- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- How to create a new field with a combination based...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to create a new field with a combination based on another field with arcpy?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I like to create a new txt which has two columns: Id and GRIDCODE.
This is the original Table:
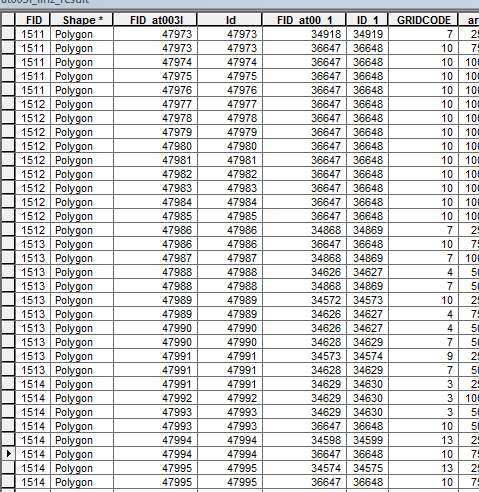
The Id column of the new txt should have just unique values. I’m able to do this with the following code. But the GRIDCODE -column of the new txt should have the possible combinations of one equal Id, for example:
The new Id field 47973 should have the new GRIDCODE field 7, 10
or the new Id field 47990 should have the new GRIDCODE field 4, 7.
To clarify the question I build an example-table with excel, this should be the result I like to write in the new txt. Do I have to work with an update cursor and if, else? What about the comma, how is it possible to use them without getting a new column but the combination in a column?
I would be very thankful to get a tip how I can go on with my code.

import arcpy
import os
from arcpy import env
env.overwriteOutput = True
env.workspace = r"D:\Users\ju\ers\cities_UA\resultfolder"
DataDict = {}
inputshp = r"D:\Users\ju\ers\cities_UA\resultfolder\innsbruckauswahl.shp"
outputfile = r"D:\Users\ju\ers\cities_UA\resultfolder\inns_test.txt"
f = open (outputfile, 'w')
f.write ("ID,Gridcode,\n")
f.close ()
#f = open (outputfile, 'a')
ID=[row[0] for row in arcpy.da.SearchCursor(inputshp, ["Id", "GRIDCODE"])]
#GRIDCODE = [row[0] for row in arcpy.da.SearchCursor(inputshp, ["GRIDCODE"])]
uniqueID = set(ID)
for ID in uniqueID:
print ID
# f.write((str(ID)) + "," + (str(GRIDCODE))+ "\n")
#f.close()
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have no problem restructuring the code, but I need an example of what the input and output would look like to understand what you are doing. The code portion you provided assumed I knew what had happened before it and I didn't. I want to adapt the code. I have already rewritten it twice to adapt it to my own data and needs with multiple fields and reduced the processing time down by 4 times. Ultimately the more I do it the more likely I can create a generic structure that can be quickly adapted to many, many problems like this.
So I am only bothered if you raise the issue and don't share the example data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ok, thank you. The problem was that I should create the combination not just for the field "GRIDCODE" because now there a tow more codes and I need also their combinations ("GRIDCODE2", "GRIDCODE3") .
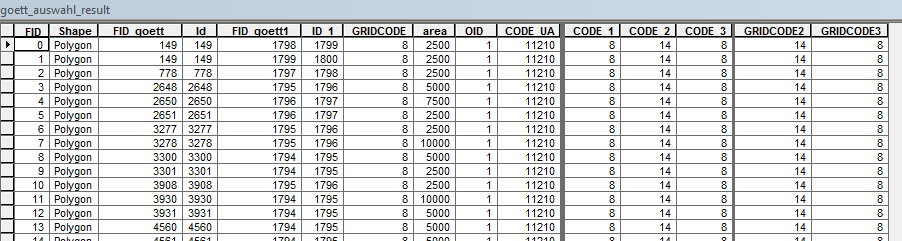
But this is not the only thing I have to do: There is the field "area" and I have to get the sum from this field for the combination and also the percent of the area for one combination. I did this basically with arcpy.Statistics_analysis and arcpy.AddJoin_management. The code is very long at the moment...
The big goal is one table (txt or csv) with the first 40 rows from each combination sorted downward including the filename in a column, the combinationname, the percent, area and the frequency (like the table below).
I will try to write the output from all tables which are in the list among each other and because of the created codenamefield and the field with the name from the original shp it is comprehensible.
