- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Parse data from JSON service in several txt files
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Parse data from JSON service in several txt files
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm new in JSON and Python, I need to parse rainfall data from json hyperlinks that I saved in a shapefile.
This shapefile was created from a JSON service (http://www.sir.toscana.it/archivio/dati.php?D=json_stations ) that contain X, Y coordinates of gauge stations and an hyperlink of rainfall data for each gauge station. This is the result:
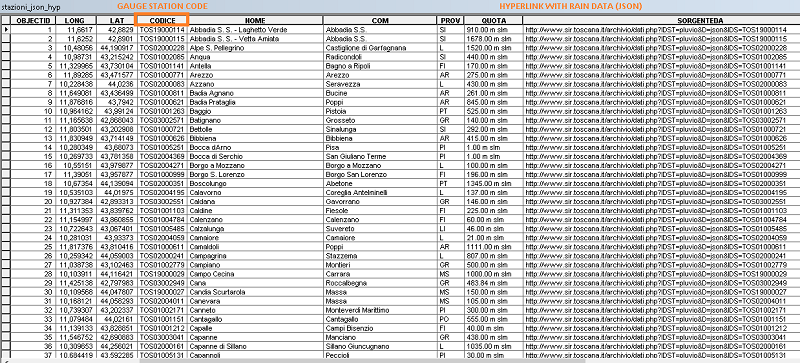
Now I want to create a script to save data contained in each link in a new text/csv/xls file using CODICE field as name for each output file. Or, if possible, save all the rainfall data (Stored in "SerieDati" --> "Valore") for each station (named "Codice" in json file) in an unique txt file in this format:

This is the model builder:

