, you will see just the tract numbers in the TRACTNUM field.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Abhishek,
What about the 2nd data from last ie.ST also should i write those syntax in series.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear Kelvin
Yes
the numric value indicate that the value which is to be seprated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I would rather use Find and Replace in attribute table
First replace "6789/" with "" (blank).
Then replace "st/1", "st1", "st 1" one after another by "ST/1".
*Do take a backup of the data before doing the above activity, since the changes are permanent.
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Jayanta,
That was just an example, the real thing was like this below.
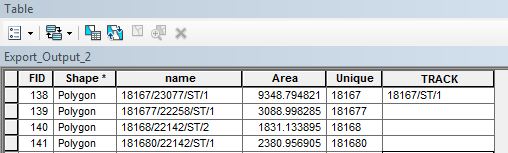
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ohhk...
If you could just resolve the "ST/1" related issues with FIND and REPLACE, as mentioned above
then follow the script given below in Python Parser of Field Calculator of a new field (TEST)
!name!.split("/")[0] + !name![::-1][0:5][::-1]
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In case that the length of the elements in the string vary, you will need to change the formula that Jayanta Poddar provided to something like:
"/".join([!name!.split("/")[0]]+!name!.split("/")[2:])Just have a look at the following code (especially lines 5 and 6)
lst = ['18167/23077/ST/1',
'181677/22258/ST/1',
'18168/22142/ST/2',
'181680/22142/ST/1',
'12345/1234/A/1',
'123456/123456/ABC/12']
for name in lst:
print name, '/'.join([name.split('/')[0]]+name.split('/')[2:])
print name, name.split("/")[0] + name[::-1][0:5][::-1]
print... and output (especially lines 13+14 and 16+17)
18167/23077/ST/1 18167/ST/1 18167/23077/ST/1 18167/ST/1 181677/22258/ST/1 181677/ST/1 181677/22258/ST/1 181677/ST/1 18168/22142/ST/2 18168/ST/2 18168/22142/ST/2 18168/ST/2 181680/22142/ST/1 181680/ST/1 181680/22142/ST/1 181680/ST/1 12345/1234/A/1 12345/A/1 12345/1234/A/1 123454/A/1 123456/123456/ABC/12 123456/ABC/12 123456/123456/ABC/12 123456BC/12