The huge problem is that this is the first big thing I'm doing with arcgis and arcpy. So I guess the code is not the fasted way to the goal, but it is nearly working... The other thing making my process a little bit hard is that the purpose for my result is chancing respectively is still in discussion.
My actual problem is to get the three result tables for one round in the loop to a big one without losing the combinations.
Here is one of the result-tables which should get to the big goal:
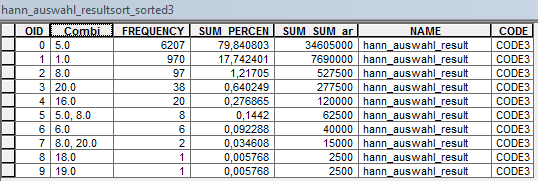
At the moment the txt produces a combi-field with the type double but I need a text-field otherwise the combination got lost like here:
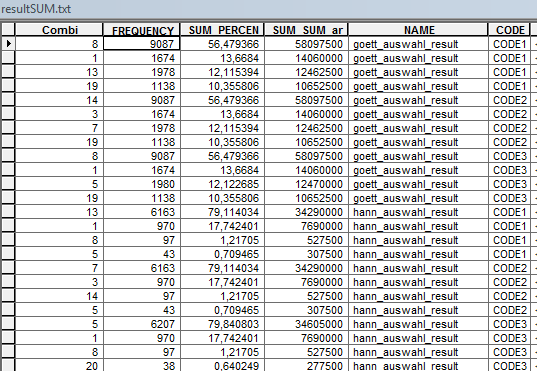
So to go back to the opening question I copied your code three times and therefore I got the three combinations. So the question is a kind of answered, I guess there is a faster way. At the moment I don’t know how to get my big table including the combinations. Should I ask this in a new post?
import arcpy
import os, sys
from arcpy import env
env.overwriteOutput = True
env.workspace = r"D:\Users\julia\erste_aufg\cities_UA"
env.qualifiedFieldNames = False
fcResult = arcpy.ListFeatureClasses("*_result.shp")
for shpresult in fcResult:
shpresultName = os.path.splitext (shpresult) [0]
print shpresultName
outputfile = env.workspace + "\\" + shpresultName + "0_.txt"
f = open (outputfile, 'w')
f.write ("ID,Combi,\n")
f.close ()
f = open (outputfile, 'a')
valueDict = {}
with arcpy.da.SearchCursor(shpresult, ["Id", "GRIDCODE"]) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
gridcode = searchRow[1]
if not keyValue in valueDict:
valueDict[keyValue] = [gridcode]
elif not gridcode in valueDict[keyValue]:
valueDict[keyValue].append(gridcode)
# sort both the ID value keys and the gridcodes which are converted to a string list
sortedDict = {}
for keyValue in sorted(valueDict.keys()):
items = ""
for item in sorted(valueDict[keyValue]):
if items == "":
items = str(item)
else:
items = items + ", " + str(item)
sortedDict[keyValue] = items
# write to text file with the code list enclosed inside double quotes.
for keyValue in sortedDict:
f.write(str(keyValue) + ',"' + sortedDict[keyValue] + '"\n' )
f.close()
#get combi2
outputfile2 = env.workspace + "\\" + shpresultName + "2_.txt"
f = open (outputfile2, 'w')
f.write ("ID,Combi,\n")
f.close ()
f = open (outputfile2, 'a')
valueDict = {}
with arcpy.da.SearchCursor(shpresult, ["Id", "GRIDCODE2"]) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
gridcode = searchRow[1]
if not keyValue in valueDict:
valueDict[keyValue] = [gridcode]
elif not gridcode in valueDict[keyValue]:
valueDict[keyValue].append(gridcode)
# sort both the ID value keys and the gridcodes which are converted to a string list
sortedDict = {}
for keyValue in sorted(valueDict.keys()):
items = ""
for item in sorted(valueDict[keyValue]):
if items == "":
items = str(item)
else:
items = items + ", " + str(item)