but i don't now how to finish my script.This is the script for one station...
--------------------------------------------------------------------------------------------------
import arcpy, sys, os, json, urllib2
urlink = arcpy.GetParameterAsText(0)
json_string = urllib2.urlopen(urlink).read()
data = json.loads(json_string)
#I want to print results for each station...
sys.stdout = open("C:\\Users\\ivn\\Desktop\\prova.txt", "w")
precip = data['properties']['SerieDati']
for i in precip:
print i
#And then...
-----------------------------------------------------------------------------------------------------
This is the output for one station :
{u'TipoValore': u'V', u'Data': u'2000-02-23 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-02-24 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-02-25 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-02-26 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-02-27 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-02-28 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-02-29 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-03-01 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-03-02 09:00:00', u'Valore': u'28.8'}
{u'TipoValore': u'V', u'Data': u'2000-03-03 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-03-04 09:00:00', u'Valore': u'0.0'}
{u'TipoValore': u'V', u'Data': u'2000-03-05 09:00:00', u'Valore': u'0.0'}
...
How to remove {,},u,' characters from output?
And this is JSON data for one station:
http://www.sir.toscana.it/archivio/dati.php?IDST=pluvio&D=json&IDS=TOS19000114
{"type":"Feature","geometry":{"type":"Point","coordinates":[11.6617,42.8829]},"properties":{"Codice":"TOS19000114","Nome":"Abbadia S. S. - Laghetto Verde","Comune":"Abbadia S.S.","Provincia":"SI","Quota":"910.00 mslm","UnitaMisura":"mm","TipiValore":{"N":"Non Validato","P":"Prevalidato","V":"Validato","@":"Mancante","R":"Ricostruito"},"TipoDati":"PLUVIOMETRIA - Aggregazione a 24 ore (9-9)","SerieDati":[{"Data":"2012-01-01 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-02 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-03 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-04 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-05 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-06 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-07 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-08 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-09 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-10 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-11 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-12 09:00:00","Valore":"","TipoValore":"@"},{"Data":"2012-01-13
THANKS! 
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Ivan,
You are printing a dictionary as a string. You could do something like this:
flds = ['TipoValore', 'Data', 'Valore'] print ",".join(flds) for i in precip: lst = [] for fld in flds: lst.append(i[fld]) print ",".join(lst)
Which will yield this:
TipoValore,Data,Valore @,2012-01-01 09:00:00, @,2012-01-02 09:00:00, @,2012-01-03 09:00:00, @,2012-01-04 09:00:00, ... P,2016-01-03 09:00:00,22.0 P,2016-01-04 09:00:00,3.0 P,2016-01-05 09:00:00,3.2 P,2016-01-06 09:00:00,3.8 P,2016-01-07 09:00:00,3.2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Ivan,
You are printing a dictionary as a string. You could do something like this:
flds = ['TipoValore', 'Data', 'Valore'] print ",".join(flds) for i in precip: lst = [] for fld in flds: lst.append(i[fld]) print ",".join(lst)
Which will yield this:
TipoValore,Data,Valore @,2012-01-01 09:00:00, @,2012-01-02 09:00:00, @,2012-01-03 09:00:00, @,2012-01-04 09:00:00, ... P,2016-01-03 09:00:00,22.0 P,2016-01-04 09:00:00,3.0 P,2016-01-05 09:00:00,3.2 P,2016-01-06 09:00:00,3.8 P,2016-01-07 09:00:00,3.2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander,
I solved my problem in this inelegant way:
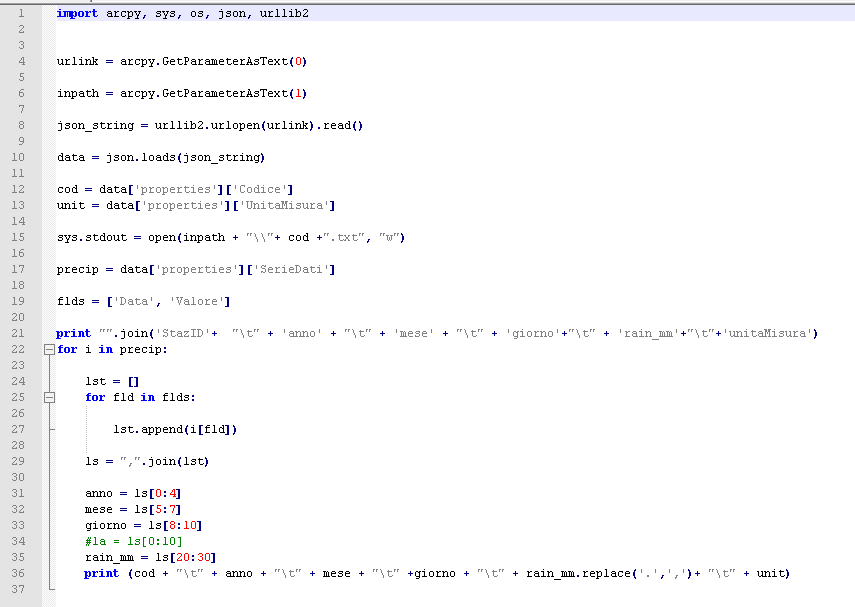
This is the final model builder, that save rainfall data for each gauge station in a txt file.
This is the output txt file:

So I merged all txt files and I used "Make query table" to join rainfall data to gauge station shapefile using as key the field StazID. The query: met.StazID = staz.CODICE

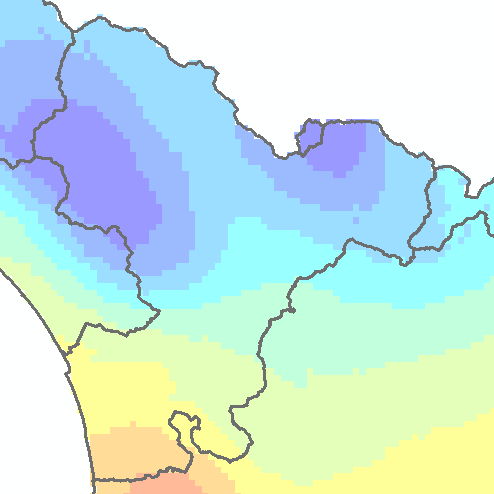
And this is an example of interpolated map of cumulative rainfall for year 2003 (using kriging):
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Ivan, I'm glad you resolved it, but I would strongly suggest using the key (fieldname) to retrieve a value from a dictionary over slicing it as text. Slicing text will require that the data always has the same length. Which might be the case in your project, but often it is not the case.