- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Iterate Based on Unique Feature Name
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Iterate Based on Unique Feature Name
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi.
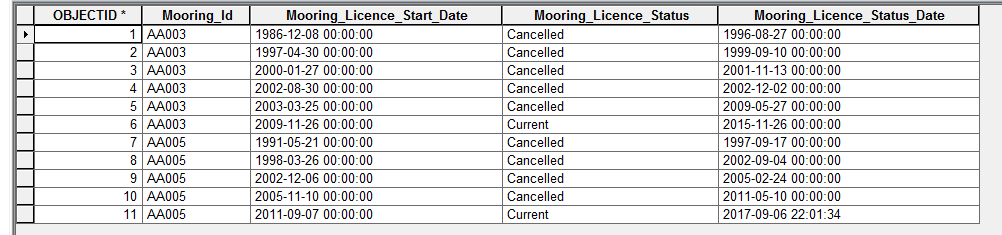
Shown below is a subset of my data. How do I iterate through based on the mooring ID? What I want to happen is do something for mooring ID AA003 then skip to mooring ID AA005 and do the process again. I am aware of search cursors but this processes each row. In this example I want the process to run twice, not each time for the 11 records.
What I am ultimately wanting to do is nest my process within what I am trying to do above. That is, grab the first of the series of mooring IDs, run the nested process, then move on to the first of the next series of mooring IDs and run the nested process again.
I have tried to create a separate list without success. I have tried to use arcpy Statistical analysis but this resulted in a table with a single record detailing the number of occurrences of the mooring ID (in this case AA003). Is there a way of creating a summary table of mooring_Id.First? This would give me a list of unique mooring ID's (in this case; AA003, AA005). Though this may be one way of doing it I would prefer just to run the process for the first of each mooring IDs.
Regards,
Dave.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I would probably make 2 dictionaries.
The first is the entire table with the OID as the key.
The second would hold only that first occurrences of MooringID (key) and keep the OID as its data.
Something like this :
dict_tabledata = {}
dict_mooringID = {}
with arcpy.da.SearchCursor(table, ["OID@", "Mooring_Id", "other data columns"] as Cur:
for row in Cur:
oid = row[0]
mID = row[1]
dict_tabledata[oid] = row[1:]
if not mID in dict_mooringID:
dict_mooringID[mID] = oidThen you can loop through the dict_mooringID to get the oid in the main table and do what you need to do
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Neils solution will provide two dictionaries whereas the second dictionary "dict_mooringID" will hold the first oid for each Mooring_Id. Please note that the code snippet is missing a closing bracket on line 3 (just before " as Curs")
To decide on what option fits your needs best, it would be necessary to know more about the processing you would like to carry out on each set of records with the same Mooring_Id. Below a simple example how you can get a list with unique Mooring_Ids:
tbl = r'path to your table'
fld_mooring = 'Mooring_Id'
mooring_ids = list(set([r[0] for r in arcpy.da.SearchCursor(tbl, (fld_mooring))]))Based on the code provided by Neil, you could do something like this:
for mooring_id in mooring_ids:
lst_data = [lst for oid, lst in dict_tabledata.items() if mooring_id == lst[0]]
for data_item in lst_data:
# do somethingThis will create a list of data items for each Mooring_Id and will allow you to process the data. However, this highly depends on how you want to process the set of data for each Mooring_id.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The details of what you would do when they were split by the mooring_id field is of consequence...
Perhaps, you might want to consider just using....
Split By Attributes—Help | ArcGIS Desktop
And when you that is done you can process them as you see fit.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As Dan points out, it is difficult to provide specific suggestions without a bit more information on what processing is going to be done on each group of records. That said, itertools.groupby was created to handle this kind of situation. Something along the lines of the following should get you close, I think:
from itertools import groupby
tbl = # path to feature class or table
fields = [
"OBJECTID",
"Mooring_id",
"Mooring_License_Start_Date",
"Mooring_License_Status",
"Mooring_License_Status_Date"
]
sort_fields = ["Mooring_id", "OBJECTID"] # OBJECTID can be excluded if not needed for ordering records
group_field = "Mooring_id"
sql_postfix = "ORDER BY " + ", ".join(sort_fields)
with arcpy.da.SearchCursor(tbl, fields, sql_clause=(None, sql_postfix)) as cur:
for k, g in groupby(cur, lambda x: x[fields.index(group_field)]):
for i in g:
# run process- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks all for your replies. Unfortunately I cannot get my head around python groupby - though I have an understanding of what it is attempting to do. To clarify things I have added my extra code below. What I am wanting to do is compare the licence start date of the last cancelled licence with the start date of the current licence for each mooring ID. I have found there are data errors in our licencing database. Some moorings have a cancelled licence with a more recent start date than that of the current licence. The print component at the end will be replaced with a statement to output to a list the mooring IDs with a cancelled licence start date that is more recent than that of the current licence. Apologies for my crude scripting as I am very much a novice at this.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just checked with a date field in a feature class. When you read it in using arcpy.da.SearchCursor it looks like a datetime.datetime style date/time.
ie it looks like this :
>>> n1 = datetime.datetime.now()
>>> n1
datetime.datetime(2018, 9, 12, 13, 49, 33, 458000)And you can compare these directly.
So, lets go with 1 dict for the whole table with fields of oid, mooringId, startdate, status
Use Joshuas idea of constructing a dict with a list of oids per mooringId.
See example below. I am sure the other contributors can think of some more elegant way.
dict_tabledata = {}
dict_mooringID = {}
flds = ["OID@", "Mooring_Id", "Mooring_Licence_Start_Date", \
"Mooring_Licence_Status"]
# read the data into 2 dicts
with arcpy.da.SearchCursor(table, flds) as Cur:
for row in Cur:
oid = row[0]
mID = row[1]
dict_tabledata[oid] = row[1:]
if not mID in dict_mooringID:
dict_mooringID[mID] = [oid]
else:
dict_mooringID[mID].append(oid)
# get a dict of licences which are status = Current
dict_current = {}
for mID, oidList in dict_mooringID.items():
for oid in oidList:
status = dict_tabledata[oid][2]
if status == "Current":
dict_current[mID] = oid
# process the dicts to compare dates
for mID, currentOid in dict_current.items():
currentdate = dict_tabledata[currentOid][1]
for mooringID, oidList in dict_mooringID.items():
# if this oid is not the current one,
# check dates
for oid in oidList:
mooringDate = dict_tabledata[oid][1]
if oid != currentOid:
if mooringDate > currentDate:
print "Mooring {} Oid {} older than {}".format(
mooringID, currentOid, oid)