- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- DeleteRows error - incompatible with field type.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
DeleteRows error - incompatible with field type.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a script that runs regularly to update a Feature layer on our Enterprise server. I have started to get the following error when I am calling
arcpy.management.DeleteRows(in_rows="url to feature layer") ExecuteError: ERROR 160117: The value type is incompatible with the field type.
Failed to execute (DeleteRows)
The workflow is that I have a grid polygon which I join to a spreadsheet and symbolise on a 'status' attribute of the table, then I update the existing Feature layer (which is used in a Dashboard) by deleting the rows in the existing Feature layer & then calling arcpy.management.Append() . I am doing this for two other grids sizes without issue.
Any suggestions for why I am suddenly getting this error? I have tired overwriting the web layer from within ArcPro and then trying again with no luck. Full script below.
I am also happy to receive any suggestions to improve my workflow as I am not sure this is the best way to do it in the first place....
# Set your workspace
arcpy.env.workspace = r"path to gdb on server.gdb"
def stripwhitespaces(table_name):
"""function for stripping whitespace from all string columns in a table, table name passed as input"""
fieldlist=[i.name for i in arcpy.ListFields(table_name) if i.type=='String']
with arcpy.da.UpdateCursor(table_name,fieldlist) as cursor:
for row in cursor:
row=[i.strip() if i is not None else None for i in row]
cursor.updateRow(row)
def delete_rows(table, clause):
"""Deleted rows from specified table or feature class where conditions in where clause are TRUE"""
arcpy.management.SelectLayerByAttribute(
in_layer_or_view=table,
selection_type="NEW_SELECTION",
where_clause=clause,
invert_where_clause=None
)
arcpy.management.DeleteRows(
in_rows=table
)
# Step 1: Read the spreadsheet
spreadsheet_path = r"path to spreadsheet on server.xlsx"
spreadsheet_layer = "Work Order Tracker"
output_table = "worktracker"
arcpy.ExcelToTable_conversion(spreadsheet_path, output_table, spreadsheet_layer, field_names_row=2)
stripwhitespaces("worktracker")
# create & format the Band 3 table ready to join
input_table = "worktracker"
output_table = "band3table"
# Specify the fields you want to keep
selected_fields = ["name", "progress", "a", "b", "c"]
# Create a NumPy array for the selected fields
table_array = arcpy.da.TableToNumPyArray(input_table, selected_fields)
# Convert empty strings to None
table_array = np.where(table_array == '', None, table_array)
# Create a new file geodatabase table
arcpy.CreateTable_management(arcpy.env.workspace, output_table)
# Add fields to the new table based on the selected fields
for field in selected_fields:
arcpy.AddField_management(output_table, field, 'TEXT') # Assuming all fields are text, adjust if needed
# Create an InsertCursor to insert rows into the new table
with arcpy.da.InsertCursor(output_table, selected_fields) as cursor:
for row in table_array:
cursor.insertRow(row)
# delete blank rows from table
arcpy.management.SelectLayerByAttribute(
in_layer_or_view="band3table",
selection_type="NEW_SELECTION",
where_clause="name NOT LIKE 'GB%'",
invert_where_clause=None
)
arcpy.management.DeleteRows(
in_rows="band3table"
)
# copy the grid schema shapefile before joining to keep a clean original.
arcpy.management.CopyFeatures('grid saved in .gdb name', 'band3')
# join to spreadsheet values
arcpy.JoinField_management("band3", "Name", "band3table", "name")
#deleting all cells from the feature class where the progress is Null
arcpy.management.SelectLayerByAttribute(
in_layer_or_view="band3",
selection_type="NEW_SELECTION",
where_clause="progress IS NULL",
invert_where_clause=None
)
arcpy.management.DeleteRows(
in_rows="band3"
)
#delete columns that are not needed post join
arcpy.DeleteField_management("band3",
["id", "name"])
#apply symbology
arcpy.management.ApplySymbologyFromLayer(
in_layer="band3",
in_symbology_layer=r"path to layer file on server.lyrx",
symbology_fields="VALUE_FIELD progress progress",
update_symbology="MAINTAIN"
)
arcpy.management.DeleteRows(
in_rows="url to Feature layer on Enterprise server"
)
#append rows
arcpy.management.Append(
inputs=r"path to band3 in geodatabase on server",
target="url to Feature layer on Enterprise server",
schema_type="TEST",
field_mapping=None,
subtype="",
expression="",
match_fields=None,
update_geometry="NOT_UPDATE_GEOMETRY"
)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you @JakeSkinner . I tried that using
arcpy.TruncateTable_management("https://enterpriseaddress/server/rest/services/Hosted/Band_3_live/FeatureServer/0")and got the following error:
ExecuteError: ERROR 001260: Operation not supported on table L0band3.
Failed to execute (TruncateTable)
Is there a better workflow for updating a Feature service with data that requires a geospatial join? what I am doing feels a bit hacky (although it has been working up to now!)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
How many fields are you updating in the feature service?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
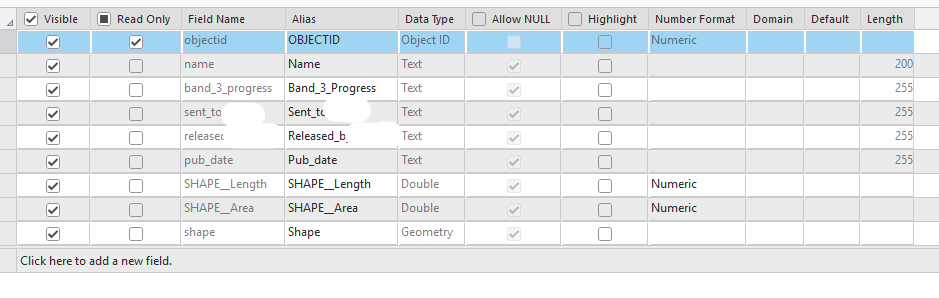
Another option I use a lot is updating the feature service using a dictionary and an update cursor, rather than a join. Below is an example:
# Create dictionary
print("Create dictionary")
tblDict = {}
with arcpy.da.SearchCursor(tbl, ["name","band_3_progress", "sent_to", "released_by", "pub_date"]) as cursor:
for row in cursor:
tblDict.setdefault(row[0], [])
tblDict[row[0]].append(row[1])
tblDict[row[0]].append(row[2])
tblDict[row[0]].append(row[3])
tblDict[row[0]].append(row[4])
del cursor
# Update feature service
print("Updating feature service")
with arcpy.da.UpdateCursor(fsURL, ["name","band_3_progress", "sent_to", "released_by", "pub_date"]) as cursor:
for row in cursor:
row[1] = tblDict[row[0]][0]
row[2] = tblDict[row[0]][1]
row[3] = tblDict[row[0]][2]
row[4] = tblDict[row[0]][3]
cursor.updateRow(row)
del cursor