- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Need arcpy.SearchCursor to return full row value
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Need arcpy.SearchCursor to return full row value
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a table in a geodatabase that includes an attribute field type Double called lab_calib_chlorophyll.
Scrolling through the table in ArcMap, I see values which contain anywhere from 2 to 6 decimal places with the default numeric property setting (of 6 decimal places).
When I change the numeric properties of the column to show up to 15 decimal places, some of the values in the table extend out, and others don't (presumably because a given value does not contain that many decimal places).
Still in ArcMap, I then use Select by Attributes and construct a SQL statement. I populate the value using the "Get Unique Values" button. I then scroll through the list that results and find the unique value I want which appears in the unique values list as 26.427265000000006 even though when looking at the table itself this only shows up as 26.427265 (even when the properties are set to show 15 decimal places).
The trouble is that I need to use arcpy.da.SeachCursor(table,"*") to build an SQL expression.
The search cursor for a specific row is returning the 26.427265 and not the "true" 26.427265000000006, therefore the expression that is built does not return a selected record.
How can I get the search cursor to return the complete value that is "really" in the table row so that my SQL expression becomes lab_calib_chlorophyll = 26.427265000000006
and not
lab_calib_chlorophyll = 26.427265
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Lynn,
Without going into a full discussion into precision/scale and number types for ArcGIS...I would add a format function to your cursor variable for that field. I created a test table and added your value as a Field Type Double.
I ran a search cursor on my test table.
If I print the entire row:
for row in cursor:
print row
(1, 26.427265000000006, (-75.24637681199994, 72.53623188400007))However if I print just my second field's value:
for row in cursor:
print row[1]
26.427265If you try:
for row in cursor:
print format(row[1], '.15f') # give 15 digits after the point
26.427265000000006 Great resource:
15. Floating Point Arithmetic: Issues and Limitations — Python 3.5.2 documentation
Probably the quickest way to return the values you need.
Hope this helps!
~Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am going to forgo my comments, at least for now, on "really" and "true." Before I dive into the mechanics, what version of ArcMap/ArcCatalog are you running?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you - I am running 10.4.1
Alexander Brown's method to add a format function worked so I am all set.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
But still...
I think it is unwise to be using a select or unique classify on a attribute which is double. There must be a better way to identify the row you need.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There probably is but as a python newbie I could not figure it out. Would love any advice that would make it more efficient if anyone has a moment. And maybe there is even an existing GP tool that I am overlooking.
I have several hundred tables. Each table represents measurements recorded on a specific date.
Each row in a given table represents a measurement of chlorophyll at a specific monitoring station (Station) and depth (negdepth_m). Station repeats itself. Here is a snapshot of one of my tables:
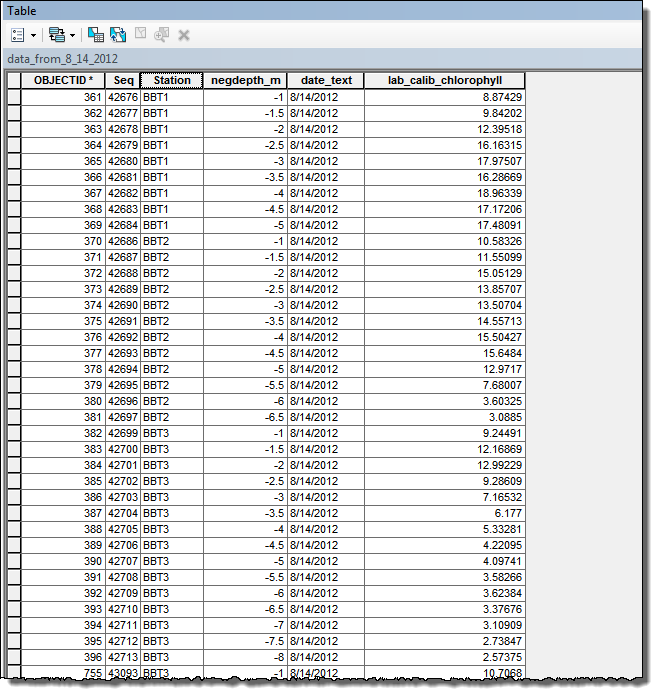
For each table, I need to determine the Maximum Chlorophyll that occurs at any given Station.
I found this is easy to accomplish using arcpy.Statistics_analysis with Station as the Case Field.
arcpy.Statistics_analysis(in_table, out_table, statistics_fields="lab_calib_chlorophyll MAX", case_field="Station")
However, for each Max Chlorophyll value for each Station, I also need to retain and write out the negdepth_m at which that Maximum lab_calib_chlorophyll value was measured.
