- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- How to ensure a script recognizes field values tha...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to ensure a script recognizes field values that have already been treated in a previous row?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
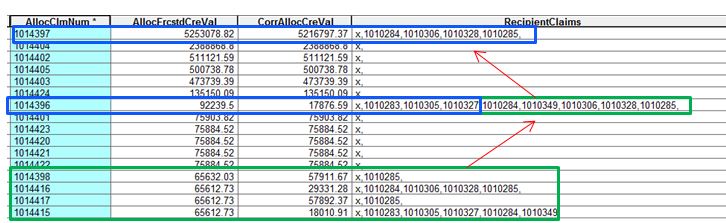
How do I ensure the script recognizes field values that have already been “used” in a previous row (not necessarily the one just above it)? Below is my source table – the result of a spatial join between two feature classes (equivalent to a land parcel). I have multiple “allocation claim numbers” (AllocClmNum, 1st field) with their respective “recipient credit values” (RecClmNum, 2nd field) associated to one “recipient claim number (RecClmNum, 3rd field) and its credit value (RecCredValReal, 4th field). The script I have subtracts funds from the allocation credit value ( AllocCreVal) stored in a dictionary (thank you Richard Fairehurst) from each RecCreClmNum so that the RecCredValReal value becomes zero, and does so until the AllocCreVal reaches a value at or above 15000. The result is stored in a new table (second one below). In this way the script uses result of the previous the AllocCreVal subtraction and applies it to the next row. The output is shown in the second table : the RecClmNum values to which the script was applied are in the field RecipientClaims. This part works fine (see second table).
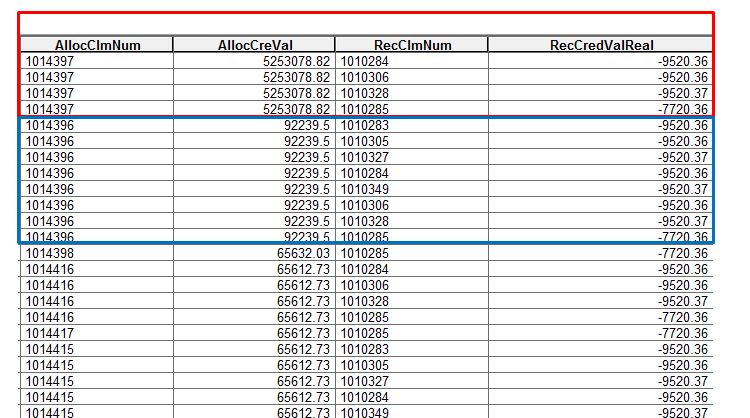
The problem is that the script runs regardless of whether the RecClmNum has already been allocated or not
. What I can’t solve is how to NOT include those RecClmNum rows that have already had an allocation applied to them (those highlighted in the green squares). There are about 10000 of these records to go through.
The values in green below should not have been calculated since they were already done using the previous AllocClmNum values.
# set your variables for the Allocation Claims feature class
updateFC_AllocClms = "SortedAllocationClaims"
fields_AllocClms = ["AllocClmNum","CorrAllocCreVal","RecipientClaims"]
# set your variables for the feature class with the joined Allocation Claims and Recipient Claims (spatial)
sourceFC_AllocClmsSpj = "AllocationClaimsSPJ"
fields_AllocClmsSpj = ["OBJECTID","AllocClmNum","RecClmNum","RecCreVal","AllocStatus"]
# set the dictionary variables
Dict_AllocClmsSpj = {}
# alternative dictionary with "false" values
# source: Richard Fairhurst
with arcpy.da.SearchCursor(sourceFC_AllocClmsSpj,fields_AllocClmsSpj) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[1]
if not keyValue in Dict_AllocClmsSpj:
lstRow = list(searchRow[1:])
lstRow.append(False)
# assign a new keyValue entry to the dictionary storing a list
Dict_AllocClmsSpj[keyValue] = [lstRow]
else:
lstRow = list(searchRow[1:])
lstRow.append(False)
# dictionary keyValue exists so append to the list
Dict_AllocClmsSpj[keyValue].append(lstRow)
# run the script
# update the Sorted Allocation Claims FC with the new values for Allocation Credits ("CorrAllocCreVal")
with arcpy.da.UpdateCursor(updateFC_AllocClms, fields_AllocClms) as upRows:
for upRow in upRows:
x = upRow[2]
comma = ","
KeyAllocationClaim = upRow[0] # key value is AllocClmNum
# KeyRecipientClaims = upRow[2] # value represents the recipient claim numbers
if KeyAllocationClaim in Dict_AllocClmsSpj: # if the KeyAllocationClaim is in the dictionary
for record in Dict_AllocClmsSpj[KeyAllocationClaim]:
# something like: if record[1] not in upRow[2]
# return the list of values in the field "RecipientCLaims" (upRow[2]).
# if record[1] (RecClmNum from
if record[4] == False:
if (upRow[1] - record[2]) >= 15000: # and as long as credit value is >= to 15000
upRow[1] = upRow[1] - record[2] # subtract the Allocation Credit Value from the Recipient Credit Value in the Dict_AllocClmsSpj
# append all the recipient claim numbers "record[1]" to the field "RecipientClaims" in the "SortedAllocationClaims" table separated by a comma
upRow[2] = upRow[2] + record[1] + comma
record[4] = True
upRows.updateRow(upRow)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I reread your script and see it is not a new table, but rather an new field that has not been taken into account by the script. That field or a new field needs to be processed as part of the conditional logic that determines if a claim can be deducted. If the table with the individual claims always has new claims appended to it and also will contain all previously processed claims each time you run the script you probably should add a Processed field to that detail table. Then you can process an update cursor on the detail table that would use the Flag I set up in your dictionary to write back to mark the newly processed claims in the Processed field. The new update cursor would run in a new loop after and outside of the current script loops you have set up. Anyway there are a few ways to handle the check of the previously processed claims based on your table configuration.
Anyway, can a claim number and deduction amount hit multiple lines in the table with the new field? Are you dealing with a M:M relationship between the two tables or a 1:M relationship between the claim detail sorted table and the claim deduction table? A M:M relationship greatly complicates things and may require new fields and logic to properly deal with what you want. All the code you have worked with so far assumed you are only dealing with 1:1, 1:M and M:1 logic, not M:M logic. I don't give examples of M:M logic in my Blog because the rules for processing those relationships tend to be very specific to the data being processed and it can is difficult to suggest code that works without first going through a full discussion of how those rules may apply. The complications introduced by M:M relationships make them bad examples for demonstrating the principles of using dictionaries and cursors and should only be tackled after the simpler relationship types have been understood and the alternatives involving them cannot be used.
For example, I have assumed the amount of RecClmNum 1010306 is cumulative in the top table and totals -28561.08 and has already been divided into 3 equal portions of -9520.36 for each of the three AlloCClmNums records shown, since that fits a 1:M relationship. I have not assumed that the combined total of all three Allocation/Claim records is -9520.36 and the total claim amount is not cumulative and just being duplicated three times because there are three associated Allocations, which would cause the -9250.36 amount to have a M:M relationship in the two tables. If in reality the total claim is -9520.36 then you need to tell me whether you want the script to divide that amount into 3 equal portions and deduct -3173.453... from each of the three AllocClmNums, or divide the amount and round to the nearest penny so that -3173.46 is deducted from one and -3173.45 is deducted from other two, or the full amount of -9520.36 is deducted from only the first AllocClmNum encountered and none of that amount is deducted from any of the other two AllocClmNums. Another alternative in the case of duplicated totals would be to deduct as much of the claim amount as possible while still leaving 15000 in each Allocation and continuing to do that until the full claim is processed or some portion of the claim cannot be Allocated, in which case you would have to tell me how and where you intend to track the processed and unprocessed claim portions since the division pattern cannot be predicted or reproduced without knowing the exact order of every transaction (datetime stamps come into play in real accounting software for this reason). You have to tell me what the total amount of each unique claim number is and what is to be done with each separate Allocation/Claim record to apportion that amount for the unique claim number in one of these ways (or in a way I haven't thought of) to make sure you get code suggestions that will actually do what you want.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the thorough reading of this case. I think I need to clarify what it is that is happening here. "AllocClmNum" are mining claim identifying numbers (polygons of about 40 ha each) that have had exploration costs (assumed by the mining company) associated to them. "RecClmNum" are those claims that have not had any exploration costs associated to them (hence no exploration activty). In short these dollar values are used to offset the renewal fees required by the government to keep the rights to a claim. New regulation means we can now apply some of the costs from the "AllocClmNums" to the "RecClmNum" claims if they fall within a given radius of each other (this is already factored via a spatial join). Of course this results in a table where one "AllocClmNum" has many corresponding "RecClmNum" and vice versa, hence a M to M relationship. This is what is happening in the first table above.
