- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Iterate through rows and write new fields based on...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Iterate through rows and write new fields based on a criteria matched with reference table
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
I am trying to iterate through rows in a attribute table( named here :target_table) and look for certain search criteria based on a reference_table.csv. Search criteria is a set of numbers (see below), if criteria is met then I would like to add new fields in target_table and write with values based on the reference_table.
reference_table:
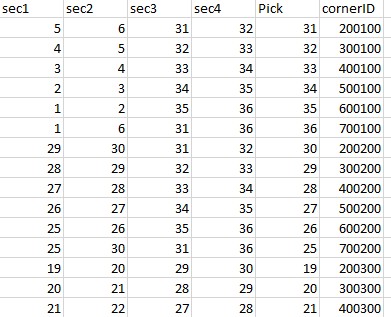
Columns: sec1,sec2,sec3 and sec4 are used as a criteria to search in target_table rows (see below). Example, in the first row: 5,6,31,32(order is not an issue), if this combination of numbers matches while scanning through first 4 rows in the target_table then "Pick" and "cornderID" column will be added into target_table with their values 31 and 200100 respectively.
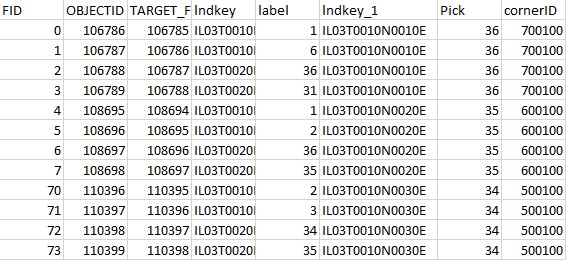
target_table:

This is a shape attribute table where script will scan trough column "label" then look for the first 4 rows( moving downward) and search for criteria(as mention above) and add new fields "Pick" and "cornerID" with their values . Example, the first 4 rows combination under field "label" is 1,6,36,31, so based on the search criteria from the reference_table, it should write Pick is 36 and cornerId is 700100. Below is what would final attribute table would look like;
Final:
Any suggestion with arcpy scripting and tools will be greatly appreciated !
Thanks !
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I changed the code a bit (it was assuming the label to be as second column), but I noticed that there are a lot of combinations that do not exist in the reference table (2358 out of 3410).

Changed code (files on lines 4 and 5, indexes on line 61 and 64):
import csv
def main():
ref = r"D:\Xander\GeoNet\CSVreftarg\referenceALL_table.csv"
tar = r"D:\Xander\GeoNet\CSVreftarg\targetSubset_table.csv"
# fill dictionaries
dct_ref = createRefDict(ref)
dct_tar, dct_data = createTarDict(tar)
# read data and enrich
for fid, vals in dct_data.items():
if fid in dct_tar:
key = dct_tar[fid]
if key in dct_ref:
lst = dct_ref[key]
vals.extend(lst)
dct_data[fid] = vals
# check result:
for fid, vals in sorted(dct_data.items()):
print "{0},{1}".format(fid, ",".join(str(a) for a in vals))
def createRefDict(ref):
# create dict with key is list of value
# and value is list of return values
# sec1,sec2,sec3,sec4,Pick,cornerID
dct = {}
with open(ref, 'rb') as f:
reader = csv.reader(f)
cnt = 0
for row in reader:
cnt += 1
if cnt == 1:
pass # header
else:
key = generateKey(row[:4])
dct[key] = row[4:]
return dct
def createTarDict(tar):
# read 4 records and compose label list,
# insert this list for every FID
# FID,OBJECTID,Join_Count,TARGET_FID,lndkey,label,lndkey_1
dct = {}
lst_fid = []
lst_lbl = []
dct_data = {}
with open(tar, 'rb') as f:
reader = csv.reader(f)
cnt = 0
for row in reader:
cnt += 1
if cnt > 1:
dct_data[row[0]] = row[1:]
if (cnt-2) % 4 == 0:
key = generateKey(lst_lbl)
for fid in lst_fid:
dct[fid] = key
lst_fid = [row[0]]
lst_lbl = [row[5]] # was row[1]
else:
fid = row[0]
lbl = row[5] # was row[1]
lst_fid.append(fid)
lst_lbl.append(lbl)
# add last sequence
key = generateKey(lst_lbl)
for fid in lst_fid:
dct[fid] = key
return dct, dct_data
def generateKey(lst):
lst2 = sorted([int(a) for a in lst])
return ",".join(([str(a) for a in lst2]))
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Yam,
I would suggest using cursors to iterate through your tables, check values and update them. Richard Fairhurst has an excellent blog post about using cursors and dictionaries to update or add field values Turbo Charging Data Manipulation with Python Cursors and Dictionaries. I suggest you take a look at it and see if it can be applied for your needs.
