- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- How to extract certain values from a table?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello everyone! I am trying to write a python script to extract certain values from a table: the table I am referring to is a big collection of nitrate values for different water depths, which are deposited in the columns of the table. As I only need the value of the surface and the deepest point, I want to search through the rows and extract the last value that is not 0. I have started writing a script using the SearchCursor Tool but get stuck at the point, where I want it to search for the first 0-value and then go back and print the value fro mthe column before... Does anyone have an idea how to solve that problem? Thanks a lot in advance! Teresa
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Wow, that's a pretty cool dataset.
The text file didn't have a proper header so it requires a bit more manipulation. If the header was just a single row with column names, it would be easier.
The code below converts the input text file into a feature class with only the surface nitrate, the deepest non-zero nitrate, and the depth of the deepest non-zero nitrate value.
Everything including the resulting shapefile is in the attached folder. Hopefully the comments in the code will help you understand what it does. A good way to play with it is to run it row by row (block by block) in something like PyScripter
import arcpy
import os
csv = r'C:\Nitrate_GridP_Annual\Nitrate_GridP_Annual.csv'
out_fc = r'C:\Nitrate_GridP_Annual\ni.shp'
# read the csv into memeory
rows = []
with open(csv, 'r') as f:
for row in f:
rows.append(row.strip())
# The first two rows are not very useful so let's drop them
rows.pop(0) # drop the first row
depths = rows.pop(0) # drop the second row, which is now the first one
depths = map(int, depths[depths.find(':')+1:].split(','))
# Get lat, lon, Nitrate near the surface, and last non-zero measurement
newrows = []
for row in rows:
rowdata = map(float, row.split(','))
lat, lon = rowdata[0], rowdata[1]
nitrate = rowdata[2:]
n_near_surface = nitrate.pop(0) # first is near the surface
# get the deepest non-zero value and its depth
n_deepest = 0.0
depth = 0
i = 0
for i in range(len(nitrate)):
n = nitrate
if n > 0:
n_deepest = n
d = depths[i+1]
newrow = [lat, lon, n_near_surface, n_deepest, d]
newrows.append(newrow)
# write output to feature class
out_path, out_name = os.path.split(out_fc)
sr = arcpy.SpatialReference(4326) # define coordinate system (WGS84)
fc = arcpy.management.CreateFeatureclass(out_path, out_name, "POINT", spatial_reference=sr).getOutput(0)
arcpy.management.AddField(fc, "N_0", "DOUBLE")
arcpy.management.AddField(fc, "N_DEEP", "DOUBLE")
arcpy.management.AddField(fc, "DEPTH", "DOUBLE")
with arcpy.da.InsertCursor(fc, ["SHAPE@", "N_0", "N_DEEP", "DEPTH"]) as ic:
for row in newrows:
pt = arcpy.Point(row[1], row[0]) # remember that lon is x, lat is y
newrow = [pt, row[2], row[3], row[4]]
ic.insertRow(newrow)
del row
del ic
print fc
Please check that the outputs are correct! I rushed a bit while writing this.
Hope this helps,
Filip.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
You might be able to do what you need with SummaryStatistics_analysis, but SearchCursor might be easier.
However, from your description I am not entirely sure how do you imagine your result. Can you paste some code you have in here? Or show us how the table looks exactly?
(when pasting code, use the advanced editor and apply syntax highlighting on the code '>> -> Syntax Highlighting -> python')
I am guessing you can get what you are after if you use the sql_clause parameter of the SearchCursor to order your rows.
Cheers,
Filip.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
And this is the Code so far... As I am new to Python I was only able to start with the basic things, I know this is missing the main part 
import arcpy
# Set the Workspace
arcpy.env.workspace = "D:\Teresa\Kerstin\SouthernOcean\03_workspace\Teresa"
# Make table
table = "C:/Users/theidema/Desktop/OxzUti_GridP_Annual.csv"
#Create the search cursor
cursor = arcpy.SearchCursor(Table)
#Iterate through the rows
row = cursor.next()
if row.isNull (field.name):
print (row.getValue(field.name))
row = cursor.next()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Frauke,
Hope this is what you wanted. As you can see I have saved your csv file as an excel spreadsheet. Below are the assumptions for the code.
You excel columns are structured as below.
