- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Python Near Analysis (No Advanced Licence)
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Python Near Analysis (No Advanced Licence)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I need to determine the shortest distance between each point within a single feature class. Near Analysis would have worked perfectly, but unfortunately you need to have an Advanced ArcGIS Licence and I only have a Standard Licence.
I found the following code on Stack Exchange written by PolyGeo:
import arcpy,math
# Set variables for input point feature classes and output table
ptFC1 = "C:/temp/test.gdb/PointFC1"
ptFC2 = "C:/temp/test.gdb/PointFC2"
outGDB = "C:/temp/test.gdb"
outTableName = "outTable"
outTable = outGDB + "/" + outTableName
arcpy.env.overwriteOutput = True
# Create empty output table
arcpy.CreateTable_management(outGDB,outTableName)
arcpy.AddField_management(outTable,"INPUT_FID","LONG")
arcpy.AddField_management(outTable,"NEAR_FID","LONG")
arcpy.AddField_management(outTable,"DISTANCE","DOUBLE")
# Create and populate two dictionaries with X and Y coordinates for each
# OBJECTID in second feature class using a SearchCursor
ptFC2XCoordDict = {}
ptFC2YCoordDict = {}
with arcpy.da.SearchCursor(ptFC2,["OBJECTID","SHAPE@XY"]) as cursor:
for row in cursor:
ptFC2XCoordDict[row[0]] = row[1][0]
ptFC2YCoordDict[row[0]] = row[1][1]
# Open an InsertCursor ready to have rows written for each pair of OBJECTIDs
iCursor = arcpy.da.InsertCursor(outTable,["INPUT_FID","NEAR_FID","DISTANCE"])
# Use a SearchCursor to read the rows (and X,Y coordinates) of the first
# feature class
with arcpy.da.SearchCursor(ptFC1,["OBJECTID","SHAPE@XY"]) as cursor:
for row in cursor:
x1 = row[1][0]
y1 = row[1][1]
for i in range(len(ptFC2XCoordDict)):
x2 = ptFC2XCoordDict[i+1]
y2 = ptFC2YCoordDict[i+1]
# Prepare and insert the InsertCursor row
iRow = [row[0],i+1,math.sqrt((x2-x1)*(x2-x1) + (y2-y1)*(y2-y1))]
iCursor.insertRow(iRow)
del iCursor
print "Done!"The following reports the distance of the first point to the rest of the points:
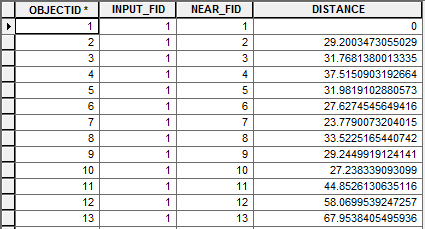
I would like to amend the following to iterate through each point within the feature class to report the shortest distance between the points, greater than zero of course. Any advice in amending the following will be appreciated. I'm trying to use the results from this as a way of validating that none of the points are within 3m or less from each other and if there are the filtered list is processed further to move the points away from each other within bounding box for each point.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Peter
distance from the first point in a point file to all other points in the file.
the rest of the problem is homework :
"""
Script: distance_einsum.py
Author:
Dan.Patterson@carleton.ca
Purpose: Yes
References:
Numpy Repository stuff
"""
import numpy as np
import arcpy
np.set_printoptions(edgeitems=3,linewidth=80,precision=2,suppress=True,threshold=10)
def einsum_dist(origin,destin):
"""using einsum"""
deltas = destin - origin
return np.sqrt(np.einsum('ij,ij->i', deltas, deltas))
def demo(a):
""" demo of one origin to all other points"""
orig = a['Shape'][0]
dest = a['Shape'][1:]
dist = einsum_dist(orig,dest)
out = np.zeros((len(dist)+1,3))
out[:,0] = a['Shape'][:,0] # the Xs
out[:,1] = a['Shape'][:,1] # the Ys
out[1:,2] = dist
return out
if __name__=="__main__":
"""sample run for distance demo"""
f = r"F:\A2_in_progress\NearDemo\Shapefiles\RandomPnts.shp"
shp_field = "Shape"
a = arcpy.da.FeatureClassToNumPyArray(f, shp_field)
b = demo(a)
# send it to a featureclass if desired
print("X, Y, distance from the first point \n{}".format(b))
result
>>> X, Y, distance from the first point
[[ 342059. 5022985. 0. ]
[ 342431. 5025573. 2614.6 ]
[ 341341. 5024714. 1872.16]
...,
[ 343020. 5022952. 961.57]
[ 343198. 5025388. 2659.27]
[ 342635. 5023786. 986.6 ]]
Now where are those close points and how many of them are there? slice and dice. b[:,2] is the distance column ... b[:,2] < 1000 are all the distances < 1000 m ... Therefore:
b[b[:,2]<1000] must be all the records where the distance is less than 1000m .. now what? save it to a featureclass. And yes you can get all fancy with inputs, retaining variable, etc. but that should suffice. It is pretty quick up about 50,000,000 origin destinations.
>>> b[b[:,2]<1000]
array([[ 342059. , 5022985. , 0. ],
[ 341427. , 5023380. , 745.28],
[ 342494. , 5022158. , 934.43],
...,
[ 342195. , 5023291. , 334.86],
[ 343020. , 5022952. , 961.57],
[ 342635. , 5023786. , 986.6 ]])
>>> len(b[b[:,2]<1000])
24
>>>
Check Numpy Repository or contact me for further information.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Dan, much appreciated. Will get back to you once I've done my homework 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I can put an 'all points' to 'all points' incarnation online, but I will let you digest that version first.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
HI Dan
Thanks, will give me a chance to figure it out first before you post the answer . Thanks for being such a great teacher. I have learnt a great deal from you already. My Python skill set has grown tremendously over the last 3 months.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dan,
I know this is an old post but your answer was almost exactly what I was looking for and I'm wondering if you can help me. I have bus location information that is coming in daily (approx 50K of points a day) that I need to verify that the location cited is using the correct bus stop. The initial data is individual records about each fare that boards the bus, but we have been aggregating that down to the individual stops to reduce the data size. It's still to large to push all of it into a featureclass, so it lives as SQL Server data only.