Regards,
Ian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
And to show how this would look in Python code (based on the attached csv files):
import csv
def main():
ref = r"D:\Xander\GeoNet\CSVreftarg\reference_table.csv"
tar = r"D:\Xander\GeoNet\CSVreftarg\target_table.csv"
# fill dictionaries
dct_ref = createRefDict(ref)
dct_tar, dct_data = createTarDict(tar)
# read data and enrich
for fid, vals in dct_data.items():
if fid in dct_tar:
key = dct_tar[fid]
if key in dct_ref:
lst = dct_ref[key]
vals.extend(lst)
dct_data[fid] = vals
# check result:
for fid, vals in sorted(dct_data.items()):
print "{0},{1}".format(fid, ",".join(str(a) for a in vals))
def createRefDict(ref):
# create dict with key is list of value
# and value is list of return values
# sec1,sec2,sec3,sec4,Pick,cornerID
dct = {}
with open(ref, 'rb') as f:
reader = csv.reader(f)
cnt = 0
for row in reader:
cnt += 1
if cnt == 1:
pass # header
else:
key = generateKey(row[:4])
dct[key] = row[4:]
return dct
def createTarDict(tar):
# read 4 records and compose label list,
# insert this list for every FID
dct = {}
lst_fid = []
lst_lbl = []
dct_data = {}
with open(tar, 'rb') as f:
reader = csv.reader(f)
cnt = 0
for row in reader:
cnt += 1
if cnt > 1:
dct_data[row[0]] = row[1:]
if (cnt-2) % 4 == 0:
key = generateKey(lst_lbl)
for fid in lst_fid:
dct[fid] = key
lst_fid = [row[0]]
lst_lbl = [row[1]]
else:
fid = row[0]
lbl = row[1]
lst_fid.append(fid)
lst_lbl.append(lbl)
# add last sequence
key = generateKey(lst_lbl)
for fid in lst_fid:
dct[fid] = key
return dct, dct_data
def generateKey(lst):
lst2 = sorted([int(a) for a in lst])
return ",".join(([str(a) for a in lst2]))
if __name__ == '__main__':
main()This will print (fid, label, pick, cornerID)
0,1,36,700100 1,6,36,700100 2,36,36,700100 3,31,36,700100 4,1,35,600100 5,2,35,600100 6,36,35,600100 7,35,35,600100 70,2,34,500100 71,3,34,500100 72,34,34,500100 73,35,34,500100
The content of the dct_ref (reference) dictionary is (key is a sorted comma separated list of labels and the value is a list with the values you want to join):
{'5,6,31,32': ['31', '200100'], '2,3,34,35': ['34', '500100'], '1,6,31,36': ['36', '700100'], '4,5,32,33': ['32', '300100'], '3,4,33,34': ['33', '400100'], '29,30,31,32': ['30', '200200'], '1,2,35,36': ['35', '600100'], '27,28,33,34': ['28', '400200'], '28,29,32,33': ['29', '300200']}The content of the dct_tar (target) dictionary is the fid with the list of 4 labels:
{'71': '2,3,34,35', '70': '2,3,34,35', '1': '1,6,31,36', '0': '1,6,31,36', '3': '1,6,31,36', '2': '1,6,31,36', '5': '1,2,35,36', '4': '1,2,35,36', '7': '1,2,35,36', '6': '1,2,35,36', '73': '2,3,34,35', '72': '2,3,34,35'}The content of the dct_data (data dictionary is the data from the target):
{'71': ['3'], '70': ['2'], '1': ['6'], '0': ['1'], '3': ['31'], '2': ['36'], '5': ['2'], '4': ['1'], '7': ['35'], '6': ['36'], '73': ['35'], '72': ['34']}Just to give you an idea...
