- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- data drive mulitple data frames
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've got a table with IDs and each ID could have 1-3 point locations (lat,lon). I'd like to create a PDF with one page for each ID, and each of the 3 data frames centered on the associated points.
I have reasonable Esri related python experience, but haven't done much with arcpy.mapping. Any start with creating the PDF, cycling through the IDs to add a page to the PDF, and then centering each data frame would be so much appreciated. Or perhaps I'll get lucky, and someone has done this exactly.
Below is an example of the data (could be in excel or a GeoDB table), and an example of one page of the PDF.
Thanks in advance,
S. Roberts
either one of these two table formats could be created:
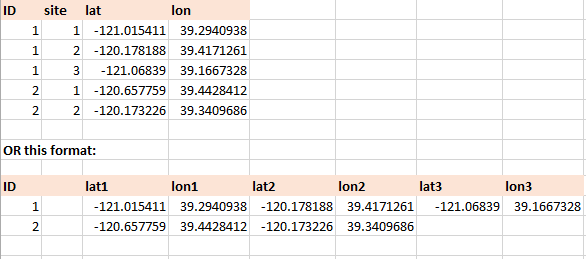
Each PDF page would look like this:
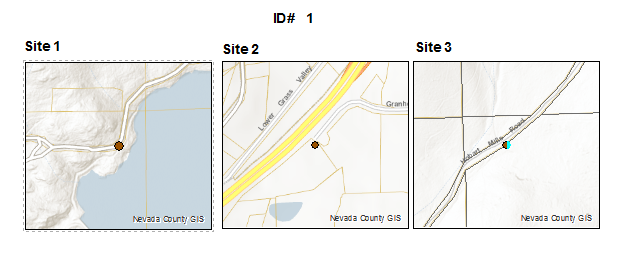
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Freddie,
Thanks for getting me on the right road. I ended up not using Data Driven Pages, but did use your suggestion of putting all the data in one row and just panning data frames. This tool from the Map Automation Team was useful too.
In any case, here is the script that I came up with. It assumes an mxd with a title text element and 3 data frames that are in geographic projection WGS84. Also data in the 1 row format as shown in the screen shot above (although it doesn't help to have the lat and lon reversed - a bit embarrassed about that).
#assumes fields named ID, Lat1, Lon1, Lat2, Lon2, Lat3, Lon3, etc for each data frame
#assumes an mxd with a "titleField" text element and a "no data" text element over each dataframe
#data frames must be in Geographic WGS84
import arcpy, os
idField = "ID"
pageTitleFieldName = "CardTitle" #This is the name of the text element at the top of page that should be populated with the ID
in_features = r"H:\Test.gdb\TestData"
mxd = arcpy.mapping.MapDocument(r"H:\Test.mxd")
outputPDF = "H:\TestFinalPDF.pdf"
tmpPDF = "H:\Temp.pdf"
outresolution = 300
outQuality = "NORMAL"
if arcpy.Exists(outputPDF):
arcpy.Delete_management(outputPDF)
finalPDF = arcpy.mapping.PDFDocumentCreate(outputPDF)
pageLayoutCursor = arcpy.SearchCursor(in_features)
for row in pageLayoutCursor:
titleTxt = arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT", pageTitleFieldName)[0]
titleTxt.text = row.getValue(idField)
dfNum = 1
for df in arcpy.mapping.ListDataFrames(mxd):
newExtent = df.extent
if row.getValue("Lat" + str(dfNum)) is not None and row.getValue("Lon" + str(dfNum)) is not None:
newExtent.XMin = row.getValue("Lon" + str(dfNum)) - 0.002
newExtent.YMin = row.getValue("Lat" + str(dfNum)) - 0.002
newExtent.XMax = row.getValue("Lon" + str(dfNum)) + 0.002
newExtent.YMax = row.getValue("Lat" + str(dfNum)) + 0.002
df.extent = newExtent
else:
#this is just my way of zooming the frame to a no data area. You could move the frame off the map too
newExtent.XMin = 37
newExtent.YMin = 37.01
newExtent.XMax = -123
newExtent.YMax = -123.01
df.extent = newExtent
dfNum = dfNum + 1
arcpy.mapping.ExportToPDF(mxd, tmpPDF,"PAGE_LAYOUT",0,0,outresolution,outQuality,)
finalPDF.appendPages(tmpPDF)
del mxd
finalPDF.updateDocProperties(pdf_open_view="USE_THUMBS", pdf_layout="SINGLE_PAGE")
finalPDF.saveAndClose()
del finalPDF
if arcpy.Exists(tmpPDF):
arcpy.Delete_management(tmpPDF)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I can't think of a sample off the top of my head that would show exactly what you're wanting, but I can point you to a couple of pages that would help you put this together.
