- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Calculate field values using arcpy.da.UpdateCu...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Calculate field values using arcpy.da.UpdateCursor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am trying to create and update a field with a count of line features (tLayer) within a distance of point features (sLayer). I am attempting to use a combination of AddField_management, arcpy.da.SearchCursor, SelectLayerByLocation_management, arcpy.GetCount_management, and arcpy.da.UpdateCursor. The code I have for this is currently updating all records for the Line_Count field with the count of the point features (i.e. 2) for only the (second?) record. Though, a print statement following the GetCount line will return the line count for all of the point features (with a few unessential iterations).
What do I need to do to appropriately update the Line_Count field for all of the records? Also, this process will be applied to a large dataset and will be extended to include 'where clauses'; are there any suggestions as to how to make this as efficient as possible. Any tips or suggestions would be helpful.
Thanks in advance!
Tess
Updated Line_count Field (inaccurately recording a count of '2' for each record) :
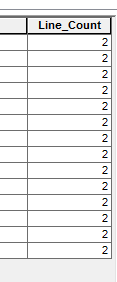
actual line count values for records as returned by print statement:
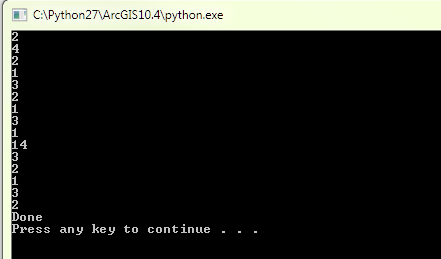
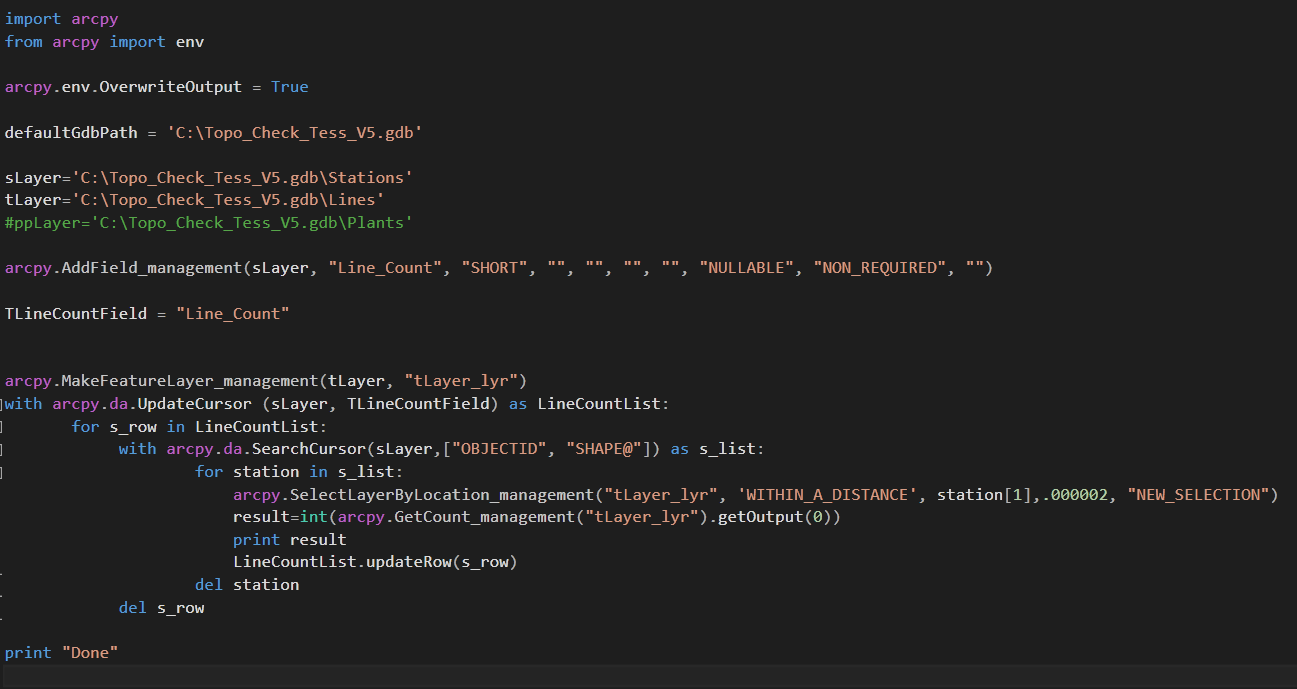
import arcpy
from arcpy import env
arcpy.env.OverwriteOutput = True
defaultGdbPath = 'C:\Topo_Check_Tess_V5.gdb'
sLayer='C:\Topo_Check_Tess_V5.gdb\Stations'
tLayer='C:\Topo_Check_Tess_V5.gdb\Lines'
#ppLayer='C:\Topo_Check_Tess_V5.gdb\Plants'
arcpy.AddField_management(sLayer, "Line_Count", "SHORT", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
TLineCountField = "Line_Count"
arcpy.MakeFeatureLayer_management(tLayer, "tLayer_lyr")
with arcpy.da.UpdateCursor (sLayer, TLineCountField) as LineCountList:
for s_row in LineCountList:
with arcpy.da.SearchCursor(sLayer,["OBJECTID", "SHAPE@"]) as s_list:
for station in s_list:
arcpy.SelectLayerByLocation_management("tLayer_lyr", 'WITHIN_A_DISTANCE', station[1],.000002, "NEW_SELECTION")
result=int(arcpy.GetCount_management("tLayer_lyr").getOutput(0))
print result
LineCountList.updateRow(s_row)
del station
del s_row
print "Done"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
some severe indentation problems after the... for station in s_list: ... I thought it was just the code pasted above but it also exists in your image. A lot of people are having issues lately with mixing cursors as well... you might want to check those out in the python place
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Speaking of what Dan said regarding the indentation issues, what IDE are you using to write your scripts? You may want to consider one like PyScripter or PyCharm that will indicate when there are errors like indentation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Well, here we have another embedded update with a search cursor on the same feature.
I don't think this is the correct approach. First read the data into a dictionary (as per other posts rfairhur24)
Then do the updates.
You are also deleting s_row within the inner loop, so what will the inner loop do with the updateRow without this object?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink

Thanks, I missed that one too. The formatting ended up getting pretty messed up btw Notepad ++ and Visual Studio and I was terrible about fixing it. I do have a lot of work to do as far as understanding loops and multiple cursors (and probably everything else). I'll check out Richard's posts. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As much as I like scripting Python, sometimes the best tool for the job is a pre-existing geoprocessing tool. Have you looked at Generate Near Table? Not only could you determine the counts of nearby features, you could determine a lot of other information about those features as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This process was initially built off of a Model Builder model (for simplicity), namely using a bunch of spatial joins; though as the data set is so large, I am trying to redo the process with an object oriented script for more efficient computation and use. This count generation will be the first step of many within the new script.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So I think it is only printing the last row in 'result' for the Line_Count update statement. Is there an efficient way for result (i.e. result=int(arcpy.GetCount_management("tLayer_lyr").getOutput(0)) ) to be saved as a list or an array that can be written to the Line_Count field?
Thanks again,
Tess
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A post in GIS Stack Exchange provided a solution for this as well as some additional useful comments. Though, as this script will be applied to large data sets where efficiency will be a necessity, I will need to look into wrapping in more geoprocessing tools (i.e. near table, frequency table, and others) into this process.
Thanks for all the great feedback!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm just going to reiterate what Neil said and recommend you check Richard's blog post about cursors and dictionaries(though he accidently tagged Richard and his page instead of that particular blog post).