Kind regards, Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander,
Thanks for your response and the code. It seems working fine with a test datasets though I wanted to write output file in either in the target_table or in seperate .csv file. But some reason it do not print right output for full dataset . I wonder if that is the case due to duplication of row combination in the target_table ?.
I do not see option to attach tables here.
Thanks !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In order to attach documents you need to use the advanced editor. There is a link in the upper right corner:

... to activate the advanced editor. However, this will only be available if you open the link of the discussion (the link is not available in your inbox). Once you are in the advanced editor in the lower right corner you will see the link to attach files:

I haven't tested the code to use the more fields, nor have I written the result to a csv file or other format. To do that it would be good if you could provide sample file to see what is possible.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I changed the code a bit (it was assuming the label to be as second column), but I noticed that there are a lot of combinations that do not exist in the reference table (2358 out of 3410).
Changed code (files on lines 4 and 5, indexes on line 61 and 64):
import csv
def main():
ref = r"D:\Xander\GeoNet\CSVreftarg\referenceALL_table.csv"
tar = r"D:\Xander\GeoNet\CSVreftarg\targetSubset_table.csv"
# fill dictionaries
dct_ref = createRefDict(ref)
dct_tar, dct_data = createTarDict(tar)
# read data and enrich
for fid, vals in dct_data.items():
if fid in dct_tar:
key = dct_tar[fid]
if key in dct_ref:
lst = dct_ref[key]
vals.extend(lst)
dct_data[fid] = vals
# check result:
for fid, vals in sorted(dct_data.items()):
print "{0},{1}".format(fid, ",".join(str(a) for a in vals))
def createRefDict(ref):
# create dict with key is list of value
# and value is list of return values
# sec1,sec2,sec3,sec4,Pick,cornerID
dct = {}
with open(ref, 'rb') as f:
reader = csv.reader(f)
cnt = 0
for row in reader:
cnt += 1
if cnt == 1:
pass # header
else:
key = generateKey(row[:4])
dct[key] = row[4:]
return dct
def createTarDict(tar):
# read 4 records and compose label list,
# insert this list for every FID
# FID,OBJECTID,Join_Count,TARGET_FID,lndkey,label,lndkey_1
dct = {}
lst_fid = []
lst_lbl = []
dct_data = {}
with open(tar, 'rb') as f:
reader = csv.reader(f)
cnt = 0
for row in reader:
cnt += 1
if cnt > 1:
dct_data[row[0]] = row[1:]
if (cnt-2) % 4 == 0:
key = generateKey(lst_lbl)
for fid in lst_fid:
dct[fid] = key
lst_fid = [row[0]]
lst_lbl = [row[5]] # was row[1]
else:
fid = row[0]
lbl = row[5] # was row[1]
lst_fid.append(fid)
lst_lbl.append(lbl)
# add last sequence
key = generateKey(lst_lbl)
for fid in lst_fid:
dct[fid] = key
return dct, dct_data
def generateKey(lst):
lst2 = sorted([int(a) for a in lst])
return ",".join(([str(a) for a in lst2]))
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander,
The code seems to be working. I think I need to clean my data before feed into the code.
Thank you so much!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You're welcome!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Ian ! I will look into the post you suggested.