In row 1 ("AllocClmNum" 1014397) I want to subtract the credit value of 5253078.82 from the absolute value of -9520.36 for "RecClmNum" 1010284. In row 2 (still "AllocClmNum" 1010395)) I want to subtract the RESULT of row 1 from the absolute value of -9520.36 for "RecClmNum" 1010306. And so on. The process is repeated for the next group (blue rectangle, for AllocClmNum 1014396). BUT you will notice that some of its corresponding "RecClmNum" are the same as the ones above in the red rectangle. These are the ones that need to be skipped since they already have had a credit allocation - and this is what is not happening in the script.
I've begun to look at sets and collections as a way around this and I will let you know how that progresses too.
I hope that clarifies things a bit. You've already helped me go beyond my scope and experience with python syntax and I am very thankful for that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So in reality there should be another table that stores just one line for each Claim number, which is where the draw down should occur. The spatial join should have left the amount out of that table, since it does not get duplicated simply because it has proximity to multiple allocations. Doing it the way you have done it obscures this and makes it unnecessarily complicated to track, since now you have to track a single amount duplicated many times for no purpose. The claims being consumed would be its own dictionary and be the place where you should track the consumption of claims, not the M:M spatial join table. The Spartial Join table would track nothing and only be used to examine the possible combinations in order if they have not been eliminated by a prior transaction as recorded by the claims dictionary.
The spatial join only provides possible links, but you are only accepting the first one encountered. So in reality you are using a first value summary table with only a rare exceptional case requiring a secondary first summary table when an allocation is eliminated by prior claim values being processed. This is the result you really want, not a true set of all possible proximate combinations. In my mind the two separate tables of just claims and just allocations should be recording what really combined in the transactions you want to allow. If the spatial join table is kept, at the end only the actual transactions of the first records should be kept and all other records eliminated. Either way the table of unique claims records and the table of unique allocation records is the best place to track, validate and compare summaries of the combination table that included both needed and unneeded combinations of claims and allocations.
The claims table of unique records is especially valuable if at the end of the process most, if not all, of the claim numbers and amounts will only be associated to a single allocation and be processed on a single date, all of which is easily stored in a single record. That is the simplest representation of what I think you really are trying to track. The tables you design for this problem should contain the list of the transactions where at the end of the day they are represented in their most basic and easiest to understand form. The claims table is where I see that being done.
Your way of talking about math also seems confusing. You should want to add the positive allocation number to the negative claim value, not subtract it. Subtracting would result in a value that converts the allocation to a negative value and combine with the negative claim to make an even more negative value than either value taken separately. I doubt that is how you want the math to work.
Anyway, in consumption problems I always try to keep the consumed amount unduplicated. That usually simplifies the problem considerably over trying to work with sets of unique values that are needlessly duplicated. That is usually a bad relational design that unnecessarirlly complicates showing the user the real transactions that are taking place.
Also, if the combinations are kept I still think that date stamps are important. Shapes may change over time due to improvements in spatial accuracy or ownership changes/subdivisions, and knowing the dates when these changes occurred relative to the tranactions that have been proceeds is bound to be something that is important if at some point in the future you ever need to trace back through the transaction history. Property having only one shape, billing entity and operational status that works for all eternity just won't happen.