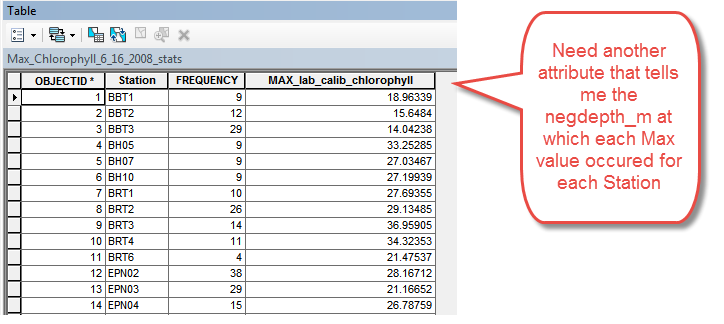
Perhaps the Statisitcs_analysis tool is somehow tracking the other fields present as it finds the MAX, but I could not find a way to expose and write out the corresponding negdepth_m.
So I resorted to generating an expression using a search cursor: eg
Station = BBT1 and MAX_lab_calib_chlorophyll = 18.96339
which would then select and tag the matching record back in the original table (maxtag = y).
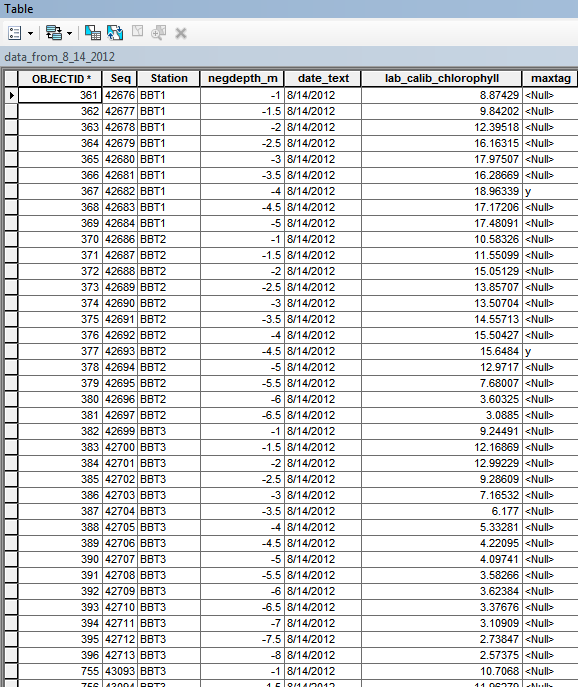
This is where I ran into trouble because in many cases MAX_lab_chlorophyll had 15 digits after the decimal 18.963390000000006 so the expression did not result in a selected record.
Thank you for any techniques that would make this easier if you have a moment to explain.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You could use a bit of python to get the ID (your identifer or OID@)
My dummy table of data.

flds = ["ID", "Station", "ChloroVal", "SelFlag"]
# read the data into a dict containing a list
data_dict = {}
with arcpy.da.SearchCursor(tbl, flds) as inCur:
for row in inCur:
ID = row[0]
station = row[1]
val = row[2]
data = [val, ID]
if station in data_dict:
data_dict[station].append(data)
else:
data_dict[station] = [data]data_dict looks like this :
{u'B1': [[5.4, 1], [3.4, 2], [6.4, 3], [5.0, 4]],
u'B2': [[3.2, 5], [5.2, 6], [5.0, 7], [7.0, 8]]}
then you read through this dict and sort each list.
# process the dict to get the ID where Val is max, just sort each one
for k, v in data_dict.items():
v = sorted(v)
data_dict[k] = vThe sorted list looks like this :
{u'B1': [[3.4, 2], [5.0, 4], [5.4, 1], [6.4, 3]],
u'B2': [[3.2, 5], [5.0, 7], [5.2, 6], [7.0, 8]]}
now all you need is the ID associated with the last member of the list.
updateList = []
for k, v in data_dict.items():
# pick the last one in each list
updateList.append(v[-1][1])Then with updateList, open up an update cursor and set the selectFlag.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Mr. Ayres,
Thank you so very much for putting this together. I am not too familiar with data dictionaries yet, so this will be a great way for me to learn about them.
I am going to study this code and make sure I understand how it is working. I expect it will be applicable to future applications as well and I really appreciate your taking the time to help me.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
No probs. Good luck. Happy pythoning.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Lynn,
Without going into a full discussion into precision/scale and number types for ArcGIS...I would add a format function to your cursor variable for that field. I created a test table and added your value as a Field Type Double.
I ran a search cursor on my test table.
If I print the entire row:
for row in cursor:
print row
(1, 26.427265000000006, (-75.24637681199994, 72.53623188400007))However if I print just my second field's value:
for row in cursor:
print row[1]
26.427265If you try:
for row in cursor:
print format(row[1], '.15f') # give 15 digits after the point
26.427265000000006 Great resource:
15. Floating Point Arithmetic: Issues and Limitations — Python 3.5.2 documentation
Probably the quickest way to return the values you need.
Hope this helps!
~Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you so much - this worked perfectly! And very helpful to have the reference to the documentation.