- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Select the top 20% of records.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
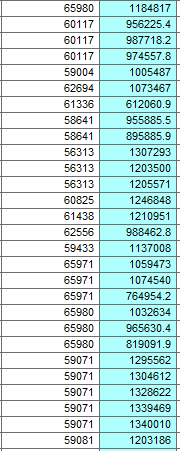
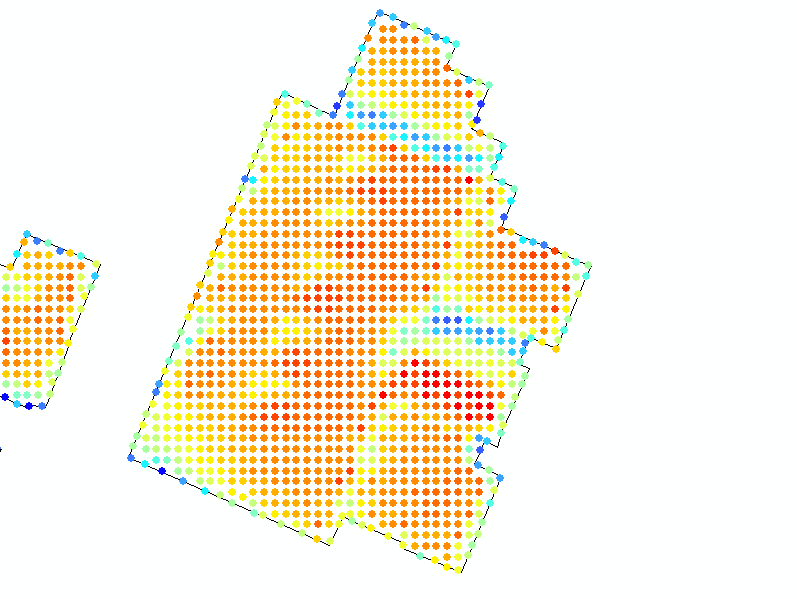
I have converted a raster into points. I have then clipped the raster with my buildings layer.
All buildings have a unique id and all the points in the same building have that id. (ex. in the image 65379 is the unique id for that building)
What I want to do is select the top 20% of points based on an attribute value for each building. Another issue is that the number of points per building changes based on the area.
I know how many points are in each building.
I am thinking I need a for each statement but I am not sure.
Any help is greatly appreciated.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If you want to select the top 20% of the highest values this code should work:
import arcpy
"""Customize the layer name, IDField and valueField"""
lyrName = "sourceLayer"
IDField = "RID"
valueField = "MEAS"
Top20Field = "TOP20PERCENT"
"""Get the current map layers."""
mxd = arcpy.mapping.MapDocument("CURRENT")
"""Find the layer name"""
lyr = arcpy.mapping.ListLayers(mxd, lyrName)[0]
"""Create a dictionary of keys, values and record counts"""
valueDict = {}
with arcpy.da.SearchCursor(lyr, [IDField, valueField, "OID@"]) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
if not keyValue in valueDict:
valueDict[keyValue] = [[(searchRow[1],searchRow[2])], 1]
else:
valueDict[keyValue][0].append((searchRow[1], searchRow[2]))
valueDict[keyValue][1] += 1
print "Dictionary Read"
"""Create an OID List of records that are in the Top 20%"""
OIDList = []
for keyValue in sorted(valueDict.keys()):
valueDict[keyValue][0] = sorted(valueDict[keyValue][0], reverse=True)
top20Percent = int(round(valueDict[keyValue][1] * .2, 0))
for n in range(0, top20Percent):
OIDList.append(valueDict[keyValue][0][1])
"""Write a flag value to the Top20Field to indicate whether or not each record is in the Top 20%"""
with arcpy.da.UpdateCursor(lyr,["OID@", Top20Field]) as updateRows:
for updateRow in updateRows:
if updateRow[0] in OIDList:
updateRow[1] = "Yes"
else:
updateRow[1] = "No"
updateRows.updateRow(updateRow)
If you want the top 20% with the lowest values change line 30 to valueDict[keyValue][0] = sorted(valueDict[keyValue][0])
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If you want to select the top 20% of the highest values this code should work:
import arcpy
"""Customize the layer name, IDField and valueField"""
lyrName = "sourceLayer"
IDField = "RID"
valueField = "MEAS"
Top20Field = "TOP20PERCENT"
"""Get the current map layers."""
mxd = arcpy.mapping.MapDocument("CURRENT")
"""Find the layer name"""
lyr = arcpy.mapping.ListLayers(mxd, lyrName)[0]
"""Create a dictionary of keys, values and record counts"""
valueDict = {}
with arcpy.da.SearchCursor(lyr, [IDField, valueField, "OID@"]) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
if not keyValue in valueDict:
valueDict[keyValue] = [[(searchRow[1],searchRow[2])], 1]
else:
valueDict[keyValue][0].append((searchRow[1], searchRow[2]))
valueDict[keyValue][1] += 1
print "Dictionary Read"
"""Create an OID List of records that are in the Top 20%"""
OIDList = []
for keyValue in sorted(valueDict.keys()):
valueDict[keyValue][0] = sorted(valueDict[keyValue][0], reverse=True)
top20Percent = int(round(valueDict[keyValue][1] * .2, 0))
for n in range(0, top20Percent):
OIDList.append(valueDict[keyValue][0][1])
"""Write a flag value to the Top20Field to indicate whether or not each record is in the Top 20%"""
with arcpy.da.UpdateCursor(lyr,["OID@", Top20Field]) as updateRows:
for updateRow in updateRows:
if updateRow[0] in OIDList:
updateRow[1] = "Yes"
else:
updateRow[1] = "No"
updateRows.updateRow(updateRow)
If you want the top 20% with the lowest values change line 30 to valueDict[keyValue][0] = sorted(valueDict[keyValue][0])
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you for your quick response!
It works as expected. I had a few issues at first, I was getting the error:
Runtime error
Traceback (most recent call last):
File "<string>", line 12, in <module>
IndexError: list index out of range
But I just ran it again and it started running!
The issue now is I have 12000 Buildings. At 30 sec per building it would take over 4 days to run. I have that kind of time but I believe it would be faster if it could run outside of arcmap.
Is there any way to sent an environment and instead of selecting the points create a new layer out of the top 20%
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
An Insert cursor would probably be the best for creating a new feature class and would finish in less than 2 minutes most likely. I would not do this, unless you create a unique key for each point that is not the ObjectID, since without that you have no way to reliably relate the new feature class to the old. So I won't do this based on what you have shown.
Select by Attribute, especially using the Add to Selection option is time consuming, but it was necessary if I was to do what you originally asked and not alter the schema of the table. The only way to avoid days of processing is to create a new flag field indicating if the record was in the Top 20% or not and use an update cursor to populate it. Then you could use a simple SQL selection on that field. That could complete in under 3 minutes. I will assume that is what you will do, since it is the easiest for me to recode and the most flexible for exporting and processing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I see your point about the ObjectID and matching up. Yes a flag field would work just as well!
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard,
I keep getting this error:
Runtime error
Traceback (most recent call last):
File "<string>", line 32, in <module>
TypeError: 'builtin_function_or_method' object has no attribute '__getitem__'
Do you have any suggestions?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try the code now. I was trying to write it without testing, but now I have tested it on my own data. 131652 records summarized based on 16040 unique ID categories were processed in 1 minute 8 seconds.