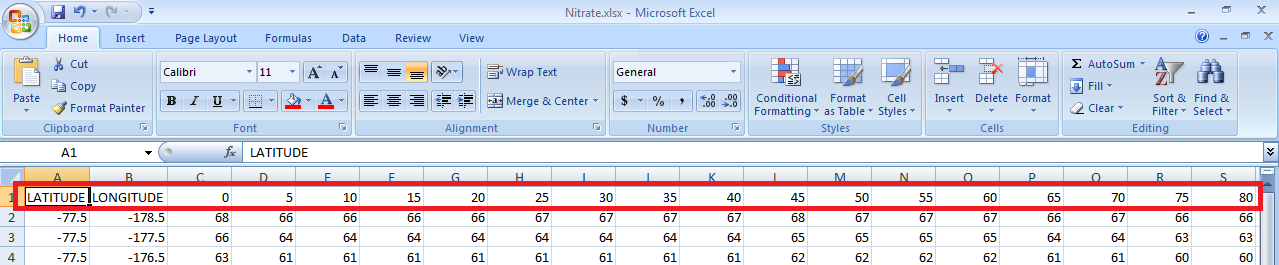
Once a column ceases to have data, no further columns will have data.
import arcpy
import os
import arcgisscripting
gp = arcgisscripting.create()
def Message(sMsg):
print sMsg
gp.AddMessage(sMsg)
# Define the feature class
table = "C:\Users\deenr\Desktop\Nitrate.xlsx\Sheet1$"
fields = arcpy.ListFields(table)
fieldCnt = len(fields)
with arcpy.da.SearchCursor(table, ("*")) as cursor:
for row in cursor:
msg = ""
cellNonEmpty = ""
idx = 0
for cell in row:
if idx == 0:
msg += "Latitude:" + str(cell)
elif idx == 1:
msg += " Longitude:" + str(cell)
elif fields[idx].name == "0":
msg += " Measure at surface is " + str(cell)
elif cell is None:
msg += " Measure at Depth " + fields[idx - 1].name + " is " + str(cellNonEmpty)
break;
elif idx == fieldCnt - 1:
msg += " Measure at Depth " + fields[idx].name + " is " + str(cell)
cellNonEmpty = cell
idx += 1
Message(msg)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hey Riyas, i somehow didnt see your comment before! Thank you so much, its working!!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Wow, that's a pretty cool dataset.
The text file didn't have a proper header so it requires a bit more manipulation. If the header was just a single row with column names, it would be easier.
The code below converts the input text file into a feature class with only the surface nitrate, the deepest non-zero nitrate, and the depth of the deepest non-zero nitrate value.
Everything including the resulting shapefile is in the attached folder. Hopefully the comments in the code will help you understand what it does. A good way to play with it is to run it row by row (block by block) in something like PyScripter
import arcpy
import os
csv = r'C:\Nitrate_GridP_Annual\Nitrate_GridP_Annual.csv'
out_fc = r'C:\Nitrate_GridP_Annual\ni.shp'
# read the csv into memeory
rows = []
with open(csv, 'r') as f:
for row in f:
rows.append(row.strip())
# The first two rows are not very useful so let's drop them
rows.pop(0) # drop the first row
depths = rows.pop(0) # drop the second row, which is now the first one
depths = map(int, depths[depths.find(':')+1:].split(','))
# Get lat, lon, Nitrate near the surface, and last non-zero measurement
newrows = []
for row in rows:
rowdata = map(float, row.split(','))
lat, lon = rowdata[0], rowdata[1]
nitrate = rowdata[2:]
n_near_surface = nitrate.pop(0) # first is near the surface
# get the deepest non-zero value and its depth
n_deepest = 0.0
depth = 0
i = 0
for i in range(len(nitrate)):
n = nitrate
if n > 0:
n_deepest = n
d = depths[i+1]
newrow = [lat, lon, n_near_surface, n_deepest, d]
newrows.append(newrow)
# write output to feature class
out_path, out_name = os.path.split(out_fc)
sr = arcpy.SpatialReference(4326) # define coordinate system (WGS84)
fc = arcpy.management.CreateFeatureclass(out_path, out_name, "POINT", spatial_reference=sr).getOutput(0)
arcpy.management.AddField(fc, "N_0", "DOUBLE")
arcpy.management.AddField(fc, "N_DEEP", "DOUBLE")
arcpy.management.AddField(fc, "DEPTH", "DOUBLE")
with arcpy.da.InsertCursor(fc, ["SHAPE@", "N_0", "N_DEEP", "DEPTH"]) as ic:
for row in newrows:
pt = arcpy.Point(row[1], row[0]) # remember that lon is x, lat is y
newrow = [pt, row[2], row[3], row[4]]
ic.insertRow(newrow)
del row
del ic
print fc
Please check that the outputs are correct! I rushed a bit while writing this.
Hope this helps,
Filip.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you so much Filip!!!!
It is working perfectly, thats awesome!
I cant tell you how happy that makes me!
Have a great day, Teresa
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You may want to look at SQL_Clause of ArcGIS Help 10.1.
Set your where clause to depth > 0 and order by depth ASC. First row would be the data that is not zero. (Tweak it depending on your data)
import arcpy
import os
import arcgisscripting
gp = arcgisscripting.create()
def Message(sMsg):
print sMsg
gp.AddMessage(sMsg)
# Define the feature class
fc = str(sys.argv[1])
with arcpy.da.SearchCursor(fc, ("ORIG_FID", "OBJECTID"),
"OBJECTID < 10",
"",
False,
("TOP 1", "ORDER BY OBJECTID DESC")) as cursor:
for row in cursor:
Message(row[1])