- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- How do I use the minimum and maximum values from a...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How do I use the minimum and maximum values from a single column in python or VBscript?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
GEONET,
Essentially i want to normalize the Value field (VAL) in a series of point layers using an expression in python or VBscript. I have spent all morning browsing "The Web" for examples and all i can find are long expressions using the code block and that involves building a list of the values and selecting the highest or lowest.
The equation is (x-min(x))/(max(x)-min(x))....
In the python expression I tried FieldB = (!VAL! - min([!VAL!]))/(max([!VAL!])-min([!VAL!])) this returned
ERROR 000539: Error Running expression:(38.891808-min([38.891808]))/(max([38.891808]) etc...
It's reading the value from the field rather than the actual minimum which is 3.285462
I also tried FieldB = min([!VAL!]) and it returned the values for each record rather than actual minimum value in each record.
I would really love to have the ability to run a single expression on each of these layers rather than summarizing each individual table and then plugging the values in by hand. This requires going through each layer individually and this will be extremely time consuming and it seems like there should be a smarter way.
Any help on this is much appreciated!
Dan
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There is definitely a way to address this without resorting to plugging values in by hand. That being said, it isn't going to be a simple expression in Field Calculator that does it. Do you have a requirement to use Field Calculator? If so, I think "The Web" has already given you the answer(s).
The behavior you are seeing, at least the parts that aren't errors, are expected. Field Calculator operates like a cursor, at least logically. Field Calculator only sees one record at a time, even if it is operating over an entire set of records. The Codeblock section allows for a little bit of kung fu but we are talking Kung Fu Panda and not Caine. This is why your min and max functions are returning VAL instead of the min and max for the field. If you were looking at minimum or maximum values across fields for a given record, then the approach might work.
As Ian Grasshoff mentions, you could use the Summary Statistics tool. My rub with that tool, and why I seldom use it, is that it creates a table to place the values. The last thing I want is another table to extract values from and have to clean up afterwards.
As Johannes Bierer links to, you could use arcpy.da.TableToNumPyArrary to dump the table and find the minimum, maximum, or other statistics that way. My only concern with that approach, well all approaches involving lists, is that creating the lists can consume lots of memory depending on the data sets involved. Why create a list with a million elements if you only want to know the minimum and maximum values for the field.
Here is an example of a function you could create and then call from the Python interactive window:
def normalizeField(in_table, in_field, out_field):
with arcpy.da.SearchCursor(in_table, in_field) as cur:
x, = next(iter(cur))
minimum = maximum = x
for x, in cur:
if x < minimum:
minimum = x
if x > maximum:
maximum = x
with arcpy.da.UpdateCursor(in_table, [in_field, out_field]) as cur:
for x, y in cur:
y = (float(x) - minimum)/(maximum - minimum)
cur.updateRow([x,y])
The float with the UpdateCursor ensures the normalization value doesn't truncate to an integer if the in_field happens to be an integer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You could use several methods, the easiest one would be to use Summary Statistics Tool (Analysis Tools Toolbox -> Statistics -> Summary Statistics). The other option would be to use the dissolve tool (Data Management Tools -> Generalization -> Dissolve -> Pick your summary stats). To use the dissolve, you will need a uniform field to use as a dissolve value, ex. DISSOLVE_ID, every row equals 1 or 0 or something. Use that column to dissolve on, then choose your summary stats pointed to the field you want the min/max values for.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If you search for a python solution, have a look here:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There is definitely a way to address this without resorting to plugging values in by hand. That being said, it isn't going to be a simple expression in Field Calculator that does it. Do you have a requirement to use Field Calculator? If so, I think "The Web" has already given you the answer(s).
The behavior you are seeing, at least the parts that aren't errors, are expected. Field Calculator operates like a cursor, at least logically. Field Calculator only sees one record at a time, even if it is operating over an entire set of records. The Codeblock section allows for a little bit of kung fu but we are talking Kung Fu Panda and not Caine. This is why your min and max functions are returning VAL instead of the min and max for the field. If you were looking at minimum or maximum values across fields for a given record, then the approach might work.
As Ian Grasshoff mentions, you could use the Summary Statistics tool. My rub with that tool, and why I seldom use it, is that it creates a table to place the values. The last thing I want is another table to extract values from and have to clean up afterwards.
As Johannes Bierer links to, you could use arcpy.da.TableToNumPyArrary to dump the table and find the minimum, maximum, or other statistics that way. My only concern with that approach, well all approaches involving lists, is that creating the lists can consume lots of memory depending on the data sets involved. Why create a list with a million elements if you only want to know the minimum and maximum values for the field.
Here is an example of a function you could create and then call from the Python interactive window:
def normalizeField(in_table, in_field, out_field):
with arcpy.da.SearchCursor(in_table, in_field) as cur:
x, = next(iter(cur))
minimum = maximum = x
for x, in cur:
if x < minimum:
minimum = x
if x > maximum:
maximum = x
with arcpy.da.UpdateCursor(in_table, [in_field, out_field]) as cur:
for x, y in cur:
y = (float(x) - minimum)/(maximum - minimum)
cur.updateRow([x,y])
The float with the UpdateCursor ensures the normalization value doesn't truncate to an integer if the in_field happens to be an integer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Nice example Joshua Bixby, but maybe to make it a little shorter you can determine the min and max as follows:
def normalizeField(in_table, in_field, out_field):
lst = [r[0] for r in arcpy.da.SearchCursor(in_table, (in_field))]
minimum = min(lst)
maximum = max(lst)
# ect
Not sure how this affects performance though.
Kind regards, Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Xander Bakker, I agree the list-based example you provide is more succinct, not to mention will also work. The reason I went with a slightly more verbose iterator than a more succinct list comprehension was memory management. If one happens to be dealing with millions, tens of millions, or even more records, fully populating a list will impact memory and probably performance. That said, most users likely never deal with data sets large enough to see memory or performance differences between the two approaches..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You are absolutely right. Memory considerations should be taken into account.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Joshua,
Thank you for this great answer, and thank you Ian and Johannes as well.
I created this model as a workaround but it is cumbersome and has to be "Reset" each time.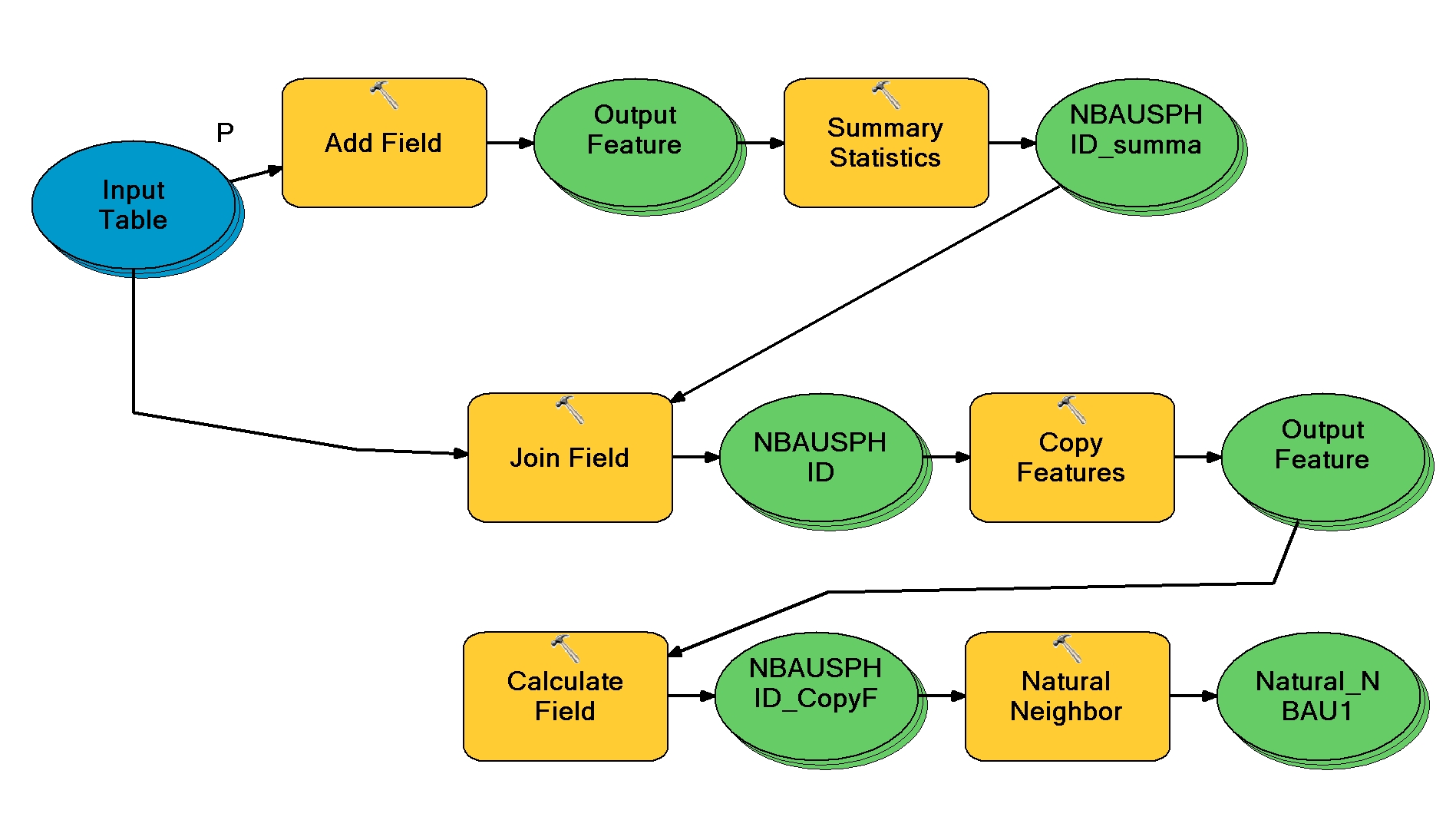
I also had to remove the natural neighbor because every time i tried to run the model it said the "Z value" field was missing even though i double checked the input and the field was there populated with the correct values. Not sure why this happened.
I copied your code into the Python Window, but when i call function I'm not clear on how to add the table, in field, and outfield. This is the results i'm getting. I understand the concept of the code but I'm missing the correct syntax.
>>> normalizeField('MSBNC_PHIN',!VAL!,!NORM!)
Parsing error <type 'exceptions.SyntaxError'>: invalid syntax (line 1)
>>> normalizeField('MSBNC_PHIN',[!VAL!],[!NORM!])
Parsing error <type 'exceptions.SyntaxError'>: invalid syntax (line 1)
>>> normalizeField('MSBNC_PHIN',(!VAL!),(!NORM!))
Parsing error <type 'exceptions.SyntaxError'>: invalid syntax (line 1)
>>> normalizeField
<function normalizeField at 0x1E98BFB0>
>>> normalizeField('MSBNC_PHIN',[!VAL!,!NORM!])
Parsing error <type 'exceptions.SyntaxError'>: invalid syntax (line 1)
Thanks Again!
Dan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I roughed out the example to run from the interactive Python window. I don't work with Model Builder much or at all, so I can't help much in terms of incorporating it into that workflow.
The function takes strings for all arguments. If VAL is the name of the field, use "VAL" with just quotes and no brackets or parentheses, same with NORM.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Joshua,
It recognized the table and fields, but then I got the following error:
>>> normalizeField('LSBC_PHID',"VAL","NORM")
Runtime error <type 'exceptions.AttributeError'>: 'module' object has no attribute 'da'
I imported Arcpy....forgot that as step 1....and then tried again. I then received this error:
Parsing error <type 'exceptions.SyntaxError'>: EOL while scanning string literal (line 1). I was missing a " before on of the field names...tried it again and received the error above again.
I had to set the variables so In_table = "c:\etc...." location of the table and then in_field="VAL", and out_field="NORM"
I also had to reverse the directions of all slash bars because Modelbuilder uses "/" and Windows Explorer uses "\".
After all this I was able to run the first code but I then received this error:
>>> normalizeField(in_table,in_field,out_field)
Runtime error <type 'exceptions.RuntimeError'>: ERROR 999999: Error executing function.
An invalid SQL statement was used.
An invalid SQL statement was used. [LSBC_PHID]
An invalid SQL statement was used. [SELECT * FROM LSBC_PHID WHERE ( VALTEST )]
I thought VAL may be a reserved word in arcpy or python so I changed the field name to "VALTEST" and I still got this error. LSBC_PHID is the name of the feature class with the table Ii'm using. Do I need to export it as a separate table?
I am running ArcMAP 10.0 with service pack 5 Build 4400.