sortedDict[keyValue] = items
# write to text file with the code list enclosed inside double quotes.
for keyValue in sortedDict:
f.write(str(keyValue) + ',"' + sortedDict[keyValue] + '"\n' )
f.close()
#get combi3
outputfile3 = env.workspace + "\\" + shpresultName + "3_.txt"
f = open (outputfile3, 'w')
f.write ("ID,Combi,\n")
f.close ()
f = open (outputfile3, 'a')
valueDict = {}
with arcpy.da.SearchCursor(shpresult, ["Id", "GRIDCODE3"]) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
gridcode = searchRow[1]
if not keyValue in valueDict:
valueDict[keyValue] = [gridcode]
elif not gridcode in valueDict[keyValue]:
valueDict[keyValue].append(gridcode)
# sort both the ID value keys and the gridcodes which are converted to a string list
sortedDict = {}
for keyValue in sorted(valueDict.keys()):
items = ""
for item in sorted(valueDict[keyValue]):
if items == "":
items = str(item)
else:
items = items + ", " + str(item)
sortedDict[keyValue] = items
# write to text file with the code list enclosed inside double quotes.
for keyValue in sortedDict:
f.write(str(keyValue) + ',"' + sortedDict[keyValue] + '"\n' )
f.close()
#Execute TableToDBASE 3times
arcpy.TableToDBASE_conversion(outputfile, env.workspace)
arcpy.MakeTableView_management (outputfile, "outputfile_ly")
arcpy.TableToDBASE_conversion(outputfile2, env.workspace)
arcpy.MakeTableView_management (outputfile2, "outputfile2_ly")
arcpy.TableToDBASE_conversion(outputfile3, env.workspace)
arcpy.MakeTableView_management (outputfile3, "outputfile3_ly")
# get the percent of the sum area for each combi
outtable= shpresultName +"_outtable.dbf"
arcpy.Statistics_analysis(shpresult, outtable, [["area", "SUM"]], "Id")
outtableSUM= shpresultName + "_outtableSUM.dbf"
arcpy.Statistics_analysis(outtable, outtableSUM, [["SUM_area", "SUM"]])
with arcpy.da.SearchCursor(outtableSUM, "SUM_SUM_ar") as cursor:
for row in cursor:
print (int(row[0]))
fieldsum = (int(row[0]))
print fieldsum
arcpy.AddField_management(outtable, "PERCENT", "DOUBLE")
arcpy.CalculateField_management(outtable, "PERCENT", "([SUM_area]*100)/{}".format(fieldsum) , "VB")
arcpy.MakeTableView_management(outtable, "outtable_ly")
#add Join
arcpy.AddJoin_management ("outtable_ly", "Id", "outputfile_ly", "ID","KEEP_ALL")
outJoin= shpresultName +"_outJoin.dbf"
arcpy.CopyRows_management ("outtable_ly", outJoin)
# sum percent for unique combi
joinSum = shpresultName + "_joinSum.dbf"
arcpy.Statistics_analysis (outJoin, joinSum, [["PERCENT", "SUM"],["SUM_area", "SUM"]], "Combi")
inputtable= shpresultName +"_joinSum.dbf"
arcpy.MakeTableView_management (inputtable, "inputtable_ly")
outsort = shpresultName + "sort_sorted.dbf"
arcpy.Sort_management("inputtable_ly", outsort, [["SUM_PERCEN", "DESCENDING"]])
# new fields and create the name+codename
arcpy.AddField_management(outsort, "NAME", "TEXT")
arcpy.AddField_management(outsort, "CODE", "TEXT")
fields = ["NAME", "CODE"]
with arcpy.da.UpdateCursor(outsort, fields) as cursor:
for row in cursor:
row[0] = shpresultName
row[1] = "CODE1"
cursor.updateRow(row)
# get the percent: Combi2
outtable= shpresultName +"_outtable.dbf"
arcpy.Statistics_analysis(shpresult, outtable, [["area", "SUM"]], "Id")
outtableSUM= shpresultName + "_outtableSUM.dbf"
arcpy.Statistics_analysis(outtable, outtableSUM, [["SUM_area", "SUM"]])
with arcpy.da.SearchCursor(outtableSUM, "SUM_SUM_ar") as cursor:
for row in cursor:
print (int(row[0]))
fieldsum = (int(row[0]))
print fieldsum
arcpy.AddField_management(outtable, "PERCENT", "DOUBLE")
arcpy.CalculateField_management(outtable, "PERCENT", "([SUM_area]*100)/{}".format(fieldsum) , "VB")
