- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Compare records from two tables/feature classes
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Compare records from two tables/feature classes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I know there are several similar threads here related to this, but there are some additional details I'd like to get feedback/insight on.
Background: I have 2 feature classes. One is a FC of polygons which represent areas of different forest activity, and these areas can be associated as groups based on a unique identifier [i.e. polygons are organized into groups; each group has a unique value]. The other FC contains dissolved polygons based on each group and contains the unique group identifier as an attribute. Therefore, these FCs have a 1:N relationship.
Objective: Automate the update process (select>dissolve>append) of the second feature class.
Discussion: A simple option here would be to simply delete all records in the 2nd FC and repopulate based on a fresh dissolve process at some interval; there are only ~20k records here so it's not that big of a deal. I'm hoping to find a more elegant solution here (with logic that I can then apply to other processes).
One alternative I've read about is building a dictionary from the source FC and then evaluate the target FC. The closest example I've found is here.
Questions: Could anyone comment on the general logic here based on what I'm trying to achieve? Any alternative ideas jump out at you? Most of the script in the other thread I understand, but at the moment I'm not really solid how to implement the evaluation process I need in the cursor.
Thanks in advance for any insight you might have!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have not found a good way to do this without assigning unique IDs to the undissolved polygons and creating a duplicate of all of those features during each dissolve cycle and comparing changes in the undissolved feature class to the last copy. Then you can use the ID to do a full comparison of the feature set to detect the creation of new features, the deletion of old features, changes to the areas or perimeters of each undissolved feature indicating geometry changes, and changes to any attributes that would affect the dissolve.
Since features can overlap (bad topology, intentional overlaps) you cannot just add the areas of the undissolved feature class and compare it to the area of the dissolved features to decide if they are different or the same. Any processing that involves geometry manipulation using cursors is too slow to do any other meaningful comparisons between undissolved and dissolved shapes. You are better off just redissolving if that is your only option.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard, sorry it took me a couple days to get back to you. I was thinking about this more from a tabular perspective. I'll try to illustrate here.
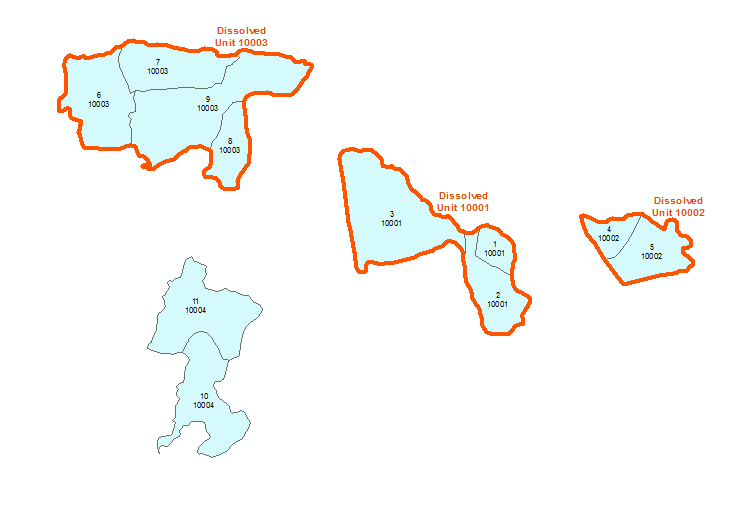
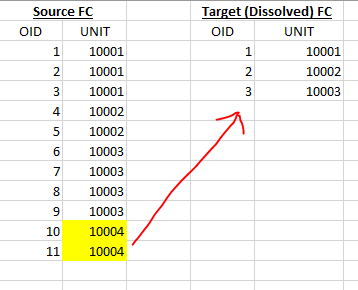
So here we can see that the unit 10004 doesn't exist in the target/dissolved FC. Hopefully this better describes the issue at hand.
I very much appreciate your or any one else's insight!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If the only changes ever made to your Source FC were the addition of new UNITs that completely did not exist in the Dissolve feature set or the complete removal of UNITs from the Source FC that need to be deleted from the Dissolve FC, then you can write an efficient script to detect those changes just by comparing the UNIT values in the two FCs. But everyone does edits that trigger more than just additions and deletion of features in a derivative FC. They do edits that trigger partial changes to features that already exist in their derivative FC. I have never seen a dataset with more than 1000 features that only makes edits in the Source FC that would create and destroy derivative features and never cause any existing derivative features to be partially changed.
Any edits that cause partial changes in already existing derivative features cannot be detected by comparing a source FC with a derivative FC without completely redoing the operation that created the derivative. You can only detect those changes at a tabular level if you have a changes table that tracks each edit as it happens, like versioning does in SDE, or if you have a copy of the version of the Source FC that existed before any edits were made. The only other approach would be to use Attribute Assistant to date stamp all geometry and attribute changes in a field in the Source FC as edits are being made and to also have a date field in the Dissolve FC showing the last time the dissolved features were edited. Then you could write a script to compare the UNIT values and the dates to determine the set of Source FC features that needed to be redissolved. However, this approach would still not detect the complete removal of a feature in the Source FC. To detect that your Dissolve FC would have to also include a Frequency/Source Feature Count field so that you could compare the counts of features in the Source FC to the count of features that made up the last dissolve for a given UNIT.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard, I see the concerns you highlight regarding data integrity. The purpose of the dissolved FC is primarily to facilitate querying and labeling...a locator if you will. The majority of the time it will simply adding records.
As to comparing the UNIT values as you suggest, I'm having a bit of a time dissecting the search cursor provided in thread which I linked to. Would you suggest another way to go about that comparison?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi there.
I was able to modify the code that Xander Bakker provided in this thread so that new units in the source feature class were dissolve and then appended to the target feature class.