In order to get the nearness calculated, I've been trying to use SQL Server Spatial, but that's not as fast as I would like it to be. When I came across this post, the concept of using Numpy became an option and I've built the code below to compare 2 different tables and return the id from the first one, and the corresponding id/minimum distance from the second one. Using 2 small feature classes I have been able to verify that the minimum distance for each input point is correct, but when I expand that to a larger table (only ~750 records) I don't seem to be getting the minimum distance any more. Am I missing something about getting the minimum distance, or is there a better way to get the minimum distance from the results, or is the numpy.einsum request even working right.
Still trying to understand it all but I at least thought I had it working. At the end of my rope though so I'm hoping you might be able to shed some light.
##Script: distance_einsum.py
##Author: [email protected], and others
##Purpose: Numpy Repository stuff
##References:
## https://community.esri.com/thread/175646
## https://numpy.org/doc/stable/reference/generated/numpy.einsum.html
## https://towardsdatascience.com/how-fast-numpy-really-is-e9111df44347
## https://en.wikipedia.org/wiki/Einstein_notation
## https://pro.arcgis.com/en/pro-app/arcpy/data-access/tabletonumpyarray.htm
##import os, sys
import numpy as np
import arcpy
import numpy.lib.recfunctions, scipy.spatial, random, cProfile
from scipy.spatial import distance
import pandas as pdnp.set_printoptions(edgeitems=3, linewidth=80, precision=6, suppress=True, threshold=10)
def npNear(f1,f2):
f1shp_fields = ["DilaxID","LAT", "LON"] # DilaxBusTest
#f1shp_fields = ["OID@", "SHAPE@XY", "POINT_Y", "POINT_X"] # RandomPoints
f2shp_fields = ["OID@", "SHAPE@XY"]
#a = arcpy.da.FeatureClassToNumPyArray(f1, f1shp_fields)
#b = arcpy.da.FeatureClassToNumPyArray(f2, f2shp_fields)
a = arcpy.da.TableToNumPyArray(f1, f1shp_fields)
b = arcpy.da.TableToNumPyArray(f2, f2shp_fields)
origs = np.array(pd.DataFrame(a[:][['LON', 'LAT']])) ## Change if using different f1 fields
dests = b['SHAPE@XY'][:]
cols = range(2,3)subts = origs[:,None,:] - dests
dist = np.sqrt(np.einsum('ijk,ijk->ij',subts,subts))
#print(dist)out = np.zeros((len(dist),3))
out[:,0] = a['DilaxID'][:] # the initial table's ID field (f1, a, origs)
out[:,1] = np.argmin(dist, axis=1) # minimum value from the distance calc
out[:,2] = np.amin(dist, axis=1) # minimum value's id, to be associated to later
return outif __name__=="__main__":
#f1 = r"d:\Projects\GTFS_Update_Checker\RandomPoints.shp"
#f2 = r"d:\Projects\GTFS_Update_Checker\Random2.shp"f1 = os.path.join(sys.path[0], r"Ridership on W-SQL01.sde\Ridership.dbo.DilaxBusTest")
f2 = os.path.join(sys.path[0],r"GTFS on W-SQL01.sde\GTFS.dbo.BusStopsWM")
outPath = os.path.join(sys.path[0], r"Ridership on W-SQL01.sde\Ridership.dbo.DilaxBusDistTest")start = time.time()
## Generate minimum distance array using Numpy Einsum
out = npNear(f1, f2)
## Remove output table if it exists
if arcpy.Exists(outPath):
arcpy.Delete_management(outPath)
## Create structured array for output
struct_out = numpy.core.records.fromarrays(
out.transpose(),
numpy.dtype([('dOID', numpy.int32), ('bOID', numpy.int32), ('distance', '<f8')]))
## Push structured array to output using ArcGIS NumPyArrayToTable function
arcpy.da.NumPyArrayToTable(struct_out, outPath)end = time.time()
print(out)
print(end - start)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Jeff
You should post a new question with formatted code. I came across this by chance since my current persona doesn't get mail links on old threads.
Also, use code formatting
/blogs/dan_patterson/2016/08/14/script-formatting
And you need to use projected data in order to get true distances. Decimal Degrees won't cut it.
There is no need to use pandas either.
... sort of retired...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dan, I’ve reposted it at https://community.esri.com/message/939475-determine-minimum-distance-between-all-points-in-two-tables.
Thank you.
<https://www.valleymetro.org>
Jeffrey Wilkerson
Senior GIS Administrator
101 N. 1st Ave., Suite 1400, Phoenix, AZ 85003
o: 602-495-8273
c: 480-272-1243
<https://www.valleymetro.org/> <https://www.facebook.com/valleymetro> <https://twitter.com/valleymetro> <https://www.instagram.com/valleymetro/>
<https://www.valleymetro.org/news/our-response-covid-19>
CONFIDENTIALITY NOTICE: This email message, including any attachments, is for the sole use of the intended recipient(s) and may contain confidential and privileged information. Any unauthorized review, use, disclosure or distribution is prohibited. If you are not the intended recipient, please contact the sender by reply email and destroy all copies of the original message.