arcpy.MakeTableView_management(outtable, "outtable_ly")
#add Join
arcpy.AddJoin_management ("outtable_ly", "Id", "outputfile2_ly", "ID","KEEP_ALL")
outJoin2= shpresultName +"_outJoin2.dbf"
arcpy.CopyRows_management ("outtable_ly", outJoin2)
# sum percent for unique combi
joinSum2 = shpresultName + "_joinSum2.dbf"
arcpy.Statistics_analysis (outJoin2, joinSum2, [["PERCENT", "SUM"],["SUM_area", "SUM"]], "Combi")
inputtable2= shpresultName +"_joinSum2.dbf"
arcpy.MakeTableView_management (inputtable2, "inputtable2_ly")
outsort2 = shpresultName + "sort_sorted2.dbf"
arcpy.Sort_management("inputtable2_ly", outsort2, [["SUM_PERCEN", "DESCENDING"]])
# new fields and create the name+codename
arcpy.AddField_management(outsort2, "NAME", "TEXT")
arcpy.AddField_management(outsort2, "CODE", "TEXT")
fields = ["NAME", "CODE"]
with arcpy.da.UpdateCursor(outsort2, fields) as cursor:
for row in cursor:
row[0] = shpresultName
row[1] = "CODE2"
cursor.updateRow(row)
# get the percent: Combi3
outtable= shpresultName +"_outtable.dbf"
arcpy.Statistics_analysis(shpresult, outtable, [["area", "SUM"]], "Id")
outtableSUM= shpresultName + "_outtableSUM.dbf"
arcpy.Statistics_analysis(outtable, outtableSUM, [["SUM_area", "SUM"]])
with arcpy.da.SearchCursor(outtableSUM, "SUM_SUM_ar") as cursor:
for row in cursor:
print (int(row[0]))
fieldsum = (int(row[0]))
print fieldsum
arcpy.AddField_management(outtable, "PERCENT", "DOUBLE")
arcpy.CalculateField_management(outtable, "PERCENT", "([SUM_area]*100)/{}".format(fieldsum) , "VB")
arcpy.MakeTableView_management(outtable, "outtable_ly")
#add Join
arcpy.AddJoin_management ("outtable_ly", "Id", "outputfile3_ly", "ID","KEEP_ALL")
outJoin3= shpresultName +"_outJoin3.dbf"
arcpy.CopyRows_management ("outtable_ly", outJoin3)
# sum percent for unique combi
joinSum3 = shpresultName + "_joinSum3.dbf"
arcpy.Statistics_analysis (outJoin3, joinSum3, [["PERCENT", "SUM"],["SUM_area", "SUM"]], "Combi")
inputtable3= shpresultName +"_joinSum3.dbf"
arcpy.MakeTableView_management (inputtable3, "inputtable3_ly")
outsort3 = shpresultName + "sort_sorted3.dbf"
arcpy.Sort_management("inputtable3_ly", outsort3, [["SUM_PERCEN", "DESCENDING"]])
# new fields and create the name+codename
arcpy.AddField_management(outsort3, "NAME", "TEXT")
arcpy.AddField_management(outsort3, "CODE", "TEXT")
fields = ["NAME", "CODE"]
with arcpy.da.UpdateCursor(outsort3, fields) as cursor:
for row in cursor:
row[0] = shpresultName
row[1] = "CODE3"
cursor.updateRow(row)
#new folder
# Set local variables
out_folder_path = env.workspace
out_name = "resultfolder"
# Execute CreateFolder
arcpy.CreateFolder_management(out_folder_path, out_name)
newpath= env.workspace + "\\" + out_name
resulttxt = newpath + "\\" + "resultSUM.txt"
f = open (resulttxt, 'w')
f.write ("Combi,FREQUENCY,SUM_PERCEN,SUM_SUM_ar,NAME,CODE,\n")
f.close ()
f = open (resulttxt, 'a')
fc_tables = arcpy.ListTables("*sort_sort*")
for tableR in fc_tables:
fieldsSe= ["Combi","FREQUENCY" ,"SUM_PERCEN" ,"SUM_SUM_ar", "NAME", "CODE"]
with arcpy.da.SearchCursor(tableR, fieldsSe, """"OID" < 4""") as sCursor:
for row in sCursor:
print row [0], row [1],row [2],row [3],row [4],row [5]
f.write(str(row[0]) + "," + str(row[1])+ "," +str(row[2]) + "," + str(row[3])+ "," +str(row[4])+ "," +str(row[5]) + "\n")
f.close()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I mean with the faster way just that I guess my code is not perfect, I’m totally fine with your solution and you helped me a lot with that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
with arcpy.Merge_management I'm able to create the big table.
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »