- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Field calculator python script and OBJECTID or...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Field calculator python script and OBJECTID ordering issue
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Versioned SDE Geodatabase 10.2.2 / ArcMap 10.2.2 / Python27
I have a text field called FEATURE_UNIQUE_ID that consists of a 4 letter asset code and an increment number. I have added this field to several existing feature classes. To populate the field initially, I have a simple python script that I run in the field calculator (python codeblock) that assigns the value sequentially to the field. For example: WWTK101, WWTK102, Etc.
For the most part it works great. However, on some feature classes the number assignments start at an arbitrary value greater than that of the starting value assigned by the script. I cannot figure out why? I have tried editing as the data owner as well as geodatabase administrator. I have tried initializing rec to 100, to force the script to start at the value of 101. I have tried editing from the default version as well as running the script both before and after compressing / rebuilding indexes on those feature classes. I really need to figure out what is causing this issue, or I'm going to have to reorder these by hand -> not fun.
You will see in the screenshot below that in this particular feature class the numbering starts at 281 even though the OBJECTID starts at 1. The values are sequential, as in there are no values less than 281 in the column. they go from 281 up.
Any help is appreciated. please see below for screenshots and script code. Thanks.
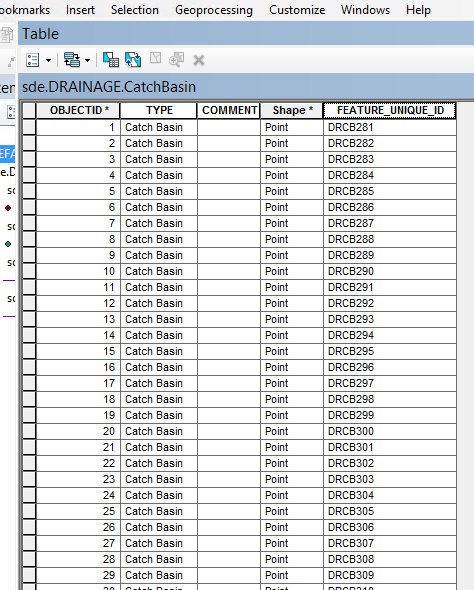
This code goes in the codeblock:
rec=0 strRec = "" def autos(): global rec, strRec pStart = 101 pInterval = 1 if (rec == 0): rec = pStart else: rec += pInterval strRec = "DRCB" + str(rec) return strRec
and the function autos() is called underneath. 90% of the feature classes I have used this on start numbering from 101 without issue.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just wondering... if you would run this script (do verify and change the settings on lines 6 - 10), does it still happen?
import os
import arcpy
def main():
# settings
ws = r"Database Connections/name of your connection.sde"
fc = os.path.join(ws, "DRAINAGE.CatchBasin")
fld_name = "FEATURE_UNIQUE_ID"
prefix = "DRCB"
start = 100
# Start an edit session. Must provide the worksapce.
edit = arcpy.da.Editor(ws)
# Edit session is started without an undo/redo stack for versioned data
# (for second argument, use False for unversioned data)
edit.startEditing(False, True)
# Start an edit operation
edit.startOperation()
# start update cursor
with arcpy.da.UpdateCursor(fc, (fld_name)) as curs:
for row in curs:
start += 1
row[0] = "{0}{1}".format(prefix, start)
curs.updateRow(row)
# Stop the edit operation.
edit.stopOperation()
# Stop the edit session and save the changes
edit.stopEditing(True)
if __name__ == '__main__':
main()BTW: if you don't want to run this script I understand, I was just wondering if the same behavior happens when using an update cursor. However, you could add a new field and change the setting on line 8 where the output field is listed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Is there a specific reason why the numbering should start with 101 (something to do with the number being 3 digits large perhaps)? If so this can be managed using formatting leading zero's as explained in Some Python Snippets .
Would this have to do with it being a versioned database, and looking at a version makes it skip some records but does count them?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The numbering doesn't really have to start from 101, it's just been requested. I'm more concerned with why it happens on just some feature classes. The fact that it is versioned hasn't caused it to skip any yet when doing the field calculator. so far they are all sequential (even if they don't start from 101 as I want). I have run into the versioning skip issue with some insert triggers, but not here. It's not really a mission critical issue, I just want to understand why it's happening. I appreciate your reply!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just wondering... if you would run this script (do verify and change the settings on lines 6 - 10), does it still happen?
import os
import arcpy
def main():
# settings
ws = r"Database Connections/name of your connection.sde"
fc = os.path.join(ws, "DRAINAGE.CatchBasin")
fld_name = "FEATURE_UNIQUE_ID"
prefix = "DRCB"
start = 100
# Start an edit session. Must provide the worksapce.
edit = arcpy.da.Editor(ws)
# Edit session is started without an undo/redo stack for versioned data
# (for second argument, use False for unversioned data)
edit.startEditing(False, True)
# Start an edit operation
edit.startOperation()
# start update cursor
with arcpy.da.UpdateCursor(fc, (fld_name)) as curs:
for row in curs:
start += 1
row[0] = "{0}{1}".format(prefix, start)
curs.updateRow(row)
# Stop the edit operation.
edit.stopOperation()
# Stop the edit session and save the changes
edit.stopEditing(True)
if __name__ == '__main__':
main()BTW: if you don't want to run this script I understand, I was just wondering if the same behavior happens when using an update cursor. However, you could add a new field and change the setting on line 8 where the output field is listed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'll run it...give me one minute...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I stand corrected. The update cursor did in fact work. Thank you guys!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Have you done any explicit sorting before running the field calculator? For example, have you sorted the OBJECTID field first and then run the code?
My other suggestion was going to be using an update cursor as Xander Bakker has suggested and provided code for already.