- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Preserving a MySql datetime field in Python
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Preserving a MySql datetime field in Python
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a python script that extracts data from a MySql database and writes it to a csv. The original table is a mix of all sorts of field types including datetime and timestamp. Once the csv is written and I perform an an arcpy table to table to get it into a fgdb, the datetime fields automagically become text fields. Not so good if you need to filter by date....
CSV files are both a boon and bane: is there a way to go right from MySql to a File geodatabse, thus preserving the field types? Unfortunately I do not have admin rights to our e-gdb (Sql server back-end) so I can't go MySql to SqlServer....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
s = "2020-01-15 23:15:30" # --- universal
print(datetime.datetime(*time.strptime(s, "%Y-%m-%d %H:%M:%S")[:6]))
2020-01-15 23:15:30
t = "01-15-2020 23:15:30" # mon, day year
print(datetime.datetime(*time.strptime(t, "%m-%d-%Y %H:%M:%S")[:6]))
2020-01-15 23:15:30YYYY-MM-DD date format is it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In mySql the values (when not Null) are:
2019-07-08 10:59:11
Bruce Harold provides: https://community.esri.com/community/open-platform-standards-and-interoperability/blog/2019/09/26/us... which discusses odbc connections: my 64 bit windows 10 desktop has:
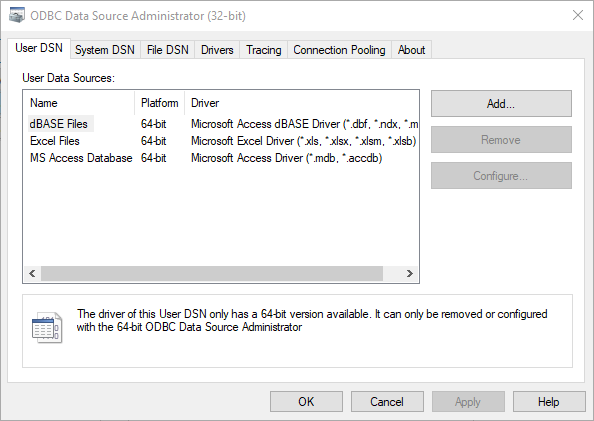
And the mySql site ( MySQL :: Download Connector/ODBC ) offers a 32 bit and a 64 bit driver. So I'm a little confused as to which odbc driver to down load and for that matter how to use pyodbc to traverse it. (Installing pyodbc package as I type this...)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I added to my post, YYYY-MM-DD is universal format great for sorting. If you need to parse by month, you can split on the string's - separator
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
It's a little more complicated that that: these tables get geocoded, and work their way into a published service which is then consumed by an Operations Dashboard app. Ultimately, it's in OD where I need to filter by date.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ahhh sorry ... don't do the 'consumed' side of things 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was afraid of losing you with that point!
As mentioned, I'm adding the pydobc package through the ArcGIS Python Package Manager, and its still running, which if you notice my post regarding that is about at an hour. Something is quite right there.....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
All, this pain is totally avoidable, just obtain the Data Interoperability extension and go directly from MySQL to File GDB. In Data Interop the reader is called MariaDB, in fact there are two, one spatial, one not. Bouncing data through CSV will throw the schema overboard as even writing a schema.ini file can't handle all data types.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Bruce Harold!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK full disclosure I'm the Product Manager for Data Interoperability 😉