- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- How to calculate multiple equations (a+bX+cY+dZ), ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to calculate multiple equations (a+bX+cY+dZ), where (a, b, and c) are regression coeficients and (X, Y and Z) are rasters, using Pyton?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I need to run 252 equations to calculate freeze probability using lat, lon, and altitude as raster inputs, multiplied by a, b, c and d regression coeficients. The equations are in format a+b*lat+c*lon+d*alt.
The equations are in an Excel spreedsheet (attached) and I need to write them in a python script. The lat, lon and lat raster datasets are in the same folder and the output tif files have a standardized name (also in the Excel file).
Thank you!
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
dir(arcpy.da)
['Describe', 'Domain', 'Editor', 'ExtendTable', 'FeatureClassToNumPyArray', 'InsertCursor', 'ListDomains', 'ListFieldConflictFilters', 'ListReplicas', 'ListSubtypes', 'ListVersions', 'NumPyArrayToFeatureClass', 'NumPyArrayToTable', 'Replica', 'SearchCursor', 'TableToNumPyArray', 'UpdateCursor', 'Version', 'Walk', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_internal_eq', '_internal_sd', '_internal_vb']
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
good!
That leave your file location, and source
what is the actual path to your geodatabase table
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'd re-installed the ArcGis Pro 2.1.3 and the geodatabase path is "D:\Vianna\Dados\Raster\Clima\Raster_Clima.gdb". It still crashing whe running: arr = arcpy.da.TableToNumPyArray(tbl, "*").
I also tried to export the table as .txt to D:\Temp and used:
tbl = r"D:\Temp\TB_EQUAC_ETP.txt"
arr = arcpy.da.TableToNumPyArray(tbl, "*")This also crashes python.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Do you have null values in your records?
try adding … skip_nulls=True
TableToNumPyArray—Data Access module | ArcGIS Desktop
arr = arcpy.da.TableToNumPyArray(tbl, "*", skip_nulls=True)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The same problem....
With "*" and with:
import numpy as np
import arcpy
arcpy.CheckOutExtension("spatial")
arcpy.env.overwriteOutput = True
lat = np.arange(-29.373511, -25.928348, 0.000871310821466946, 'float')
lon = np.arange(-53.915588, -48.273851, 0.000871310821466947, 'float')
lon, lat = np.meshgrid(lon, lat)
alt = r"D:\Vianna\Dados\Raster\Topografia\mde_sc_90.tif"
tbl = r"D:\Vianna\Dados\Raster\Clima\Raster_Clima.gdb\TB_EQUAC_ETP"
fields=['SG_PREFIX','SG_SUFIX','SG_PERIO','SG_FORMA','VL_A','VL_B','VL_C','VL_D']
arr = arcpy.da.TableToNumPyArray(tbl, fields, skip_nulls=True)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Well nothing I have proposed has helped so I would suggest you contact Tech support
Good luck
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you, Dan!
Unfortunatly the Tech Support could not help me.
Congratulations for your blog!
Best regards!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi, Luiz
guess you should have a look at your gdb. Looks like all text fields in the tables are defined with a width of 2147483647.
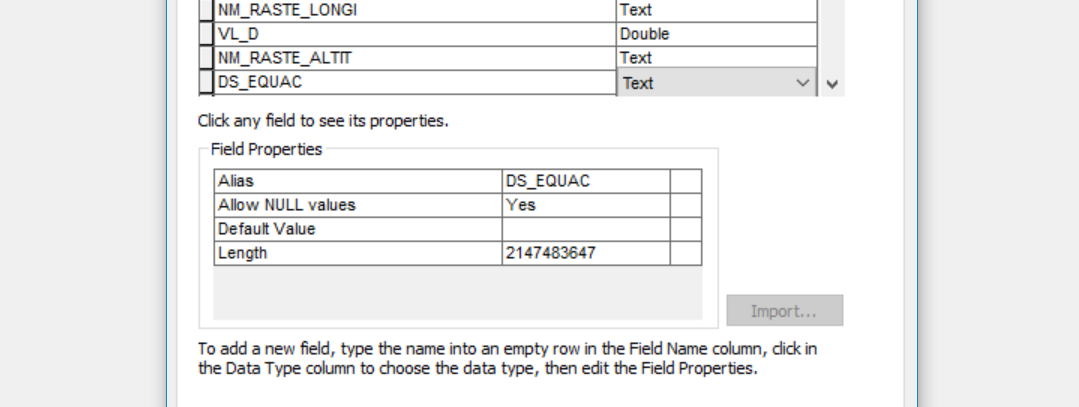
When converting to a numpy array all string fields will be converted to fields of the same width, and my guess is that numpy doesn't cope with eight <u2147483647 columns in the array.
Tested, and after moving your table to a new table with more moderate field widths the function works ok.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
strange, since the same data yielded …. '<U255' …. in the array for numpy 1.14.3 and numpy 1.15.1 and Pro from ver. 2.1 to 2.2.2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Is that what you got from converting the xlsx? I just looked at the gdb file he posted here.