Exporting Data Driven Pages
http://desktop.arcgis.com/en/desktop/latest/map/page-layouts/exporting-data-driven-pages.htm
Start by checking out the example at the bottom of the above page. You'll see in this example that they're using python to iterate through each data driven page and export it to a single png image. You'd do something similar to export each page to a PDF.
Within the iteration logic of the above step, you'll want to pull sites from the Row object returned from the pageRow object of the DataDrivenPages class.
DataDrivenPages class
http://desktop.arcgis.com/en/desktop/latest/analyze/arcpy-mapping/datadrivenpages-class.htm
If you put all of your coordinates within the same row you could parse them from the row object and then you'd use the panToExtent or zoomToSelectedFeatures method of the DataFrame class to move your additional dataframes to the needed location. Note: The selection approach would require that you select the geometry within the map, zoom to it, and clear the selection. If you have your data in different rows you can just create a search cursor against the feature class and use the site id as a filter.
DataFrame class
http://desktop.arcgis.com/en/desktop/latest/analyze/arcpy-mapping/dataframe-class.htm
Accessing data using cursors
http://desktop.arcgis.com/en/desktop/latest/analyze/python/data-access-using-cursors.htm
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Freddie,
Thanks for getting me on the right road. I ended up not using Data Driven Pages, but did use your suggestion of putting all the data in one row and just panning data frames. This tool from the Map Automation Team was useful too.
In any case, here is the script that I came up with. It assumes an mxd with a title text element and 3 data frames that are in geographic projection WGS84. Also data in the 1 row format as shown in the screen shot above (although it doesn't help to have the lat and lon reversed - a bit embarrassed about that).
#assumes fields named ID, Lat1, Lon1, Lat2, Lon2, Lat3, Lon3, etc for each data frame
#assumes an mxd with a "titleField" text element and a "no data" text element over each dataframe
#data frames must be in Geographic WGS84
import arcpy, os
idField = "ID"
pageTitleFieldName = "CardTitle" #This is the name of the text element at the top of page that should be populated with the ID
in_features = r"H:\Test.gdb\TestData"
mxd = arcpy.mapping.MapDocument(r"H:\Test.mxd")
outputPDF = "H:\TestFinalPDF.pdf"
tmpPDF = "H:\Temp.pdf"
outresolution = 300
outQuality = "NORMAL"
if arcpy.Exists(outputPDF):
arcpy.Delete_management(outputPDF)
finalPDF = arcpy.mapping.PDFDocumentCreate(outputPDF)
pageLayoutCursor = arcpy.SearchCursor(in_features)
for row in pageLayoutCursor:
titleTxt = arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT", pageTitleFieldName)[0]
titleTxt.text = row.getValue(idField)
dfNum = 1
for df in arcpy.mapping.ListDataFrames(mxd):
newExtent = df.extent
if row.getValue("Lat" + str(dfNum)) is not None and row.getValue("Lon" + str(dfNum)) is not None:
newExtent.XMin = row.getValue("Lon" + str(dfNum)) - 0.002
newExtent.YMin = row.getValue("Lat" + str(dfNum)) - 0.002
newExtent.XMax = row.getValue("Lon" + str(dfNum)) + 0.002
newExtent.YMax = row.getValue("Lat" + str(dfNum)) + 0.002
df.extent = newExtent
else:
#this is just my way of zooming the frame to a no data area. You could move the frame off the map too
newExtent.XMin = 37
newExtent.YMin = 37.01
newExtent.XMax = -123
newExtent.YMax = -123.01
df.extent = newExtent
dfNum = dfNum + 1
arcpy.mapping.ExportToPDF(mxd, tmpPDF,"PAGE_LAYOUT",0,0,outresolution,outQuality,)
finalPDF.appendPages(tmpPDF)
del mxd
finalPDF.updateDocProperties(pdf_open_view="USE_THUMBS", pdf_layout="SINGLE_PAGE")
finalPDF.saveAndClose()
del finalPDF
if arcpy.Exists(tmpPDF):
arcpy.Delete_management(tmpPDF)